 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarks for Pirá 2.0, a Reading Comprehension Dataset about the Ocean, the Brazilian Coast, and Climate Change
Sep 19, 2023Pir\'a is a reading comprehension dataset focused on the ocean, the Brazilian coast, and climate change, built from a collection of scientific abstracts and reports on these topics. This dataset represents a versatile language resource, particularly useful for testing the ability of current machine learning models to acquire expert scientific knowledge. Despite its potential, a detailed set of baselines has not yet been developed for Pir\'a. By creating these baselines, researchers can more easily utilize Pir\'a as a resource for testing machine learning models across a wide range of question answering tasks. In this paper, we define six benchmarks over the Pir\'a dataset, covering closed generative question answering, machine reading comprehension, information retrieval, open question answering, answer triggering, and multiple choice question answering. As part of this effort, we have also produced a curated version of the original dataset, where we fixed a number of grammar issues, repetitions, and other shortcomings. Furthermore, the dataset has been extended in several new directions, so as to face the aforementioned benchmarks: translation of supporting texts from English into Portuguese, classification labels for answerability, automatic paraphrases of questions and answers, and multiple choice candidates. The results described in this paper provide several points of reference for researchers interested in exploring the challenges provided by the Pir\'a dataset.
A Physics-Informed Neural Network to Model Port Channels
Dec 20, 2022
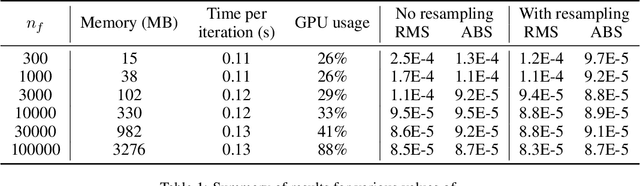


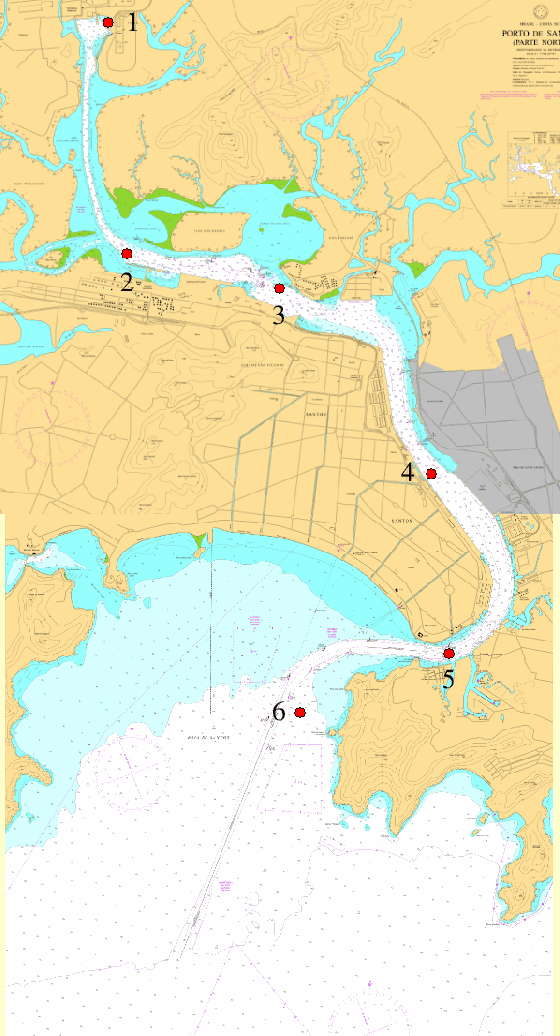
We describe a Physics-Informed Neural Network (PINN) that simulates the flow induced by the astronomical tide in a synthetic port channel, with dimensions based on the Santos - S\~ao Vicente - Bertioga Estuarine System. PINN models aim to combine the knowledge of physical systems and data-driven machine learning models. This is done by training a neural network to minimize the residuals of the governing equations in sample points. In this work, our flow is governed by the Navier-Stokes equations with some approximations. There are two main novelties in this paper. First, we design our model to assume that the flow is periodic in time, which is not feasible in conventional simulation methods. Second, we evaluate the benefit of resampling the function evaluation points during training, which has a near zero computational cost and has been verified to improve the final model, especially for small batch sizes. Finally, we discuss some limitations of the approximations used in the Navier-Stokes equations regarding the modeling of turbulence and how it interacts with PINNs.
