 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensory robustness through top-down feedback and neural stochasticity in recurrent vision models
Aug 09, 2025Biological systems leverage top-down feedback for visual processing, yet most artificial vision models succeed in image classification using purely feedforward or recurrent architectures, calling into question the functional significance of descending cortical pathways. Here, we trained convolutional recurrent neural networks (ConvRNN) on image classification in the presence or absence of top-down feedback projections to elucidate the specific computational contributions of those feedback pathways. We found that ConvRNNs with top-down feedback exhibited remarkable speed-accuracy trade-off and robustness to noise perturbations and adversarial attacks, but only when they were trained with stochastic neural variability, simulated by randomly silencing single units via dropout. By performing detailed analyses to identify the reasons for such benefits, we observed that feedback information substantially shaped the representational geometry of the post-integration layer, combining the bottom-up and top-down streams, and this effect was amplified by dropout. Moreover, feedback signals coupled with dropout optimally constrained network activity onto a low-dimensional manifold and encoded object information more efficiently in out-of-distribution regimes, with top-down information stabilizing the representational dynamics at the population level. Together, these findings uncover a dual mechanism for resilient sensory coding. On the one hand, neural stochasticity prevents unit-level co-adaptation albeit at the cost of more chaotic dynamics. On the other hand, top-down feedback harnesses high-level information to stabilize network activity on compact low-dimensional manifolds.
Multimodal Parameter-Efficient Few-Shot Class Incremental Learning
Mar 08, 2023

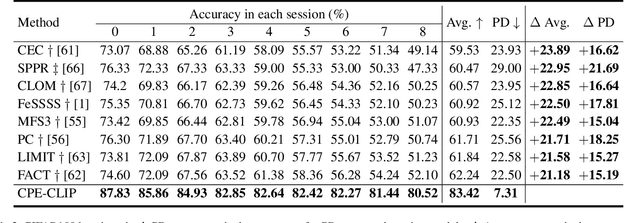

Few-Shot Class Incremental Learning (FSCIL) is a challenging continual learning task, where limited training examples are available during several learning sessions. To succeed in this task, it is necessary to avoid over-fitting new classes caused by biased distributions in the few-shot training sets. The general approach to address this issue involves enhancing the representational capability of a pre-defined backbone architecture by adding special modules for backward compatibility with older classes. However, this approach has not yet solved the dilemma of ensuring high classification accuracy over time while reducing the gap between the performance obtained on larger training sets and the smaller ones. In this work, we propose an alternative approach called Continual Parameter-Efficient CLIP (CPE-CLIP) to reduce the loss of information between different learning sessions. Instead of adapting additional modules to address information loss, we leverage the vast knowledge acquired by CLIP in large-scale pre-training and its effectiveness in generalizing to new concepts. Our approach is multimodal and parameter-efficient, relying on learnable prompts for both the language and vision encoders to enable transfer learning across sessions. We also introduce prompt regularization to improve performance and prevent forgetting. Our experimental results demonstrate that CPE-CLIP significantly improves FSCIL performance compared to state-of-the-art proposals while also drastically reducing the number of learnable parameters and training costs.
Amortized Bayesian model comparison with evidential deep learning
Apr 25, 2020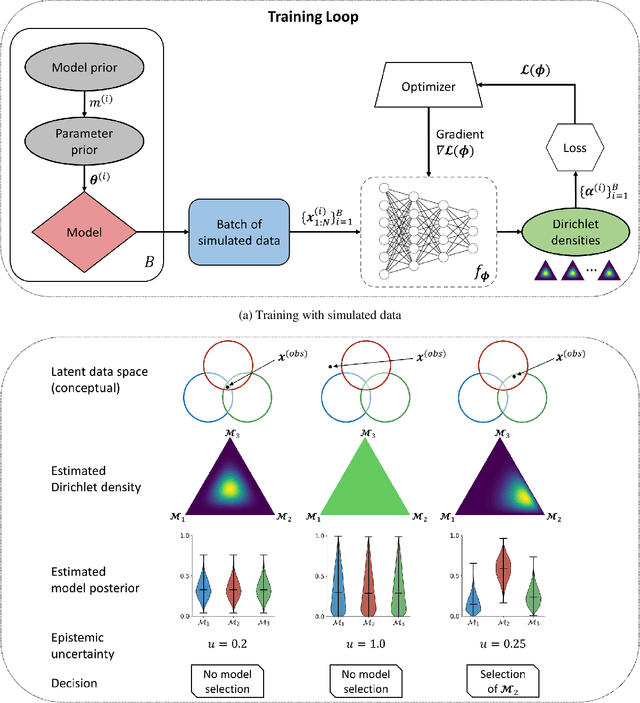
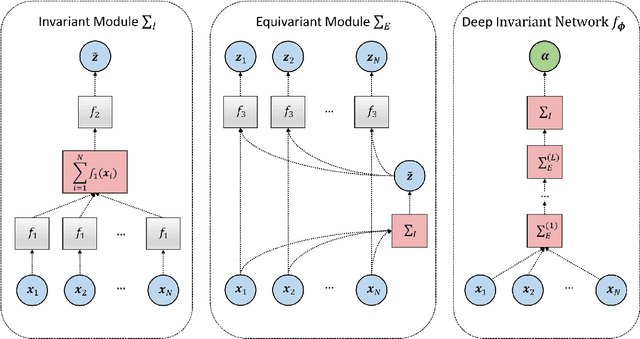
Comparing competing mathematical models of complex natural processes is a shared goal among many branches of science. The Bayesian probabilistic framework offers a principled way to perform model comparison and extract useful metrics for guiding decisions. However, many interesting models are intractable with standard Bayesian methods, as they lack a closed-form likelihood function or the likelihood is computationally too expensive to evaluate. With this work, we propose a novel method for performing Bayesian model comparison using specialized deep learning architectures. Our method is purely simulation-based and circumvents the step of explicitly fitting all alternative models under consideration to each observed dataset. Moreover, it involves no hand-crafted summary statistics of the data and is designed to amortize the cost of simulation over multiple models and observable datasets. This makes the method applicable in scenarios where model fit needs to be assessed for a large number of datasets, so that per-dataset inference is practically infeasible. Finally, we propose a novel way to measure epistemic uncertainty in model comparison problems. We argue that this measure of epistemic uncertainty provides a unique proxy to quantify absolute evidence even in a framework which assumes that the true data-generating model is within a finite set of candidate models.