 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Audio Reasoning Capabilities of Multimodal Large Language Models
Jan 27, 2026The present benchmarks for testing the audio modality of multimodal large language models concentrate on testing various audio tasks such as speaker diarization or gender identification in isolation. Whether a multimodal model can answer the questions that require reasoning skills to combine audio tasks of different categories, cannot be verified with their use. To address this issue, we propose Audio Reasoning Tasks (ART), a new benchmark for assessing the ability of multimodal models to solve problems that require reasoning over audio signal.
ClonEval: An Open Voice Cloning Benchmark
Apr 29, 2025



We present a novel benchmark for voice cloning text-to-speech models. The benchmark consists of an evaluation protocol, an open-source library for assessing the performance of voice cloning models, and an accompanying leaderboard. The paper discusses design considerations and presents a detailed description of the evaluation procedure. The usage of the software library is explained, along with the organization of results on the leaderboard.
LLMzSzŁ: a comprehensive LLM benchmark for Polish
Jan 04, 2025This article introduces the first comprehensive benchmark for the Polish language at this scale: LLMzSz{\L} (LLMs Behind the School Desk). It is based on a coherent collection of Polish national exams, including both academic and professional tests extracted from the archives of the Polish Central Examination Board. It covers 4 types of exams, coming from 154 domains. Altogether, it consists of almost 19k closed-ended questions. We investigate the performance of open-source multilingual, English, and Polish LLMs to verify LLMs' abilities to transfer knowledge between languages. Also, the correlation between LLMs and humans at model accuracy and exam pass rate levels is examined. We show that multilingual LLMs can obtain superior results over monolingual ones; however, monolingual models may be beneficial when model size matters. Our analysis highlights the potential of LLMs in assisting with exam validation, particularly in identifying anomalies or errors in examination tasks.
Polish Medical Exams: A new dataset for cross-lingual medical knowledge transfer assessment
Nov 30, 2024



