 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarks for Pirá 2.0, a Reading Comprehension Dataset about the Ocean, the Brazilian Coast, and Climate Change
Sep 19, 2023Pir\'a is a reading comprehension dataset focused on the ocean, the Brazilian coast, and climate change, built from a collection of scientific abstracts and reports on these topics. This dataset represents a versatile language resource, particularly useful for testing the ability of current machine learning models to acquire expert scientific knowledge. Despite its potential, a detailed set of baselines has not yet been developed for Pir\'a. By creating these baselines, researchers can more easily utilize Pir\'a as a resource for testing machine learning models across a wide range of question answering tasks. In this paper, we define six benchmarks over the Pir\'a dataset, covering closed generative question answering, machine reading comprehension, information retrieval, open question answering, answer triggering, and multiple choice question answering. As part of this effort, we have also produced a curated version of the original dataset, where we fixed a number of grammar issues, repetitions, and other shortcomings. Furthermore, the dataset has been extended in several new directions, so as to face the aforementioned benchmarks: translation of supporting texts from English into Portuguese, classification labels for answerability, automatic paraphrases of questions and answers, and multiple choice candidates. The results described in this paper provide several points of reference for researchers interested in exploring the challenges provided by the Pir\'a dataset.
Pirá: A Bilingual Portuguese-English Dataset for Question-Answering about the Ocean
Feb 04, 2022
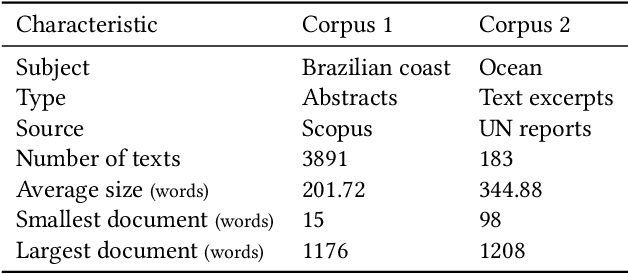
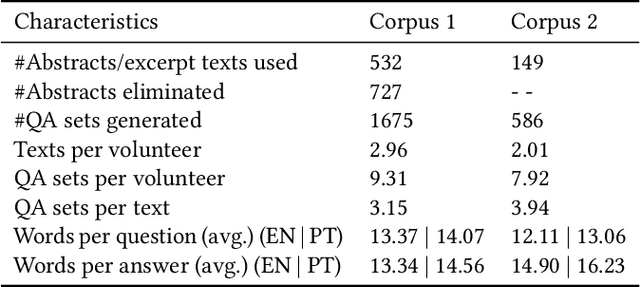
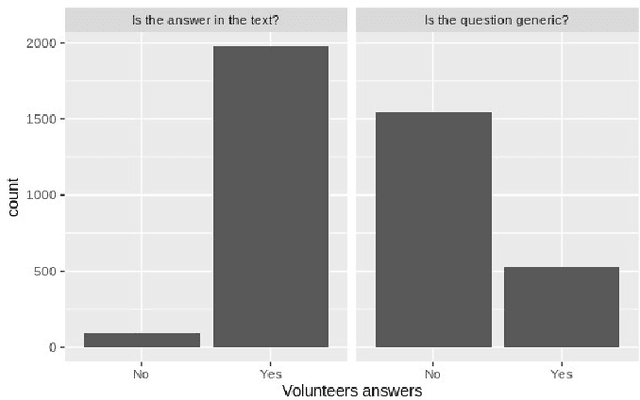
Current research in natural language processing is highly dependent on carefully produced corpora. Most existing resources focus on English; some resources focus on languages such as Chinese and French; few resources deal with more than one language. This paper presents the Pir\'a dataset, a large set of questions and answers about the ocean and the Brazilian coast both in Portuguese and English. Pir\'a is, to the best of our knowledge, the first QA dataset with supporting texts in Portuguese, and, perhaps more importantly, the first bilingual QA dataset that includes this language. The Pir\'a dataset consists of 2261 properly curated question/answer (QA) sets in both languages. The QA sets were manually created based on two corpora: abstracts related to the Brazilian coast and excerpts of United Nation reports about the ocean. The QA sets were validated in a peer-review process with the dataset contributors. We discuss some of the advantages as well as limitations of Pir\'a, as this new resource can support a set of tasks in NLP such as question-answering, information retrieval, and machine translation.
* https://github.com/C4AI/Pira