 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking translation invariance in CNNs
Apr 19, 2021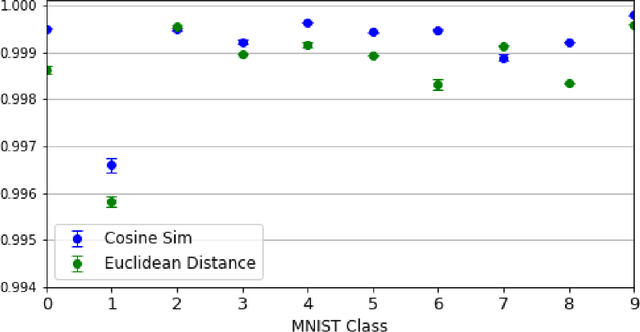
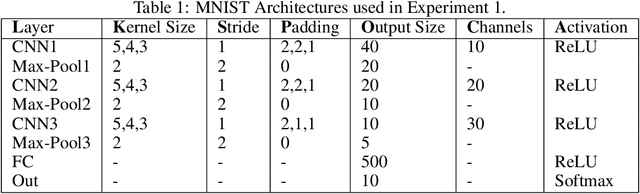
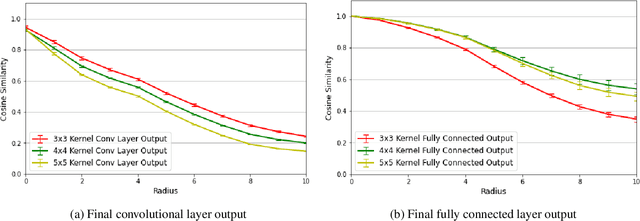

Although Convolutional Neural Networks (CNNs) are widely used, their translation invariance (ability to deal with translated inputs) is still subject to some controversy. We explore this question using translation-sensitivity maps to quantify how sensitive a standard CNN is to a translated input. We propose the use of Cosine Similarity as sensitivity metric over Euclidean Distance, and discuss the importance of restricting the dimensionality of either of these metrics when comparing architectures. Our main focus is to investigate the effect of different architectural components of a standard CNN on that network's sensitivity to translation. By varying convolutional kernel sizes and amounts of zero padding, we control the size of the feature maps produced, allowing us to quantify the extent to which these elements influence translation invariance. We also measure translation invariance at different locations within the CNN to determine the extent to which convolutional and fully connected layers, respectively, contribute to the translation invariance of a CNN as a whole. Our analysis indicates that both convolutional kernel size and feature map size have a systematic influence on translation invariance. We also see that convolutional layers contribute less than expected to translation invariance, when not specifically forced to do so.
Stride and Translation Invariance in CNNs
Mar 18, 2021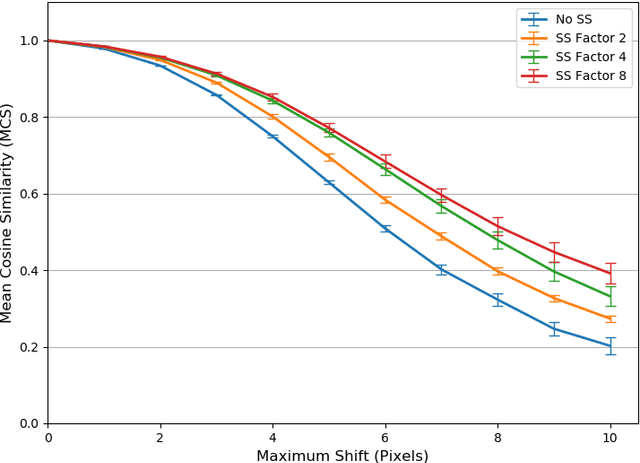
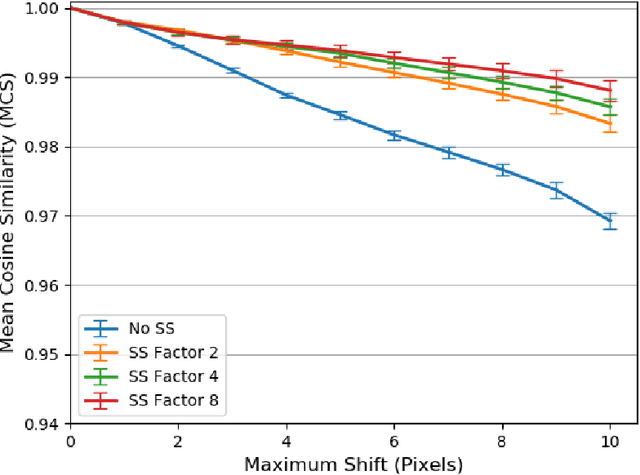
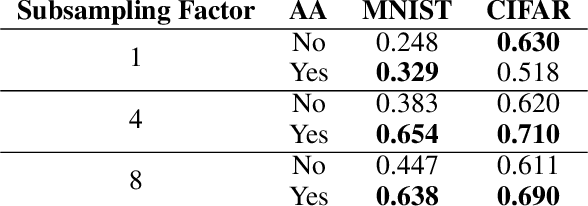
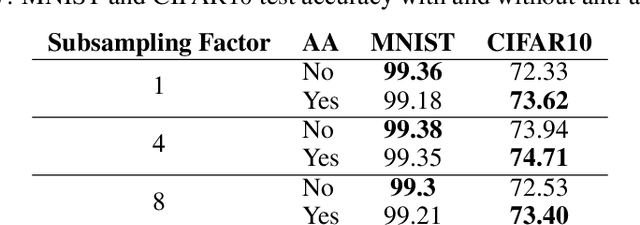
Convolutional Neural Networks have become the standard for image classification tasks, however, these architectures are not invariant to translations of the input image. This lack of invariance is attributed to the use of stride which ignores the sampling theorem, and fully connected layers which lack spatial reasoning. We show that stride can greatly benefit translation invariance given that it is combined with sufficient similarity between neighbouring pixels, a characteristic which we refer to as local homogeneity. We also observe that this characteristic is dataset-specific and dictates the relationship between pooling kernel size and stride required for translation invariance. Furthermore we find that a trade-off exists between generalization and translation invariance in the case of pooling kernel size, as larger kernel sizes lead to better invariance but poorer generalization. Finally we explore the efficacy of other solutions proposed, namely global average pooling, anti-aliasing, and data augmentation, both empirically and through the lens of local homogeneity.