 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs network fragmentation a useful complexity measure?
Nov 07, 2024



It has been observed that the input space of deep neural network classifiers can exhibit `fragmentation', where the model function rapidly changes class as the input space is traversed. The severity of this fragmentation tends to follow the double descent curve, achieving a maximum at the interpolation regime. We study this phenomenon in the context of image classification and ask whether fragmentation could be predictive of generalization performance. Using a fragmentation-based complexity measure, we show this to be possible by achieving good performance on the PGDL (Predicting Generalization in Deep Learning) benchmark. In addition, we report on new observations related to fragmentation, namely (i) fragmentation is not limited to the input space but occurs in the hidden representations as well, (ii) fragmentation follows the trends in the validation error throughout training, and (iii) fragmentation is not a direct result of increased weight norms. Together, this indicates that fragmentation is a phenomenon worth investigating further when studying the generalization ability of deep neural networks.
Input margins can predict generalization too
Aug 29, 2023Understanding generalization in deep neural networks is an active area of research. A promising avenue of exploration has been that of margin measurements: the shortest distance to the decision boundary for a given sample or its representation internal to the network. While margins have been shown to be correlated with the generalization ability of a model when measured at its hidden representations (hidden margins), no such link between large margins and generalization has been established for input margins. We show that while input margins are not generally predictive of generalization, they can be if the search space is appropriately constrained. We develop such a measure based on input margins, which we refer to as `constrained margins'. The predictive power of this new measure is demonstrated on the 'Predicting Generalization in Deep Learning' (PGDL) dataset and contrasted with hidden representation margins. We find that constrained margins achieve highly competitive scores and outperform other margin measurements in general. This provides a novel insight on the relationship between generalization and classification margins, and highlights the importance of considering the data manifold for investigations of generalization in DNNs.
The Missing Margin: How Sample Corruption Affects Distance to the Boundary in ANNs
Feb 14, 2023Classification margins are commonly used to estimate the generalization ability of machine learning models. We present an empirical study of these margins in artificial neural networks. A global estimate of margin size is usually used in the literature. In this work, we point out seldom considered nuances regarding classification margins. Notably, we demonstrate that some types of training samples are modelled with consistently small margins while affecting generalization in different ways. By showing a link with the minimum distance to a different-target sample and the remoteness of samples from one another, we provide a plausible explanation for this observation. We support our findings with an analysis of fully-connected networks trained on noise-corrupted MNIST data, as well as convolutional networks trained on noise-corrupted CIFAR10 data.
* This work is a preprint of a published paper by the same name, which it subsumes. This preprint is an extended version: it contains additional empirical evidence and discussion
Pre-interpolation loss behaviour in neural networks
Mar 14, 2021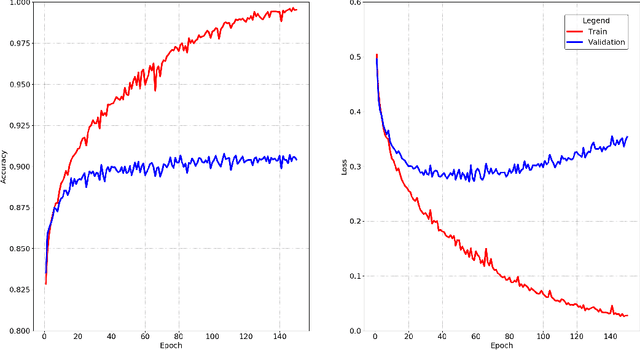

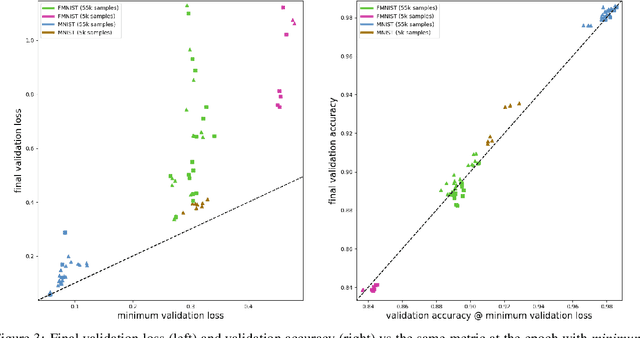
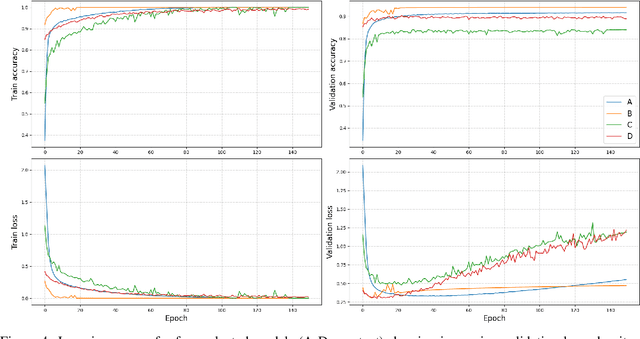
When training neural networks as classifiers, it is common to observe an increase in average test loss while still maintaining or improving the overall classification accuracy on the same dataset. In spite of the ubiquity of this phenomenon, it has not been well studied and is often dismissively attributed to an increase in borderline correct classifications. We present an empirical investigation that shows how this phenomenon is actually a result of the differential manner by which test samples are processed. In essence: test loss does not increase overall, but only for a small minority of samples. Large representational capacities allow losses to decrease for the vast majority of test samples at the cost of extreme increases for others. This effect seems to be mainly caused by increased parameter values relating to the correctly processed sample features. Our findings contribute to the practical understanding of a common behaviour of deep neural networks. We also discuss the implications of this work for network optimisation and generalisation.
* 11 pages, 8 figures. Presented at the 2021 SACAIR online conference in February 2021
DNNs as Layers of Cooperating Classifiers
Jan 17, 2020



A robust theoretical framework that can describe and predict the generalization ability of deep neural networks (DNNs) in general circumstances remains elusive. Classical attempts have produced complexity metrics that rely heavily on global measures of compactness and capacity with little investigation into the effects of sub-component collaboration. We demonstrate intriguing regularities in the activation patterns of the hidden nodes within fully-connected feedforward networks. By tracing the origin of these patterns, we show how such networks can be viewed as the combination of two information processing systems: one continuous and one discrete. We describe how these two systems arise naturally from the gradient-based optimization process, and demonstrate the classification ability of the two systems, individually and in collaboration. This perspective on DNN classification offers a novel way to think about generalization, in which different subsets of the training data are used to train distinct classifiers; those classifiers are then combined to perform the classification task, and their consistency is crucial for accurate classification.