 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScenario theory for multi-criteria data-driven decision making
Apr 01, 2026The scenario approach provides a powerful data-driven framework for designing solutions under uncertainty with rigorous probabilistic robustness guarantees. Existing theory, however, primarily addresses assessing robustness with respect to a single appropriateness criterion for the solution based on a dataset, whereas many practical applications - including multi-agent decision problems - require the simultaneous consideration of multiple criteria and the assessment of their robustness based on multiple datasets, one per criterion. This paper develops a general scenario theory for multi-criteria data-driven decision making. A central innovation lies in the collective treatment of the risks associated with violations of individual criteria, which yields substantially more accurate robustness certificates than those derived from a naive application of standard results. In turn, this approach enables a sharper quantification of the robustness level with which all criteria are simultaneously satisfied. The proposed framework applies broadly to multi-criteria data-driven decision problems, providing a principled, scalable, and theoretically grounded methodology for design under uncertainty.
Finite sample learning of moving targets
Aug 08, 2024We consider a moving target that we seek to learn from samples. Our results extend randomized techniques developed in control and optimization for a constant target to the case where the target is changing. We derive a novel bound on the number of samples that are required to construct a probably approximately correct (PAC) estimate of the target. Furthermore, when the moving target is a convex polytope, we provide a constructive method of generating the PAC estimate using a mixed integer linear program (MILP). The proposed method is demonstrated on an application to autonomous emergency braking.
Sampling-based optimal kinodynamic planning with motion primitives
Sep 07, 2018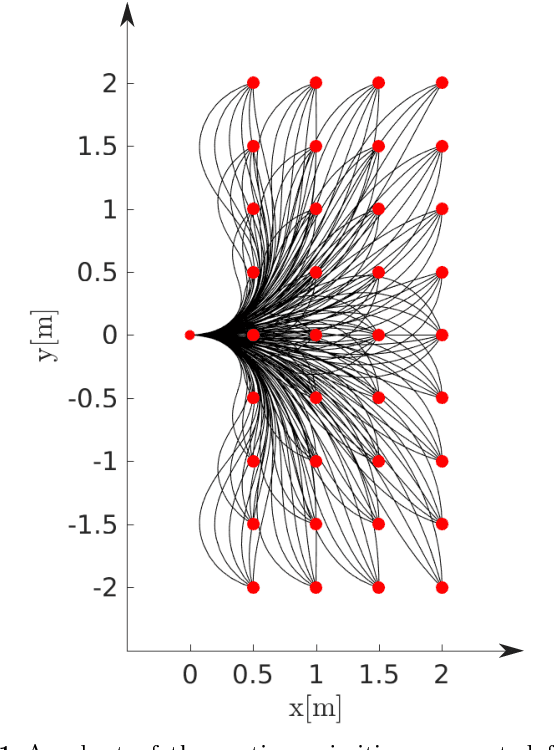
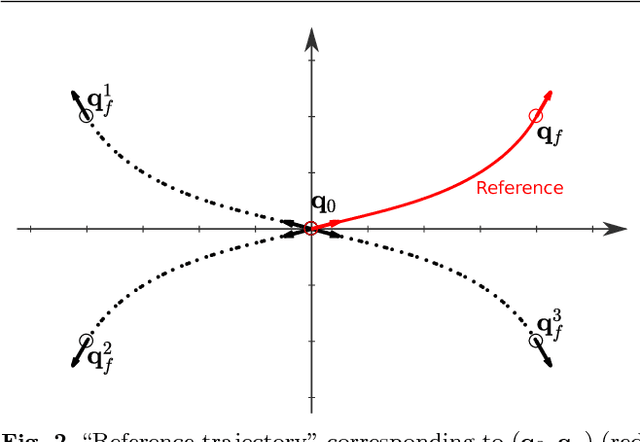
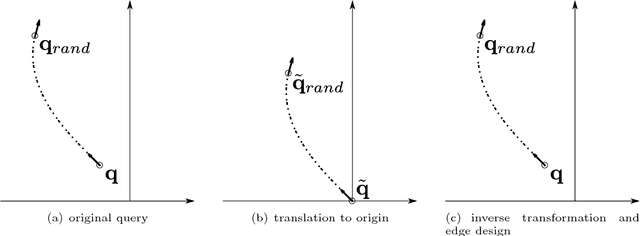
This paper proposes a novel sampling-based motion planner, which integrates in RRT* (Rapidly exploring Random Tree star) a database of pre-computed motion primitives to alleviate its computational load and allow for motion planning in a dynamic or partially known environment. The database is built by considering a set of initial and final state pairs in some grid space, and determining for each pair an optimal trajectory that is compatible with the system dynamics and constraints, while minimizing a cost. Nodes are progressively added to the tree {of feasible trajectories in the RRT* by extracting at random a sample in the gridded state space and selecting the best obstacle-free motion primitive in the database that joins it to an existing node. The tree is rewired if some nodes can be reached from the new sampled state through an obstacle-free motion primitive with lower cost. The computationally more intensive part of motion planning is thus moved to the preliminary offline phase of the database construction at the price of some performance degradation due to gridding. Grid resolution can be tuned so as to compromise between (sub)optimality and size of the database. The planner is shown to be asymptotically optimal as the grid resolution goes to zero and the number of sampled states grows to infinity.
