 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Exploiting Twitter as Source of Large Corpora of Weakly Similar Pairs for Semantic Sentence Embeddings
Oct 05, 2021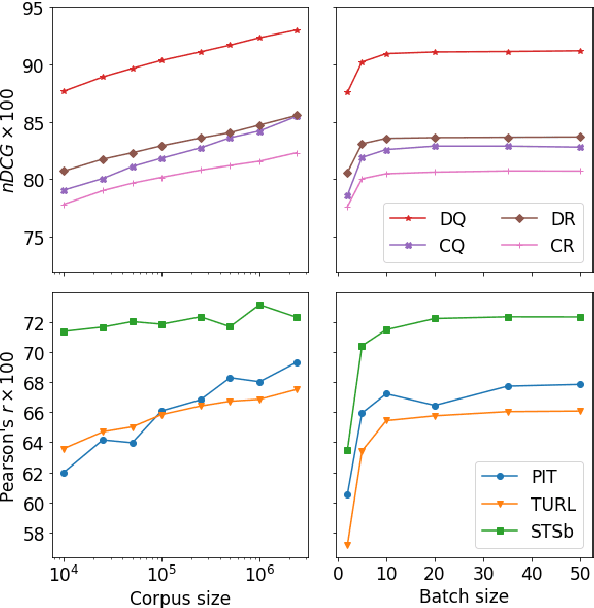

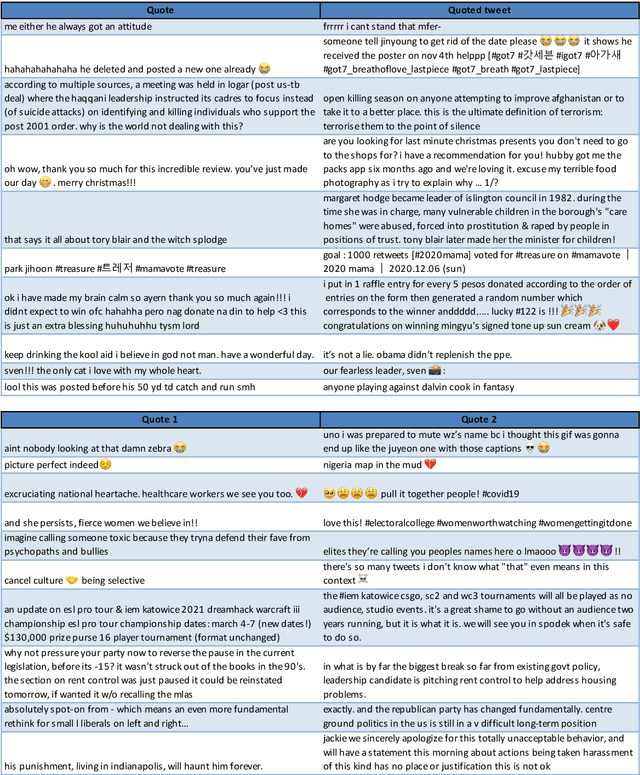
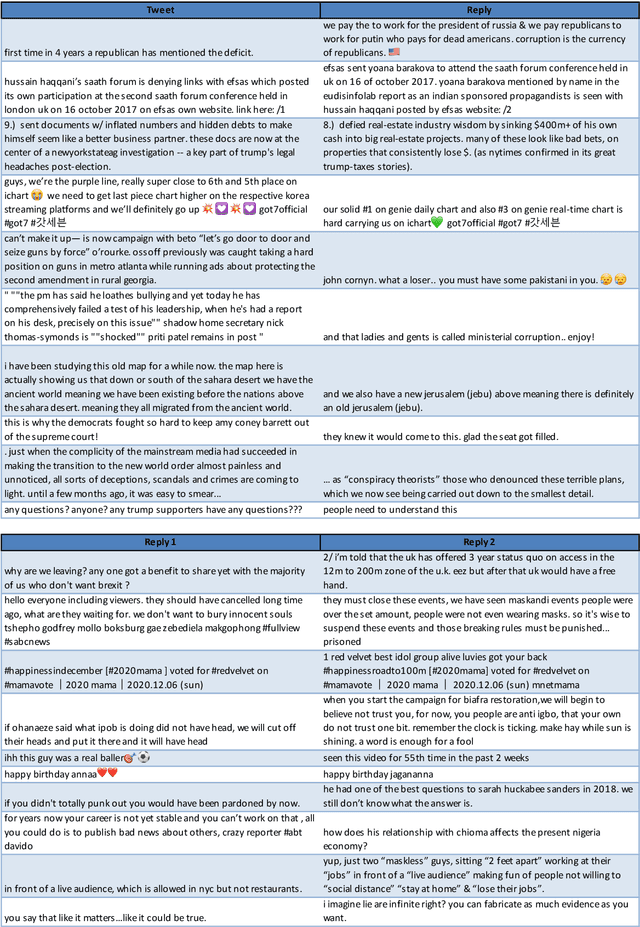
Semantic sentence embeddings are usually supervisedly built minimizing distances between pairs of embeddings of sentences labelled as semantically similar by annotators. Since big labelled datasets are rare, in particular for non-English languages, and expensive, recent studies focus on unsupervised approaches that require not-paired input sentences. We instead propose a language-independent approach to build large datasets of pairs of informal texts weakly similar, without manual human effort, exploiting Twitter's intrinsic powerful signals of relatedness: replies and quotes of tweets. We use the collected pairs to train a Transformer model with triplet-like structures, and we test the generated embeddings on Twitter NLP similarity tasks (PIT and TURL) and STSb. We also introduce four new sentence ranking evaluation benchmarks of informal texts, carefully extracted from the initial collections of tweets, proving not only that our best model learns classical Semantic Textual Similarity, but also excels on tasks where pairs of sentences are not exact paraphrases. Ablation studies reveal how increasing the corpus size influences positively the results, even at 2M samples, suggesting that bigger collections of Tweets still do not contain redundant information about semantic similarities.
EFSG: Evolutionary Fooling Sentences Generator
Oct 12, 2020


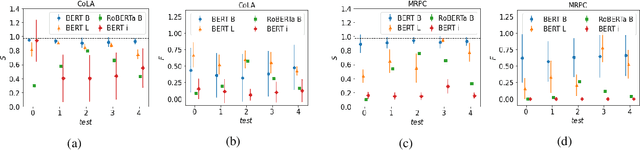
Large pre-trained language representation models (LMs) have recently collected a huge number of successes in many NLP tasks. In 2018 BERT, and later its successors (e.g. RoBERTa), obtained state-of-the-art results in classical benchmark tasks, such as GLUE benchmark. After that, works about adversarial attacks have been published to test their generalization proprieties and robustness. In this work, we design Evolutionary Fooling Sentences Generator (EFSG), a model- and task-agnostic adversarial attack algorithm built using an evolutionary approach to generate false-positive sentences for binary classification tasks. We successfully apply EFSG to CoLA and MRPC tasks, on BERT and RoBERTa, comparing performances. Results prove the presence of weak spots in state-of-the-art LMs. We finally test adversarial training as a data augmentation defence approach against EFSG, obtaining stronger improved models with no loss of accuracy when tested on the original datasets.