 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion Answering with Texts and Tables through Deep Reinforcement Learning
Jul 05, 2024This paper proposes a novel architecture to generate multi-hop answers to open domain questions that require information from texts and tables, using the Open Table-and-Text Question Answering dataset for validation and training. One of the most common ways to generate answers in this setting is to retrieve information sequentially, where a selected piece of data helps searching for the next piece. As different models can have distinct behaviors when called in this sequential information search, a challenge is how to select models at each step. Our architecture employs reinforcement learning to choose between different state-of-the-art tools sequentially until, in the end, a desired answer is generated. This system achieved an F1-score of 19.03, comparable to iterative systems in the literature.
Assessing Logical Reasoning Capabilities of Encoder-Only Transformer Models
Dec 18, 2023

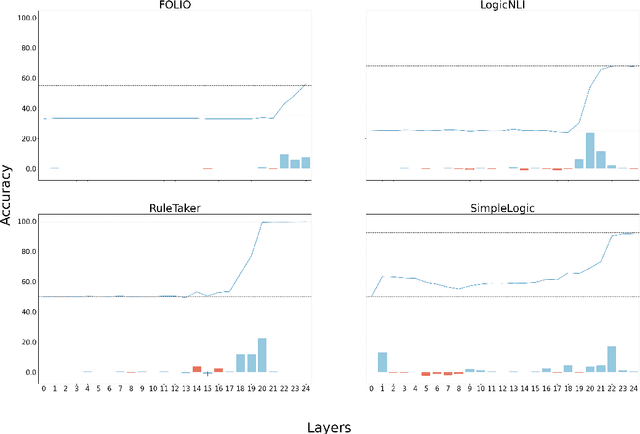
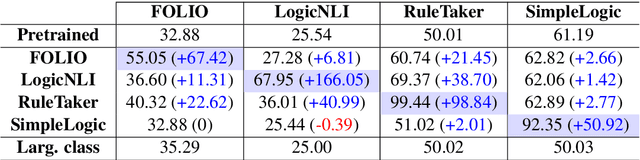
Logical reasoning is central to complex human activities, such as thinking, debating, and planning; it is also a central component of many AI systems as well. In this paper, we investigate the extent to which encoder-only transformer language models (LMs) can reason according to logical rules. We ask whether those LMs can deduce theorems in propositional calculus and first-order logic; if their relative success in these problems reflects general logical capabilities; and which layers contribute the most to the task. First, we show for several encoder-only LMs that they can be trained, to a reasonable degree, to determine logical validity on various datasets. Next, by cross-probing fine-tuned models on these datasets, we show that LMs have difficulty in transferring their putative logical reasoning ability, which suggests that they may have learned dataset-specific features, instead of a general capability. Finally, we conduct a layerwise probing experiment, which shows that the hypothesis classification task is mostly solved through higher layers.
Benchmarks for Pirá 2.0, a Reading Comprehension Dataset about the Ocean, the Brazilian Coast, and Climate Change
Sep 19, 2023Pir\'a is a reading comprehension dataset focused on the ocean, the Brazilian coast, and climate change, built from a collection of scientific abstracts and reports on these topics. This dataset represents a versatile language resource, particularly useful for testing the ability of current machine learning models to acquire expert scientific knowledge. Despite its potential, a detailed set of baselines has not yet been developed for Pir\'a. By creating these baselines, researchers can more easily utilize Pir\'a as a resource for testing machine learning models across a wide range of question answering tasks. In this paper, we define six benchmarks over the Pir\'a dataset, covering closed generative question answering, machine reading comprehension, information retrieval, open question answering, answer triggering, and multiple choice question answering. As part of this effort, we have also produced a curated version of the original dataset, where we fixed a number of grammar issues, repetitions, and other shortcomings. Furthermore, the dataset has been extended in several new directions, so as to face the aforementioned benchmarks: translation of supporting texts from English into Portuguese, classification labels for answerability, automatic paraphrases of questions and answers, and multiple choice candidates. The results described in this paper provide several points of reference for researchers interested in exploring the challenges provided by the Pir\'a dataset.
