 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes simple trump complex? Comparing strategies for adversarial robustness in DNNs
Aug 25, 2025
Deep Neural Networks (DNNs) have shown substantial success in various applications but remain vulnerable to adversarial attacks. This study aims to identify and isolate the components of two different adversarial training techniques that contribute most to increased adversarial robustness, particularly through the lens of margins in the input space -- the minimal distance between data points and decision boundaries. Specifically, we compare two methods that maximize margins: a simple approach which modifies the loss function to increase an approximation of the margin, and a more complex state-of-the-art method (Dynamics-Aware Robust Training) which builds upon this approach. Using a VGG-16 model as our base, we systematically isolate and evaluate individual components from these methods to determine their relative impact on adversarial robustness. We assess the effect of each component on the model's performance under various adversarial attacks, including AutoAttack and Projected Gradient Descent (PGD). Our analysis on the CIFAR-10 dataset reveals which elements most effectively enhance adversarial robustness, providing insights for designing more robust DNNs.
A Data Pilot-Aided Temporal Convolutional Network for Channel Estimation in IEEE 802.11p Vehicle-to-Vehicle Communications
Feb 05, 2025In modern communication systems, having an accurate channel estimator is crucial. However, when there is mobility, it becomes difficult to estimate the channel and the pilot signals, which are used for channel estimation, become insufficient. In this paper, we introduce the use of Temporal Convolutional Networks (TCNs) with data pilot-aided (DPA) channel estimation and temporal averaging (TA) to estimate vehicle-to-vehicle same direction with Wall (VTV-SDWW) channels. The TCN-DPA-TA estimator showed an improvement in Bit Error Rate (BER) performance of up to 1 order of magnitude. Furthermore, the BER performance of the TCN-DPA without TA also improved by up to 0.7 magnitude compared to the best classical estimator.
* 10 pages, 7 Figures, SATNAC 2024 proceedings
Pre-training a Transformer-Based Generative Model Using a Small Sepedi Dataset
Jan 25, 2025Due to the scarcity of data in low-resourced languages, the development of language models for these languages has been very slow. Currently, pre-trained language models have gained popularity in natural language processing, especially, in developing domain-specific models for low-resourced languages. In this study, we experiment with the impact of using occlusion-based techniques when training a language model for a text generation task. We curate 2 new datasets, the Sepedi monolingual (SepMono) dataset from several South African resources and the Sepedi radio news (SepNews) dataset from the radio news domain. We use the SepMono dataset to pre-train transformer-based models using the occlusion and non-occlusion pre-training techniques and compare performance. The SepNews dataset is specifically used for fine-tuning. Our results show that the non-occlusion models perform better compared to the occlusion-based models when measuring validation loss and perplexity. However, analysis of the generated text using the BLEU score metric, which measures the quality of the generated text, shows a slightly higher BLEU score for the occlusion-based models compared to the non-occlusion models.
Impact of Batch Normalization on Convolutional Network Representations
Jan 24, 2025Batch normalization (BatchNorm) is a popular layer normalization technique used when training deep neural networks. It has been shown to enhance the training speed and accuracy of deep learning models. However, the mechanics by which BatchNorm achieves these benefits is an active area of research, and different perspectives have been proposed. In this paper, we investigate the effect of BatchNorm on the resulting hidden representations, that is, the vectors of activation values formed as samples are processed at each hidden layer. Specifically, we consider the sparsity of these representations, as well as their implicit clustering -- the creation of groups of representations that are similar to some extent. We contrast image classification models trained with and without batch normalization and highlight consistent differences observed. These findings highlight that BatchNorm's effect on representational sparsity is not a significant factor affecting generalization, while the representations of models trained with BatchNorm tend to show more advantageous clustering characteristics.
Is network fragmentation a useful complexity measure?
Nov 07, 2024



