 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient acoustic feature transformation in mismatched environments using a Guided-GAN
Oct 06, 2022

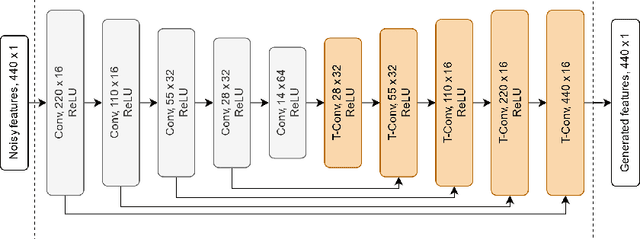

We propose a new framework to improve automatic speech recognition (ASR) systems in resource-scarce environments using a generative adversarial network (GAN) operating on acoustic input features. The GAN is used to enhance the features of mismatched data prior to decoding, or can optionally be used to fine-tune the acoustic model. We achieve improvements that are comparable to multi-style training (MTR), but at a lower computational cost. With less than one hour of data, an ASR system trained on good quality data, and evaluated on mismatched audio is improved by between 11.5% and 19.7% relative word error rate (WER). Experiments demonstrate that the framework can be very useful in under-resourced environments where training data and computational resources are limited. The GAN does not require parallel training data, because it utilises a baseline acoustic model to provide an additional loss term that guides the generator to create acoustic features that are better classified by the baseline.
* Final published version available at: Efficient acoustic feature transformation in mismatched environments using a Guided-GAN. Speech Communication, 143, pp.10-20
Multi-style Training for South African Call Centre Audio
Feb 15, 2022Mismatched data is a challenging problem for automatic speech recognition (ASR) systems. One of the most common techniques used to address mismatched data is multi-style training (MTR), a form of data augmentation that attempts to transform the training data to be more representative of the testing data; and to learn robust representations applicable to different conditions. This task can be very challenging if the test conditions are unknown. We explore the impact of different MTR styles on system performance when testing conditions are different from training conditions in the context of deep neural network hidden Markov model (DNN-HMM) ASR systems. A controlled environment is created using the LibriSpeech corpus, where we isolate the effect of different MTR styles on final system performance. We evaluate our findings on a South African call centre dataset that contains noisy, WAV49-encoded audio.
* 9 pages, 8 tables, Southern African Conference for Artificial Intelligence Research 2021, Part of the Communications in Computer and Information Science book series (CCIS, volume 1551, pp 111-124), Springer