 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes simple trump complex? Comparing strategies for adversarial robustness in DNNs
Aug 25, 2025
Deep Neural Networks (DNNs) have shown substantial success in various applications but remain vulnerable to adversarial attacks. This study aims to identify and isolate the components of two different adversarial training techniques that contribute most to increased adversarial robustness, particularly through the lens of margins in the input space -- the minimal distance between data points and decision boundaries. Specifically, we compare two methods that maximize margins: a simple approach which modifies the loss function to increase an approximation of the margin, and a more complex state-of-the-art method (Dynamics-Aware Robust Training) which builds upon this approach. Using a VGG-16 model as our base, we systematically isolate and evaluate individual components from these methods to determine their relative impact on adversarial robustness. We assess the effect of each component on the model's performance under various adversarial attacks, including AutoAttack and Projected Gradient Descent (PGD). Our analysis on the CIFAR-10 dataset reveals which elements most effectively enhance adversarial robustness, providing insights for designing more robust DNNs.
Impact of Batch Normalization on Convolutional Network Representations
Jan 24, 2025Batch normalization (BatchNorm) is a popular layer normalization technique used when training deep neural networks. It has been shown to enhance the training speed and accuracy of deep learning models. However, the mechanics by which BatchNorm achieves these benefits is an active area of research, and different perspectives have been proposed. In this paper, we investigate the effect of BatchNorm on the resulting hidden representations, that is, the vectors of activation values formed as samples are processed at each hidden layer. Specifically, we consider the sparsity of these representations, as well as their implicit clustering -- the creation of groups of representations that are similar to some extent. We contrast image classification models trained with and without batch normalization and highlight consistent differences observed. These findings highlight that BatchNorm's effect on representational sparsity is not a significant factor affecting generalization, while the representations of models trained with BatchNorm tend to show more advantageous clustering characteristics.
Is network fragmentation a useful complexity measure?
Nov 07, 2024



It has been observed that the input space of deep neural network classifiers can exhibit `fragmentation', where the model function rapidly changes class as the input space is traversed. The severity of this fragmentation tends to follow the double descent curve, achieving a maximum at the interpolation regime. We study this phenomenon in the context of image classification and ask whether fragmentation could be predictive of generalization performance. Using a fragmentation-based complexity measure, we show this to be possible by achieving good performance on the PGDL (Predicting Generalization in Deep Learning) benchmark. In addition, we report on new observations related to fragmentation, namely (i) fragmentation is not limited to the input space but occurs in the hidden representations as well, (ii) fragmentation follows the trends in the validation error throughout training, and (iii) fragmentation is not a direct result of increased weight norms. Together, this indicates that fragmentation is a phenomenon worth investigating further when studying the generalization ability of deep neural networks.
Input margins can predict generalization too
Aug 29, 2023Understanding generalization in deep neural networks is an active area of research. A promising avenue of exploration has been that of margin measurements: the shortest distance to the decision boundary for a given sample or its representation internal to the network. While margins have been shown to be correlated with the generalization ability of a model when measured at its hidden representations (hidden margins), no such link between large margins and generalization has been established for input margins. We show that while input margins are not generally predictive of generalization, they can be if the search space is appropriately constrained. We develop such a measure based on input margins, which we refer to as `constrained margins'. The predictive power of this new measure is demonstrated on the 'Predicting Generalization in Deep Learning' (PGDL) dataset and contrasted with hidden representation margins. We find that constrained margins achieve highly competitive scores and outperform other margin measurements in general. This provides a novel insight on the relationship between generalization and classification margins, and highlights the importance of considering the data manifold for investigations of generalization in DNNs.
The Missing Margin: How Sample Corruption Affects Distance to the Boundary in ANNs
Feb 14, 2023Classification margins are commonly used to estimate the generalization ability of machine learning models. We present an empirical study of these margins in artificial neural networks. A global estimate of margin size is usually used in the literature. In this work, we point out seldom considered nuances regarding classification margins. Notably, we demonstrate that some types of training samples are modelled with consistently small margins while affecting generalization in different ways. By showing a link with the minimum distance to a different-target sample and the remoteness of samples from one another, we provide a plausible explanation for this observation. We support our findings with an analysis of fully-connected networks trained on noise-corrupted MNIST data, as well as convolutional networks trained on noise-corrupted CIFAR10 data.
* This work is a preprint of a published paper by the same name, which it subsumes. This preprint is an extended version: it contains additional empirical evidence and discussion
Exploring layerwise decision making in DNNs
Feb 01, 2022While deep neural networks (DNNs) have become a standard architecture for many machine learning tasks, their internal decision-making process and general interpretability is still poorly understood. Conversely, common decision trees are easily interpretable and theoretically well understood. We show that by encoding the discrete sample activation values of nodes as a binary representation, we are able to extract a decision tree explaining the classification procedure of each layer in a ReLU-activated multilayer perceptron (MLP). We then combine these decision trees with existing feature attribution techniques in order to produce an interpretation of each layer of a model. Finally, we provide an analysis of the generated interpretations, the behaviour of the binary encodings and how these relate to sample groupings created during the training process of the neural network.