Large Language Models (LLMs) have demonstrated significant potential in handling specialized tasks, including medical problem-solving. However, most studies predominantly focus on English-language contexts. This study introduces a novel benchmark dataset based on Polish medical licensing and specialization exams (LEK, LDEK, PES) taken by medical doctor candidates and practicing doctors pursuing specialization. The dataset was web-scraped from publicly available resources provided by the Medical Examination Center and the Chief Medical Chamber. It comprises over 24,000 exam questions, including a subset of parallel Polish-English corpora, where the English portion was professionally translated by the examination center for foreign candidates. By creating a structured benchmark from these existing exam questions, we systematically evaluate state-of-the-art LLMs, including general-purpose, domain-specific, and Polish-specific models, and compare their performance against human medical students. Our analysis reveals that while models like GPT-4o achieve near-human performance, significant challenges persist in cross-lingual translation and domain-specific understanding. These findings underscore disparities in model performance across languages and medical specialties, highlighting the limitations and ethical considerations of deploying LLMs in clinical practice.
POLygraph: Polish Fake News Dataset
Jul 01, 2024This paper presents the POLygraph dataset, a unique resource for fake news detection in Polish. The dataset, created by an interdisciplinary team, is composed of two parts: the "fake-or-not" dataset with 11,360 pairs of news articles (identified by their URLs) and corresponding labels, and the "fake-they-say" dataset with 5,082 news articles (identified by their URLs) and tweets commenting on them. Unlike existing datasets, POLygraph encompasses a variety of approaches from source literature, providing a comprehensive resource for fake news detection. The data was collected through manual annotation by expert and non-expert annotators. The project also developed a software tool that uses advanced machine learning techniques to analyze the data and determine content authenticity. The tool and dataset are expected to benefit various entities, from public sector institutions to publishers and fact-checking organizations. Further dataset exploration will foster fake news detection and potentially stimulate the implementation of similar models in other languages. The paper focuses on the creation and composition of the dataset, so it does not include a detailed evaluation of the software tool for content authenticity analysis, which is planned at a later stage of the project.
Spoken Language Corpora Augmentation with Domain-Specific Voice-Cloned Speech
Jun 11, 2024In this paper we study the impact of augmenting spoken language corpora with domain-specific synthetic samples for the purpose of training a speech recognition system. Using both a conventional neural TTS system and a zero-shot one with voice cloning ability we generate speech corpora that vary in the number of voices. We compare speech recognition models trained with addition of different amounts of synthetic data generated using these two methods with a baseline model trained solely on voice recordings. We show that while the quality of voice-cloned dataset is lower, its increased multivoiceity makes it much more effective than the one with only a few voices synthesized with the use of a conventional neural TTS system. Furthermore, our experiments indicate that using low variability synthetic speech quickly leads to saturation in the quality of the ASR whereas high variability speech provides improvement even when increasing total amount of data used for training by 30%.
Two Approaches to Diachronic Normalization of Polish Texts
Feb 02, 2024This paper discusses two approaches to the diachronic normalization of Polish texts: a rule-based solution that relies on a set of handcrafted patterns, and a neural normalization model based on the text-to-text transfer transformer architecture. The training and evaluation data prepared for the task are discussed in detail, along with experiments conducted to compare the proposed normalization solutions. A quantitative and qualitative analysis is made. It is shown that at the current stage of inquiry into the problem, the rule-based solution outperforms the neural one on 3 out of 4 variants of the prepared dataset, although in practice both approaches have distinct advantages and disadvantages.
Back Transcription as a Method for Evaluating Robustness of Natural Language Understanding Models to Speech Recognition Errors
Oct 25, 2023In a spoken dialogue system, an NLU model is preceded by a speech recognition system that can deteriorate the performance of natural language understanding. This paper proposes a method for investigating the impact of speech recognition errors on the performance of natural language understanding models. The proposed method combines the back transcription procedure with a fine-grained technique for categorizing the errors that affect the performance of NLU models. The method relies on the usage of synthesized speech for NLU evaluation. We show that the use of synthesized speech in place of audio recording does not change the outcomes of the presented technique in a significant way.
Open Challenge for Correcting Errors of Speech Recognition Systems
Jan 09, 2020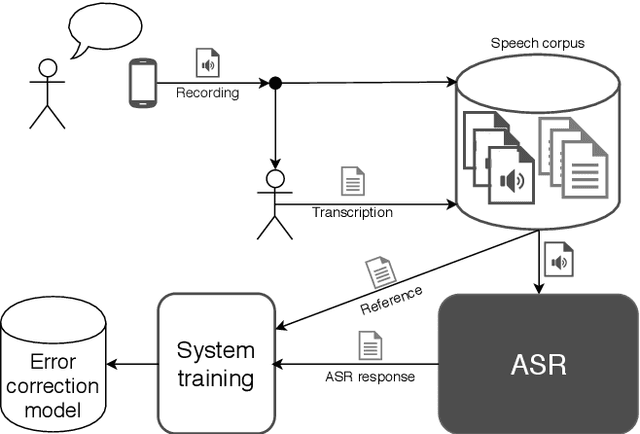

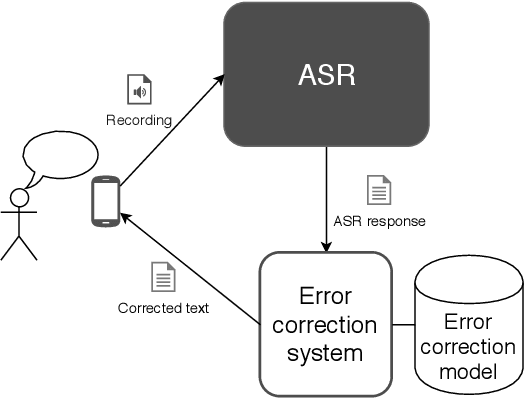

The paper announces the new long-term challenge for improving the performance of automatic speech recognition systems. The goal of the challenge is to investigate methods of correcting the recognition results on the basis of previously made errors by the speech processing system. The dataset prepared for the task is described and evaluation criteria are presented.