 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomised Algorithm for Feature Selection and Classification
Jul 28, 2016
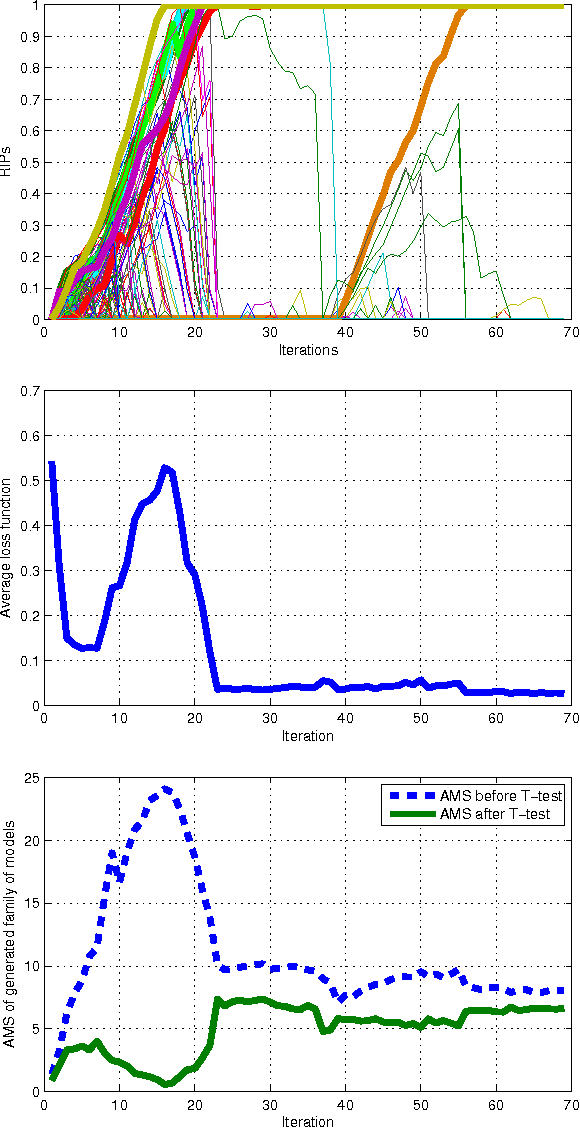


We here introduce a novel classification approach adopted from the nonlinear model identification framework, which jointly addresses the feature selection and classifier design tasks. The classifier is constructed as a polynomial expansion of the original attributes and a model structure selection process is applied to find the relevant terms of the model. The selection method progressively refines a probability distribution defined on the model structure space, by extracting sample models from the current distribution and using the aggregate information obtained from the evaluation of the population of models to reinforce the probability of extracting the most important terms. To reduce the initial search space, distance correlation filtering can be applied as a preprocessing technique. The proposed method is evaluated and compared to other well-known feature selection and classification methods on standard benchmark classification problems. The results show the effectiveness of the proposed method with respect to competitor methods both in terms of classification accuracy and model complexity. The obtained models have a simple structure, easily amenable to interpretation and analysis.