Tracking translation invariance in CNNs
Apr 19, 2021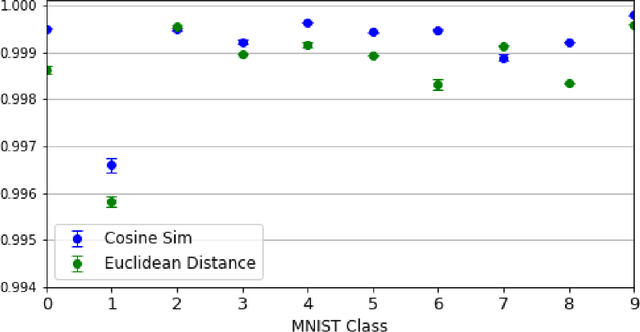
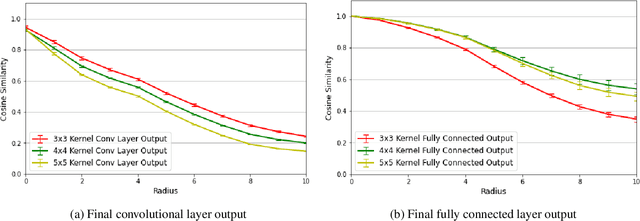

Although Convolutional Neural Networks (CNNs) are widely used, their translation invariance (ability to deal with translated inputs) is still subject to some controversy. We explore this question using translation-sensitivity maps to quantify how sensitive a standard CNN is to a translated input. We propose the use of Cosine Similarity as sensitivity metric over Euclidean Distance, and discuss the importance of restricting the dimensionality of either of these metrics when comparing architectures. Our main focus is to investigate the effect of different architectural components of a standard CNN on that network's sensitivity to translation. By varying convolutional kernel sizes and amounts of zero padding, we control the size of the feature maps produced, allowing us to quantify the extent to which these elements influence translation invariance. We also measure translation invariance at different locations within the CNN to determine the extent to which convolutional and fully connected layers, respectively, contribute to the translation invariance of a CNN as a whole. Our analysis indicates that both convolutional kernel size and feature map size have a systematic influence on translation invariance. We also see that convolutional layers contribute less than expected to translation invariance, when not specifically forced to do so.
Stride and Translation Invariance in CNNs
Mar 18, 2021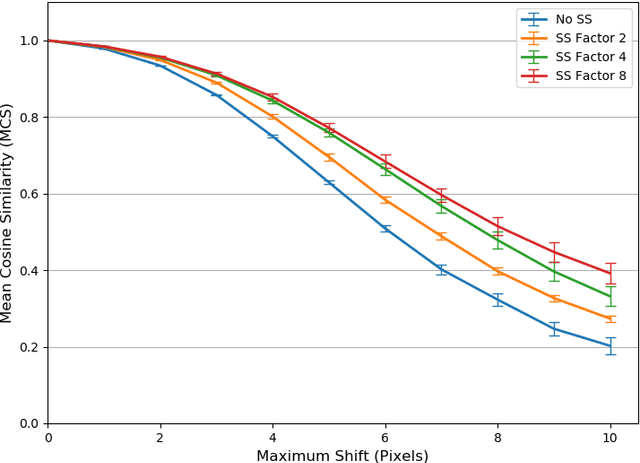
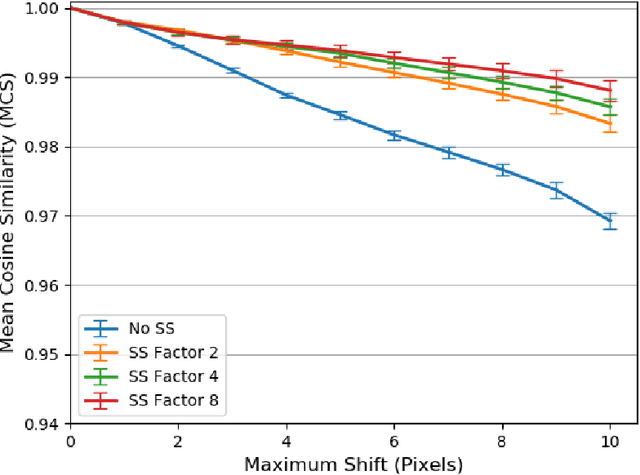
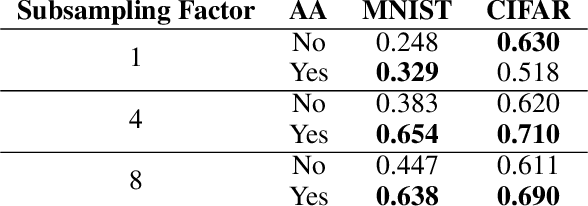
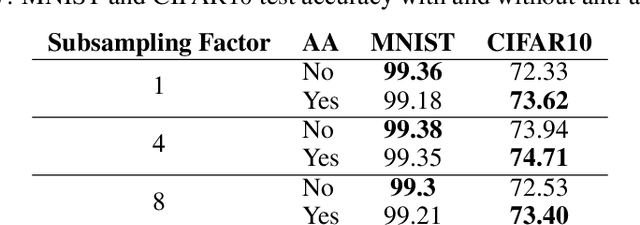
Convolutional Neural Networks have become the standard for image classification tasks, however, these architectures are not invariant to translations of the input image. This lack of invariance is attributed to the use of stride which ignores the sampling theorem, and fully connected layers which lack spatial reasoning. We show that stride can greatly benefit translation invariance given that it is combined with sufficient similarity between neighbouring pixels, a characteristic which we refer to as local homogeneity. We also observe that this characteristic is dataset-specific and dictates the relationship between pooling kernel size and stride required for translation invariance. Furthermore we find that a trade-off exists between generalization and translation invariance in the case of pooling kernel size, as larger kernel sizes lead to better invariance but poorer generalization. Finally we explore the efficacy of other solutions proposed, namely global average pooling, anti-aliasing, and data augmentation, both empirically and through the lens of local homogeneity.