It has been observed that the input space of deep neural network classifiers can exhibit `fragmentation', where the model function rapidly changes class as the input space is traversed. The severity of this fragmentation tends to follow the double descent curve, achieving a maximum at the interpolation regime. We study this phenomenon in the context of image classification and ask whether fragmentation could be predictive of generalization performance. Using a fragmentation-based complexity measure, we show this to be possible by achieving good performance on the PGDL (Predicting Generalization in Deep Learning) benchmark. In addition, we report on new observations related to fragmentation, namely (i) fragmentation is not limited to the input space but occurs in the hidden representations as well, (ii) fragmentation follows the trends in the validation error throughout training, and (iii) fragmentation is not a direct result of increased weight norms. Together, this indicates that fragmentation is a phenomenon worth investigating further when studying the generalization ability of deep neural networks.
Input margins can predict generalization too
Aug 29, 2023Understanding generalization in deep neural networks is an active area of research. A promising avenue of exploration has been that of margin measurements: the shortest distance to the decision boundary for a given sample or its representation internal to the network. While margins have been shown to be correlated with the generalization ability of a model when measured at its hidden representations (hidden margins), no such link between large margins and generalization has been established for input margins. We show that while input margins are not generally predictive of generalization, they can be if the search space is appropriately constrained. We develop such a measure based on input margins, which we refer to as `constrained margins'. The predictive power of this new measure is demonstrated on the 'Predicting Generalization in Deep Learning' (PGDL) dataset and contrasted with hidden representation margins. We find that constrained margins achieve highly competitive scores and outperform other margin measurements in general. This provides a novel insight on the relationship between generalization and classification margins, and highlights the importance of considering the data manifold for investigations of generalization in DNNs.
The Missing Margin: How Sample Corruption Affects Distance to the Boundary in ANNs
Feb 14, 2023Classification margins are commonly used to estimate the generalization ability of machine learning models. We present an empirical study of these margins in artificial neural networks. A global estimate of margin size is usually used in the literature. In this work, we point out seldom considered nuances regarding classification margins. Notably, we demonstrate that some types of training samples are modelled with consistently small margins while affecting generalization in different ways. By showing a link with the minimum distance to a different-target sample and the remoteness of samples from one another, we provide a plausible explanation for this observation. We support our findings with an analysis of fully-connected networks trained on noise-corrupted MNIST data, as well as convolutional networks trained on noise-corrupted CIFAR10 data.
* This work is a preprint of a published paper by the same name, which it subsumes. This preprint is an extended version: it contains additional empirical evidence and discussion
Efficient acoustic feature transformation in mismatched environments using a Guided-GAN
Oct 06, 2022

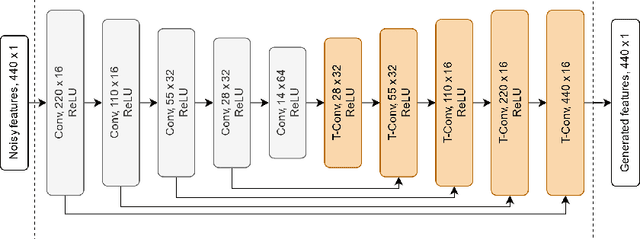

We propose a new framework to improve automatic speech recognition (ASR) systems in resource-scarce environments using a generative adversarial network (GAN) operating on acoustic input features. The GAN is used to enhance the features of mismatched data prior to decoding, or can optionally be used to fine-tune the acoustic model. We achieve improvements that are comparable to multi-style training (MTR), but at a lower computational cost. With less than one hour of data, an ASR system trained on good quality data, and evaluated on mismatched audio is improved by between 11.5% and 19.7% relative word error rate (WER). Experiments demonstrate that the framework can be very useful in under-resourced environments where training data and computational resources are limited. The GAN does not require parallel training data, because it utilises a baseline acoustic model to provide an additional loss term that guides the generator to create acoustic features that are better classified by the baseline.
* Final published version available at: Efficient acoustic feature transformation in mismatched environments using a Guided-GAN. Speech Communication, 143, pp.10-20
Multi-style Training for South African Call Centre Audio
Feb 15, 2022Mismatched data is a challenging problem for automatic speech recognition (ASR) systems. One of the most common techniques used to address mismatched data is multi-style training (MTR), a form of data augmentation that attempts to transform the training data to be more representative of the testing data; and to learn robust representations applicable to different conditions. This task can be very challenging if the test conditions are unknown. We explore the impact of different MTR styles on system performance when testing conditions are different from training conditions in the context of deep neural network hidden Markov model (DNN-HMM) ASR systems. A controlled environment is created using the LibriSpeech corpus, where we isolate the effect of different MTR styles on final system performance. We evaluate our findings on a South African call centre dataset that contains noisy, WAV49-encoded audio.
* 9 pages, 8 tables, Southern African Conference for Artificial Intelligence Research 2021, Part of the Communications in Computer and Information Science book series (CCIS, volume 1551, pp 111-124), Springer
Exploring layerwise decision making in DNNs
Feb 01, 2022While deep neural networks (DNNs) have become a standard architecture for many machine learning tasks, their internal decision-making process and general interpretability is still poorly understood. Conversely, common decision trees are easily interpretable and theoretically well understood. We show that by encoding the discrete sample activation values of nodes as a binary representation, we are able to extract a decision tree explaining the classification procedure of each layer in a ReLU-activated multilayer perceptron (MLP). We then combine these decision trees with existing feature attribution techniques in order to produce an interpretation of each layer of a model. Finally, we provide an analysis of the generated interpretations, the behaviour of the binary encodings and how these relate to sample groupings created during the training process of the neural network.