The BLue Amazon Brain : A Modular Architecture of Services about the Brazilian Maritime Territory
Sep 06, 2022
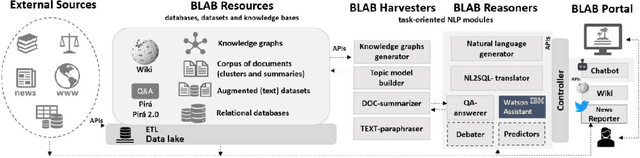
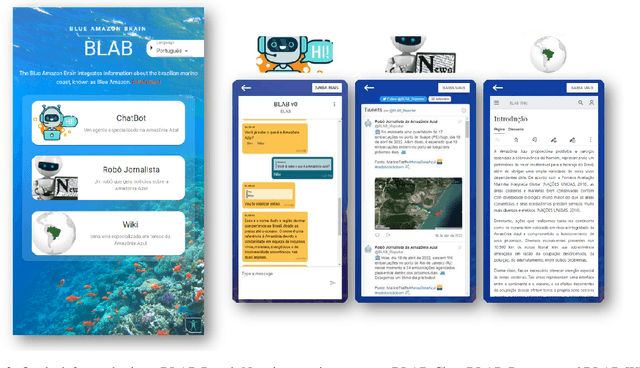
We describe the first steps in the development of an artificial agent focused on the Brazilian maritime territory, a large region within the South Atlantic also known as the Blue Amazon. The "BLue Amazon Brain" (BLAB) integrates a number of services aimed at disseminating information about this region and its importance, functioning as a tool for environmental awareness. The main service provided by BLAB is a conversational facility that deals with complex questions about the Blue Amazon, called BLAB-Chat; its central component is a controller that manages several task-oriented natural language processing modules (e.g., question answering and summarizer systems). These modules have access to an internal data lake as well as to third-party databases. A news reporter (BLAB-Reporter) and a purposely-developed wiki (BLAB-Wiki) are also part of the BLAB service architecture. In this paper, we describe our current version of BLAB's architecture (interface, backend, web services, NLP modules, and resources) and comment on the challenges we have faced so far, such as the lack of training data and the scattered state of domain information. Solving these issues presents a considerable challenge in the development of artificial intelligence for technical domains.
Modeling Oceanic Variables with Dynamic Graph Neural Networks
Jun 25, 2022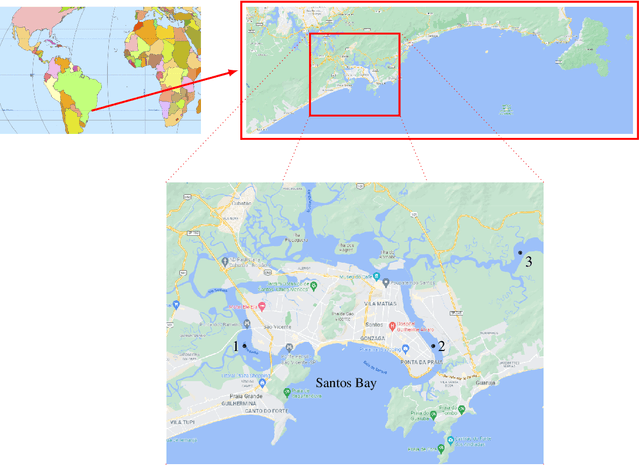


Researchers typically resort to numerical methods to understand and predict ocean dynamics, a key task in mastering environmental phenomena. Such methods may not be suitable in scenarios where the topographic map is complex, knowledge about the underlying processes is incomplete, or the application is time critical. On the other hand, if ocean dynamics are observed, they can be exploited by recent machine learning methods. In this paper we describe a data-driven method to predict environmental variables such as current velocity and sea surface height in the region of Santos-Sao Vicente-Bertioga Estuarine System in the southeastern coast of Brazil. Our model exploits both temporal and spatial inductive biases by joining state-of-the-art sequence models (LSTM and Transformers) and relational models (Graph Neural Networks) in an end-to-end framework that learns both the temporal features and the spatial relationship shared among observation sites. We compare our results with the Santos Operational Forecasting System (SOFS). Experiments show that better results are attained by our model, while maintaining flexibility and little domain knowledge dependency.