Randomised Algorithm for Feature Selection and Classification
Jul 28, 2016
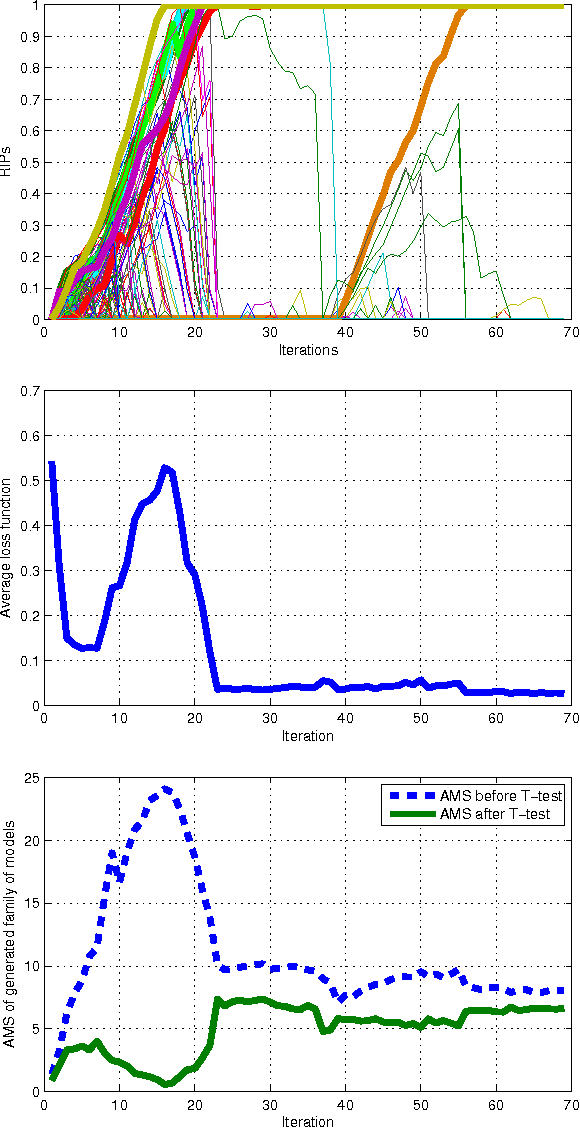


We here introduce a novel classification approach adopted from the nonlinear model identification framework, which jointly addresses the feature selection and classifier design tasks. The classifier is constructed as a polynomial expansion of the original attributes and a model structure selection process is applied to find the relevant terms of the model. The selection method progressively refines a probability distribution defined on the model structure space, by extracting sample models from the current distribution and using the aggregate information obtained from the evaluation of the population of models to reinforce the probability of extracting the most important terms. To reduce the initial search space, distance correlation filtering can be applied as a preprocessing technique. The proposed method is evaluated and compared to other well-known feature selection and classification methods on standard benchmark classification problems. The results show the effectiveness of the proposed method with respect to competitor methods both in terms of classification accuracy and model complexity. The obtained models have a simple structure, easily amenable to interpretation and analysis.