 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForward-PECVaR Algorithm: Exact Evaluation for CVaR SSPs
Mar 01, 2023The Stochastic Shortest Path (SSP) problem models probabilistic sequential-decision problems where an agent must pursue a goal while minimizing a cost function. Because of the probabilistic dynamics, it is desired to have a cost function that considers risk. Conditional Value at Risk (CVaR) is a criterion that allows modeling an arbitrary level of risk by considering the expectation of a fraction $\alpha$ of worse trajectories. Although an optimal policy is non-Markovian, solutions of CVaR-SSP can be found approximately with Value Iteration based algorithms such as CVaR Value Iteration with Linear Interpolation (CVaRVIQ) and CVaR Value Iteration via Quantile Representation (CVaRVILI). These type of solutions depends on the algorithm's parameters such as the number of atoms and $\alpha_0$ (the minimum $\alpha$). To compare the policies returned by these algorithms, we need a way to exactly evaluate stationary policies of CVaR-SSPs. Although there is an algorithm that evaluates these policies, this only works on problems with uniform costs. In this paper, we propose a new algorithm, Forward-PECVaR (ForPECVaR), that evaluates exactly stationary policies of CVaR-SSPs with non-uniform costs. We evaluate empirically CVaR Value Iteration algorithms that found solutions approximately regarding their quality compared with the exact solution, and the influence of the algorithm parameters in the quality and scalability of the solutions. Experiments in two domains show that it is important to use an $\alpha_0$ smaller than the $\alpha$ target and an adequate number of atoms to obtain a good approximation.
Pirá: A Bilingual Portuguese-English Dataset for Question-Answering about the Ocean
Feb 04, 2022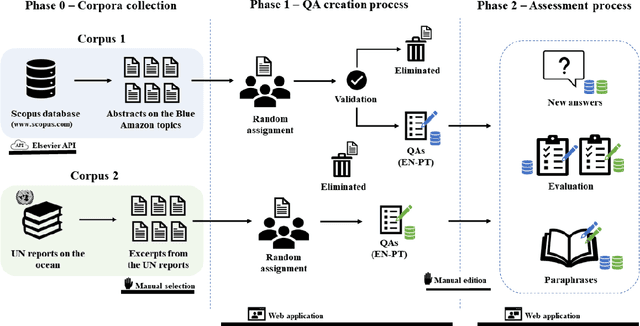
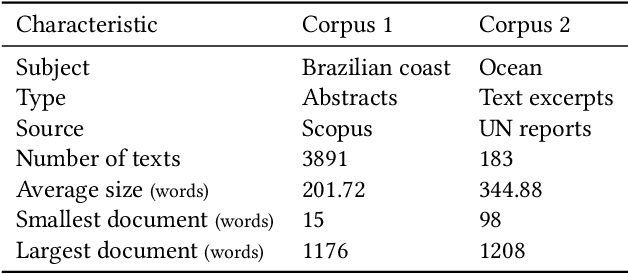
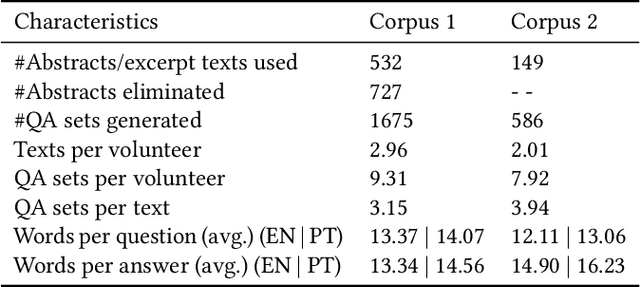
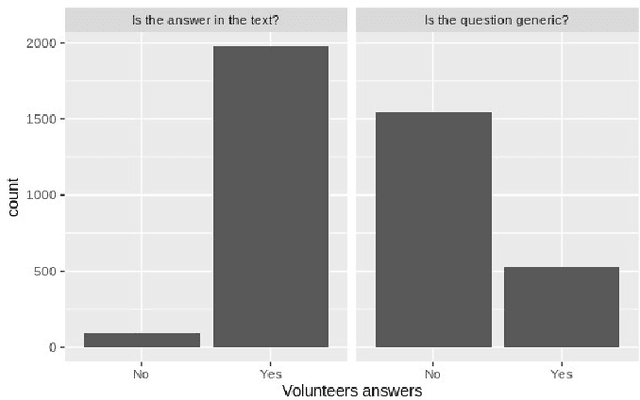
Current research in natural language processing is highly dependent on carefully produced corpora. Most existing resources focus on English; some resources focus on languages such as Chinese and French; few resources deal with more than one language. This paper presents the Pir\'a dataset, a large set of questions and answers about the ocean and the Brazilian coast both in Portuguese and English. Pir\'a is, to the best of our knowledge, the first QA dataset with supporting texts in Portuguese, and, perhaps more importantly, the first bilingual QA dataset that includes this language. The Pir\'a dataset consists of 2261 properly curated question/answer (QA) sets in both languages. The QA sets were manually created based on two corpora: abstracts related to the Brazilian coast and excerpts of United Nation reports about the ocean. The QA sets were validated in a peer-review process with the dataset contributors. We discuss some of the advantages as well as limitations of Pir\'a, as this new resource can support a set of tasks in NLP such as question-answering, information retrieval, and machine translation.
* https://github.com/C4AI/Pira