Comparing Computational Architectures for Automated Journalism
Oct 08, 2022
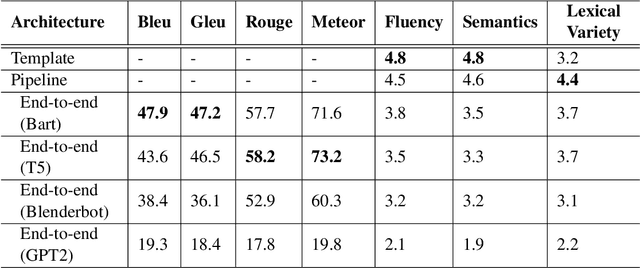
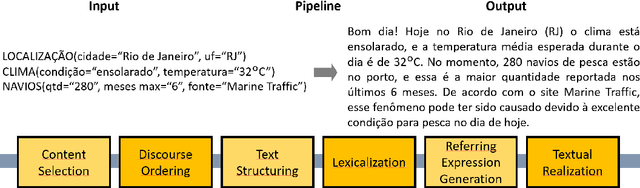
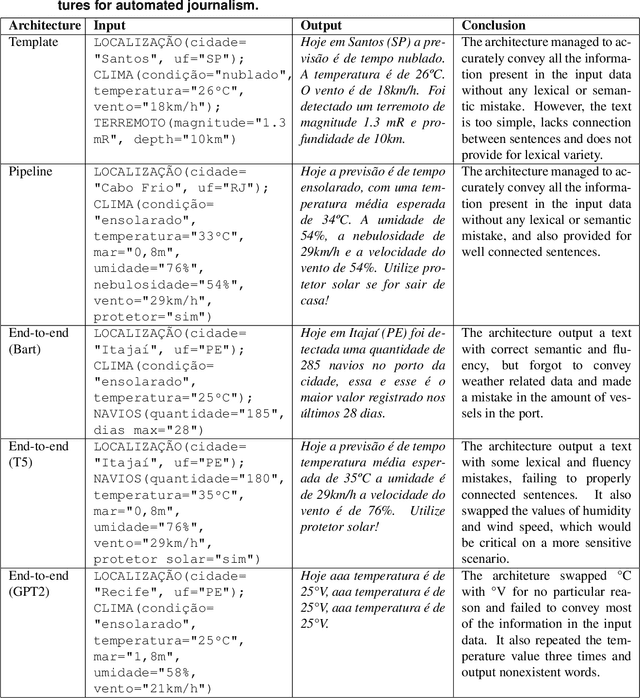
The majority of NLG systems have been designed following either a template-based or a pipeline-based architecture. Recent neural models for data-to-text generation have been proposed with an end-to-end deep learning flavor, which handles non-linguistic input in natural language without explicit intermediary representations. This study compares the most often employed methods for generating Brazilian Portuguese texts from structured data. Results suggest that explicit intermediate steps in the generation process produce better texts than the ones generated by neural end-to-end architectures, avoiding data hallucination while better generalizing to unseen inputs. Code and corpus are publicly available.
The BLue Amazon Brain : A Modular Architecture of Services about the Brazilian Maritime Territory
Sep 06, 2022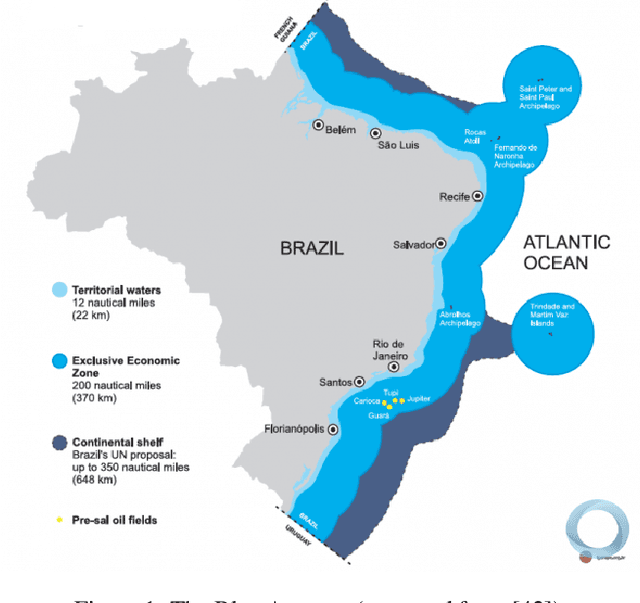
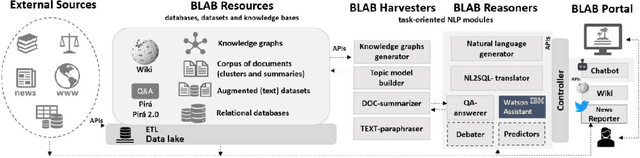
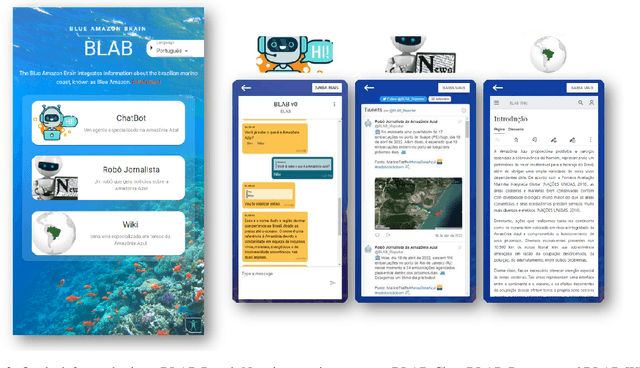
We describe the first steps in the development of an artificial agent focused on the Brazilian maritime territory, a large region within the South Atlantic also known as the Blue Amazon. The "BLue Amazon Brain" (BLAB) integrates a number of services aimed at disseminating information about this region and its importance, functioning as a tool for environmental awareness. The main service provided by BLAB is a conversational facility that deals with complex questions about the Blue Amazon, called BLAB-Chat; its central component is a controller that manages several task-oriented natural language processing modules (e.g., question answering and summarizer systems). These modules have access to an internal data lake as well as to third-party databases. A news reporter (BLAB-Reporter) and a purposely-developed wiki (BLAB-Wiki) are also part of the BLAB service architecture. In this paper, we describe our current version of BLAB's architecture (interface, backend, web services, NLP modules, and resources) and comment on the challenges we have faced so far, such as the lack of training data and the scattered state of domain information. Solving these issues presents a considerable challenge in the development of artificial intelligence for technical domains.
