Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Computational Architectures for Automated Journalism
Paper and Code
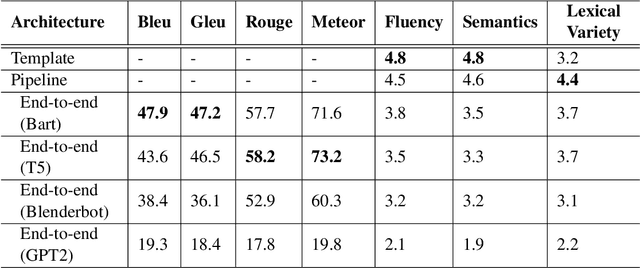
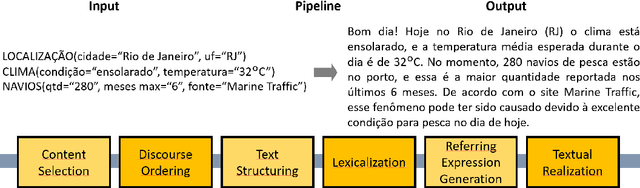
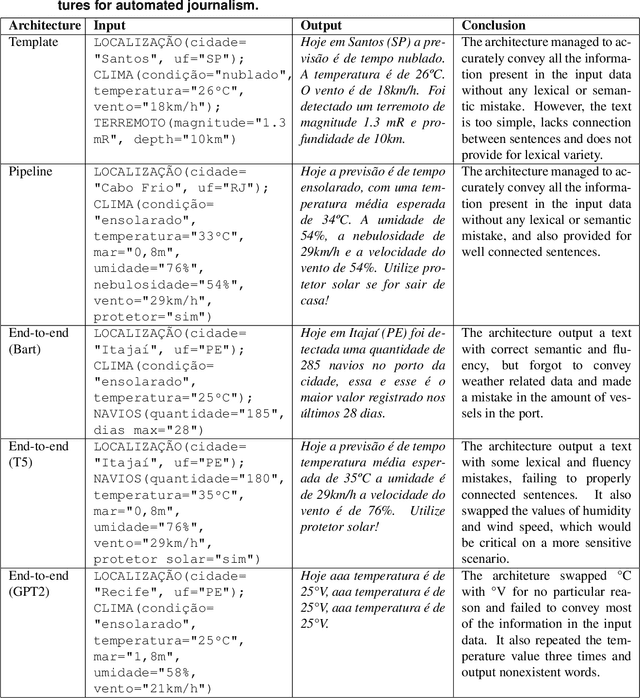
The majority of NLG systems have been designed following either a template-based or a pipeline-based architecture. Recent neural models for data-to-text generation have been proposed with an end-to-end deep learning flavor, which handles non-linguistic input in natural language without explicit intermediary representations. This study compares the most often employed methods for generating Brazilian Portuguese texts from structured data. Results suggest that explicit intermediate steps in the generation process produce better texts than the ones generated by neural end-to-end architectures, avoiding data hallucination while better generalizing to unseen inputs. Code and corpus are publicly available.
* Accepted at the 19th National Meeting on Artificial and Computational
Intelligence (ENIAC 2022)
View paper on