 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Audio Reasoning Capabilities of Multimodal Large Language Models
Jan 27, 2026The present benchmarks for testing the audio modality of multimodal large language models concentrate on testing various audio tasks such as speaker diarization or gender identification in isolation. Whether a multimodal model can answer the questions that require reasoning skills to combine audio tasks of different categories, cannot be verified with their use. To address this issue, we propose Audio Reasoning Tasks (ART), a new benchmark for assessing the ability of multimodal models to solve problems that require reasoning over audio signal.
LoRP-TTS: Low-Rank Personalized Text-To-Speech
Feb 11, 2025Speech synthesis models convert written text into natural-sounding audio. While earlier models were limited to a single speaker, recent advancements have led to the development of zero-shot systems that generate realistic speech from a wide range of speakers using their voices as additional prompts. However, they still struggle with imitating non-studio-quality samples that differ significantly from the training datasets. In this work, we demonstrate that utilizing Low-Rank Adaptation (LoRA) allows us to successfully use even single recordings of spontaneous speech in noisy environments as prompts. This approach enhances speaker similarity by up to $30pp$ while preserving content and naturalness. It represents a significant step toward creating truly diverse speech corpora, that is crucial in all speech-related tasks.
Augmenting Polish Automatic Speech Recognition System With Synthetic Data
Oct 30, 2024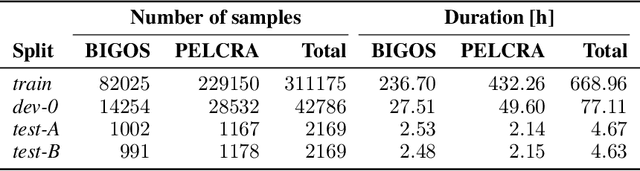
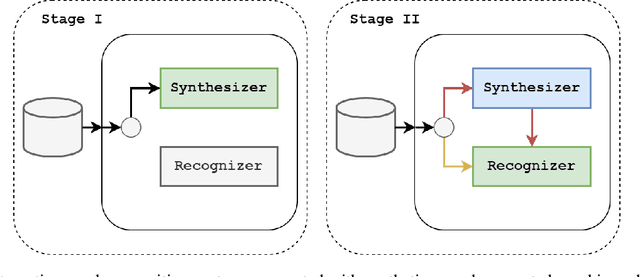

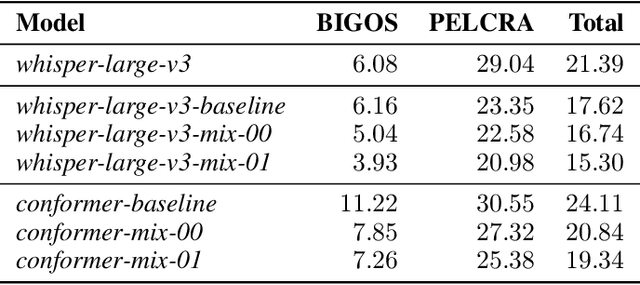
This paper presents a system developed for submission to Poleval 2024, Task 3: Polish Automatic Speech Recognition Challenge. We describe Voicebox-based speech synthesis pipeline and utilize it to augment Conformer and Whisper speech recognition models with synthetic data. We show that addition of synthetic speech to training improves achieved results significantly. We also present final results achieved by our models in the competition.
Spoken Language Corpora Augmentation with Domain-Specific Voice-Cloned Speech
Jun 11, 2024In this paper we study the impact of augmenting spoken language corpora with domain-specific synthetic samples for the purpose of training a speech recognition system. Using both a conventional neural TTS system and a zero-shot one with voice cloning ability we generate speech corpora that vary in the number of voices. We compare speech recognition models trained with addition of different amounts of synthetic data generated using these two methods with a baseline model trained solely on voice recordings. We show that while the quality of voice-cloned dataset is lower, its increased multivoiceity makes it much more effective than the one with only a few voices synthesized with the use of a conventional neural TTS system. Furthermore, our experiments indicate that using low variability synthetic speech quickly leads to saturation in the quality of the ASR whereas high variability speech provides improvement even when increasing total amount of data used for training by 30%.