Pirá: A Bilingual Portuguese-English Dataset for Question-Answering about the Ocean
Feb 04, 2022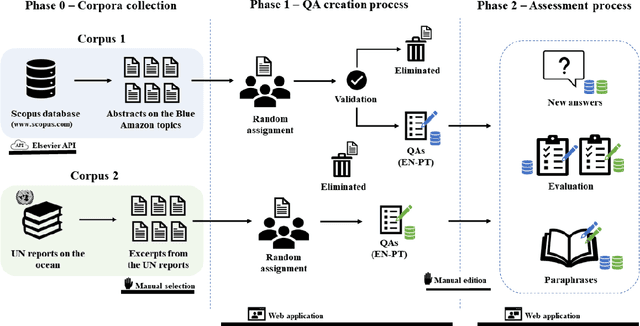
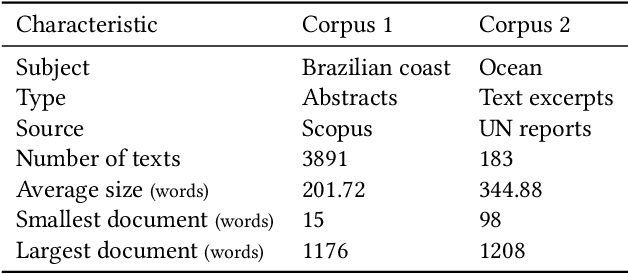
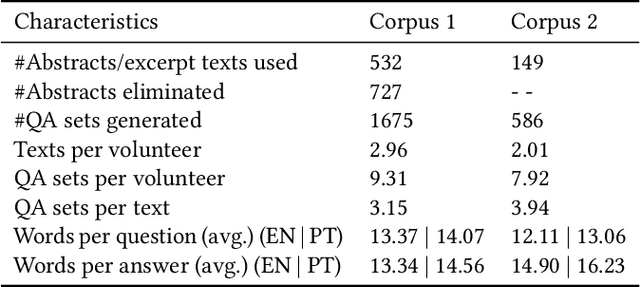
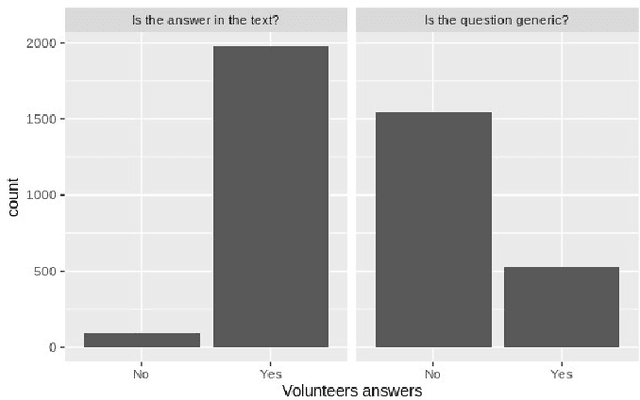
Current research in natural language processing is highly dependent on carefully produced corpora. Most existing resources focus on English; some resources focus on languages such as Chinese and French; few resources deal with more than one language. This paper presents the Pir\'a dataset, a large set of questions and answers about the ocean and the Brazilian coast both in Portuguese and English. Pir\'a is, to the best of our knowledge, the first QA dataset with supporting texts in Portuguese, and, perhaps more importantly, the first bilingual QA dataset that includes this language. The Pir\'a dataset consists of 2261 properly curated question/answer (QA) sets in both languages. The QA sets were manually created based on two corpora: abstracts related to the Brazilian coast and excerpts of United Nation reports about the ocean. The QA sets were validated in a peer-review process with the dataset contributors. We discuss some of the advantages as well as limitations of Pir\'a, as this new resource can support a set of tasks in NLP such as question-answering, information retrieval, and machine translation.
* https://github.com/C4AI/Pira