Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMisclassification cost-sensitive ensemble learning: A unifying framework
Paper and Code
Jul 14, 2020

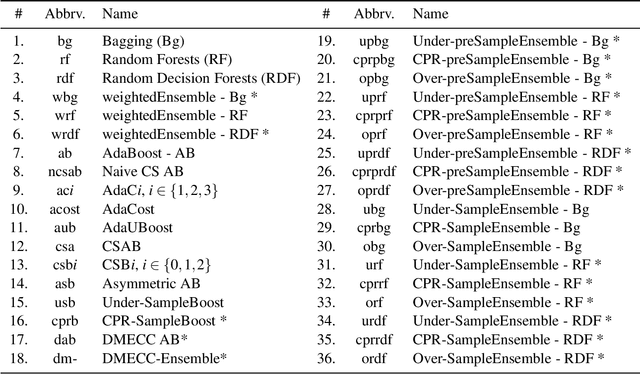

Over the years, a plethora of cost-sensitive methods have been proposed for learning on data when different types of misclassification errors incur different costs. Our contribution is a unifying framework that provides a comprehensive and insightful overview on cost-sensitive ensemble methods, pinpointing their differences and similarities via a fine-grained categorization. Our framework contains natural extensions and generalisations of ideas across methods, be it AdaBoost, Bagging or Random Forest, and as a result not only yields all methods known to date but also some not previously considered.
View paper on