Pirá: A Bilingual Portuguese-English Dataset for Question-Answering about the Ocean
Feb 04, 2022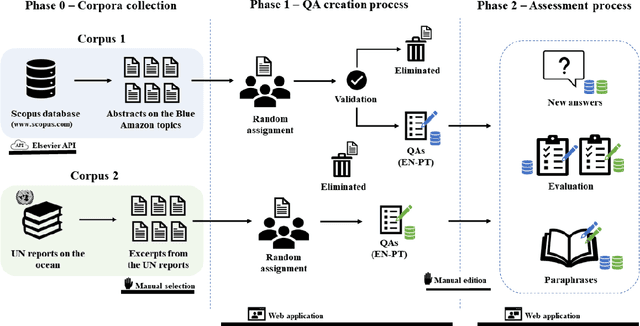
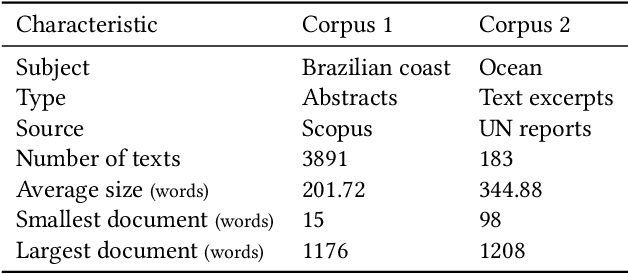
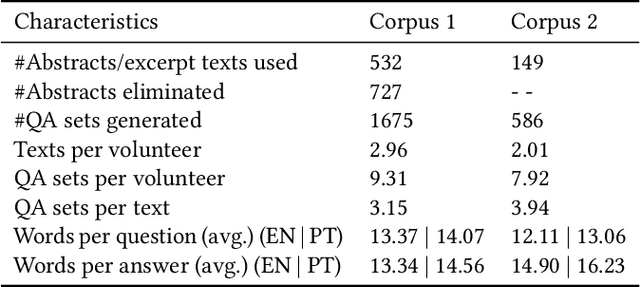
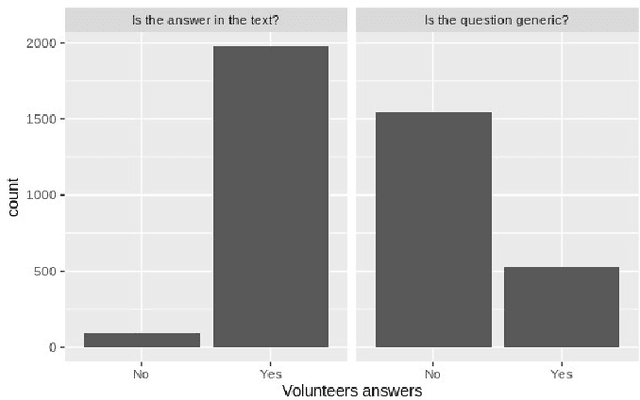
Current research in natural language processing is highly dependent on carefully produced corpora. Most existing resources focus on English; some resources focus on languages such as Chinese and French; few resources deal with more than one language. This paper presents the Pir\'a dataset, a large set of questions and answers about the ocean and the Brazilian coast both in Portuguese and English. Pir\'a is, to the best of our knowledge, the first QA dataset with supporting texts in Portuguese, and, perhaps more importantly, the first bilingual QA dataset that includes this language. The Pir\'a dataset consists of 2261 properly curated question/answer (QA) sets in both languages. The QA sets were manually created based on two corpora: abstracts related to the Brazilian coast and excerpts of United Nation reports about the ocean. The QA sets were validated in a peer-review process with the dataset contributors. We discuss some of the advantages as well as limitations of Pir\'a, as this new resource can support a set of tasks in NLP such as question-answering, information retrieval, and machine translation.
* https://github.com/C4AI/Pira