Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Polish Automatic Speech Recognition System With Synthetic Data
Paper and Code
Oct 30, 2024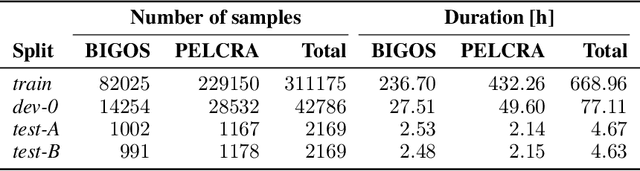
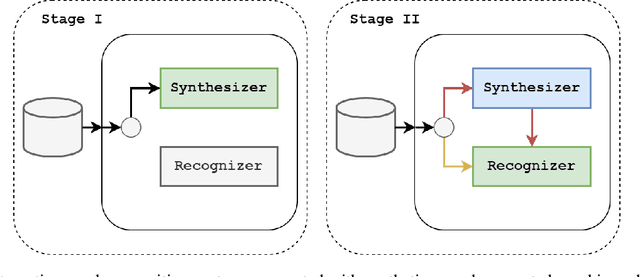

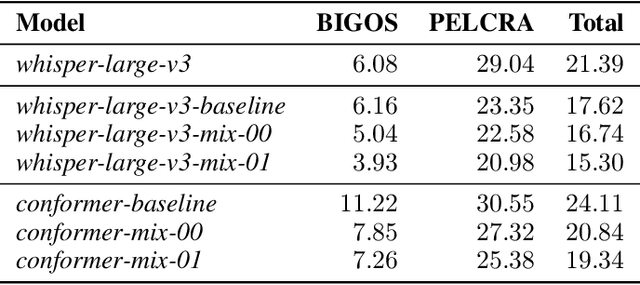
This paper presents a system developed for submission to Poleval 2024, Task 3: Polish Automatic Speech Recognition Challenge. We describe Voicebox-based speech synthesis pipeline and utilize it to augment Conformer and Whisper speech recognition models with synthetic data. We show that addition of synthetic speech to training improves achieved results significantly. We also present final results achieved by our models in the competition.
View paper on