 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimum Phase Linear Antenna Array Design
Dec 21, 2022



The paper considers the design of minimum phase discrete linear arrays. The paper introduces recent advances for the design of minimum phase Finite Impulse Response filters, as applied to the design of minimum phase linear arrays. The minimum phase linear array is demonstrated to require the least number of elements of all linear arrays that are able to achieve a given magnitude pattern specification. Three example designs are presented and compared to results from the literature.
Manifold Characteristics That Predict Downstream Task Performance
May 16, 2022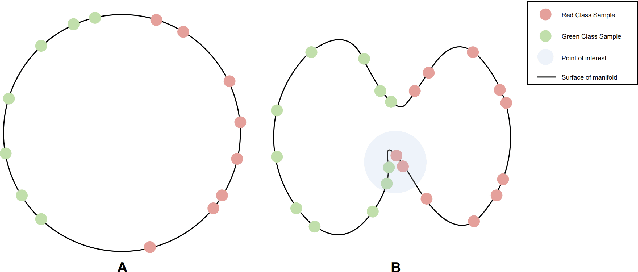
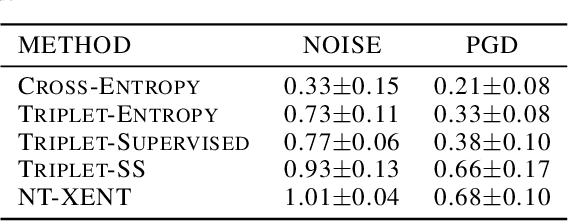
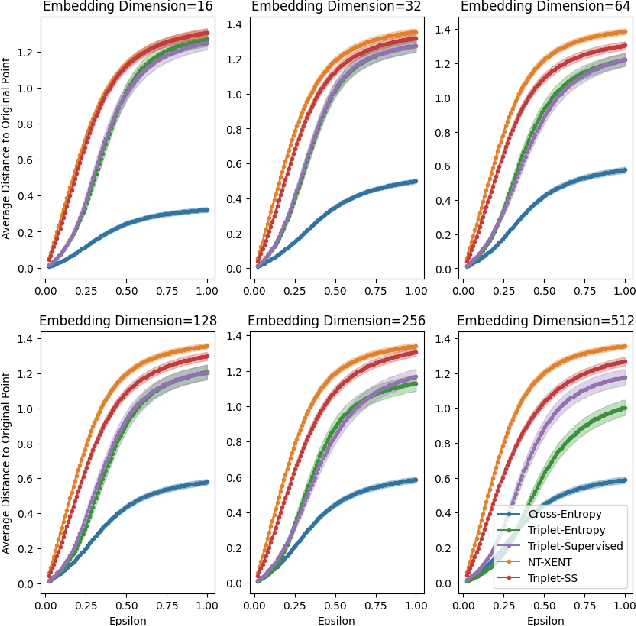

Pretraining methods are typically compared by evaluating the accuracy of linear classifiers, transfer learning performance, or visually inspecting the representation manifold's (RM) lower-dimensional projections. We show that the differences between methods can be understood more clearly by investigating the RM directly, which allows for a more detailed comparison. To this end, we propose a framework and new metric to measure and compare different RMs. We also investigate and report on the RM characteristics for various pretraining methods. These characteristics are measured by applying sequentially larger local alterations to the input data, using white noise injections and Projected Gradient Descent (PGD) adversarial attacks, and then tracking each datapoint. We calculate the total distance moved for each datapoint and the relative change in distance between successive alterations. We show that self-supervised methods learn an RM where alterations lead to large but constant size changes, indicating a smoother RM than fully supervised methods. We then combine these measurements into one metric, the Representation Manifold Quality Metric (RMQM), where larger values indicate larger and less variable step sizes, and show that RMQM correlates positively with performance on downstream tasks.
DNNs as Layers of Cooperating Classifiers
Jan 17, 2020



A robust theoretical framework that can describe and predict the generalization ability of deep neural networks (DNNs) in general circumstances remains elusive. Classical attempts have produced complexity metrics that rely heavily on global measures of compactness and capacity with little investigation into the effects of sub-component collaboration. We demonstrate intriguing regularities in the activation patterns of the hidden nodes within fully-connected feedforward networks. By tracing the origin of these patterns, we show how such networks can be viewed as the combination of two information processing systems: one continuous and one discrete. We describe how these two systems arise naturally from the gradient-based optimization process, and demonstrate the classification ability of the two systems, individually and in collaboration. This perspective on DNN classification offers a novel way to think about generalization, in which different subsets of the training data are used to train distinct classifiers; those classifiers are then combined to perform the classification task, and their consistency is crucial for accurate classification.