 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerfDojo: Automated ML Library Generation for Heterogeneous Architectures
Nov 05, 2025



The increasing complexity of machine learning models and the proliferation of diverse hardware architectures (CPUs, GPUs, accelerators) make achieving optimal performance a significant challenge. Heterogeneity in instruction sets, specialized kernel requirements for different data types and model features (e.g., sparsity, quantization), and architecture-specific optimizations complicate performance tuning. Manual optimization is resource-intensive, while existing automatic approaches often rely on complex hardware-specific heuristics and uninterpretable intermediate representations, hindering performance portability. We introduce PerfLLM, a novel automatic optimization methodology leveraging Large Language Models (LLMs) and Reinforcement Learning (RL). Central to this is PerfDojo, an environment framing optimization as an RL game using a human-readable, mathematically-inspired code representation that guarantees semantic validity through transformations. This allows effective optimization without prior hardware knowledge, facilitating both human analysis and RL agent training. We demonstrate PerfLLM's ability to achieve significant performance gains across diverse CPU (x86, Arm, RISC-V) and GPU architectures.
Psychologically Enhanced AI Agents
Sep 04, 2025



We introduce MBTI-in-Thoughts, a framework for enhancing the effectiveness of Large Language Model (LLM) agents through psychologically grounded personality conditioning. Drawing on the Myers-Briggs Type Indicator (MBTI), our method primes agents with distinct personality archetypes via prompt engineering, enabling control over behavior along two foundational axes of human psychology, cognition and affect. We show that such personality priming yields consistent, interpretable behavioral biases across diverse tasks: emotionally expressive agents excel in narrative generation, while analytically primed agents adopt more stable strategies in game-theoretic settings. Our framework supports experimenting with structured multi-agent communication protocols and reveals that self-reflection prior to interaction improves cooperation and reasoning quality. To ensure trait persistence, we integrate the official 16Personalities test for automated verification. While our focus is on MBTI, we show that our approach generalizes seamlessly to other psychological frameworks such as Big Five, HEXACO, or Enneagram. By bridging psychological theory and LLM behavior design, we establish a foundation for psychologically enhanced AI agents without any fine-tuning.
Benchmarking Filtered Approximate Nearest Neighbor Search Algorithms on Transformer-based Embedding Vectors
Jul 29, 2025Advances in embedding models for text, image, audio, and video drive progress across multiple domains, including retrieval-augmented generation, recommendation systems, vehicle/person reidentification, and face recognition. Many applications in these domains require an efficient method to retrieve items that are close to a given query in the embedding space while satisfying a filter condition based on the item's attributes, a problem known as Filtered Approximate Nearest Neighbor Search (FANNS). In this work, we present a comprehensive survey and taxonomy of FANNS methods and analyze how they are benchmarked in the literature. By doing so, we identify a key challenge in the current FANNS landscape: the lack of diverse and realistic datasets, particularly ones derived from the latest transformer-based text embedding models. To address this, we introduce a novel dataset consisting of embedding vectors for the abstracts of over 2.7 million research articles from the arXiv repository, accompanied by 11 real-world attributes such as authors and categories. We benchmark a wide range of FANNS methods on our novel dataset and find that each method has distinct strengths and limitations; no single approach performs best across all scenarios. ACORN, for example, supports various filter types and performs reliably across dataset scales but is often outperformed by more specialized methods. SeRF shows excellent performance for range filtering on ordered attributes but cannot handle categorical attributes. Filtered-DiskANN and UNG excel on the medium-scale dataset but fail on the large-scale dataset, highlighting the challenge posed by transformer-based embeddings, which are often more than an order of magnitude larger than earlier embeddings. We conclude that no universally best method exists.
Fortify Your Foundations: Practical Privacy and Security for Foundation Model Deployments In The Cloud
Oct 08, 2024



Foundation Models (FMs) display exceptional performance in tasks such as natural language processing and are being applied across a growing range of disciplines. Although typically trained on large public datasets, FMs are often fine-tuned or integrated into Retrieval-Augmented Generation (RAG) systems, which rely on private data. This access, along with their size and costly training, heightens the risk of intellectual property theft. Moreover, multimodal FMs may expose sensitive information. In this work, we examine the FM threat model and discuss the practicality and comprehensiveness of various approaches for securing against them, such as ML-based methods and trusted execution environments (TEEs). We demonstrate that TEEs offer an effective balance between strong security properties, usability, and performance. Specifically, we present a solution achieving less than 10\% overhead versus bare metal for the full Llama2 7B and 13B inference pipelines running inside \intel\ SGX and \intel\ TDX. We also share our configuration files and insights from our implementation. To our knowledge, our work is the first to show the practicality of TEEs for securing FMs.
Multi-Head RAG: Solving Multi-Aspect Problems with LLMs
Jun 07, 2024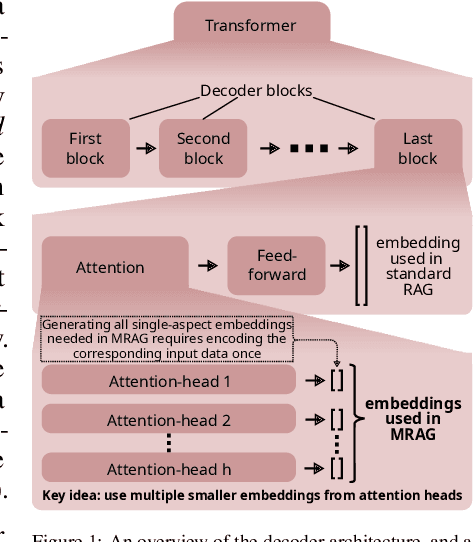

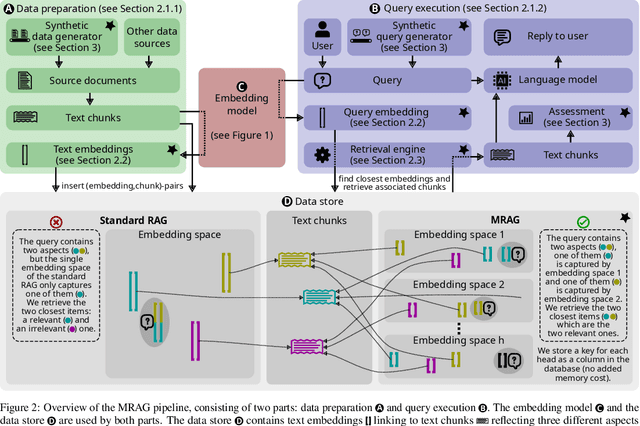

Retrieval Augmented Generation (RAG) enhances the abilities of Large Language Models (LLMs) by enabling the retrieval of documents into the LLM context to provide more accurate and relevant responses. Existing RAG solutions do not focus on queries that may require fetching multiple documents with substantially different contents. Such queries occur frequently, but are challenging because the embeddings of these documents may be distant in the embedding space, making it hard to retrieve them all. This paper introduces Multi-Head RAG (MRAG), a novel scheme designed to address this gap with a simple yet powerful idea: leveraging activations of Transformer's multi-head attention layer, instead of the decoder layer, as keys for fetching multi-aspect documents. The driving motivation is that different attention heads can learn to capture different data aspects. Harnessing the corresponding activations results in embeddings that represent various facets of data items and queries, improving the retrieval accuracy for complex queries. We provide an evaluation methodology and metrics, synthetic datasets, and real-world use cases to demonstrate MRAG's effectiveness, showing improvements of up to 20% in relevance over standard RAG baselines. MRAG can be seamlessly integrated with existing RAG frameworks and benchmarking tools like RAGAS as well as different classes of data stores.