 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-based Surgical Tool-tip and Keypoint Tracking using Multi-frame Context-driven Deep Learning Models
Jan 30, 2025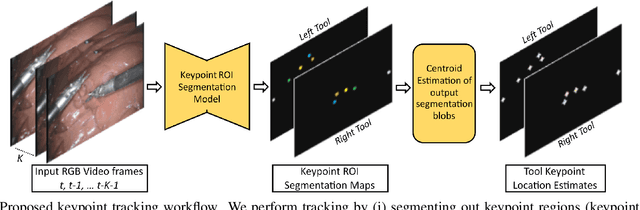

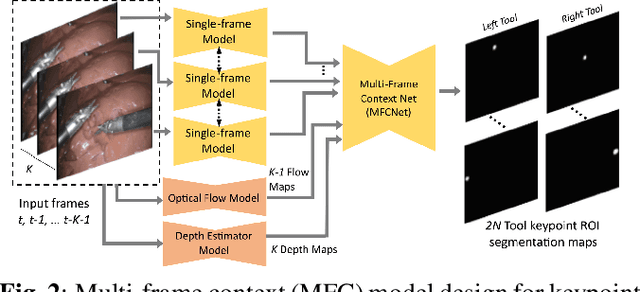
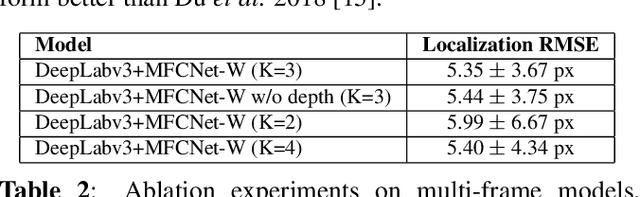
Automated tracking of surgical tool keypoints in robotic surgery videos is an essential task for various downstream use cases such as skill assessment, expertise assessment, and the delineation of safety zones. In recent years, the explosion of deep learning for vision applications has led to many works in surgical instrument segmentation, while lesser focus has been on tracking specific tool keypoints, such as tool tips. In this work, we propose a novel, multi-frame context-driven deep learning framework to localize and track tool keypoints in surgical videos. We train and test our models on the annotated frames from the 2015 EndoVis Challenge dataset, resulting in state-of-the-art performance. By leveraging sophisticated deep learning models and multi-frame context, we achieve 90\% keypoint detection accuracy and a localization RMS error of 5.27 pixels. Results on a self-annotated JIGSAWS dataset with more challenging scenarios also show that the proposed multi-frame models can accurately track tool-tip and tool-base keypoints, with ${<}4.2$-pixel RMS error overall. Such a framework paves the way for accurately tracking surgical instrument keypoints, enabling further downstream use cases. Project and dataset webpage: https://tinyurl.com/mfc-tracker
Physical Interaction as Communication: Learning Robot Objectives Online from Human Corrections
Jul 06, 2021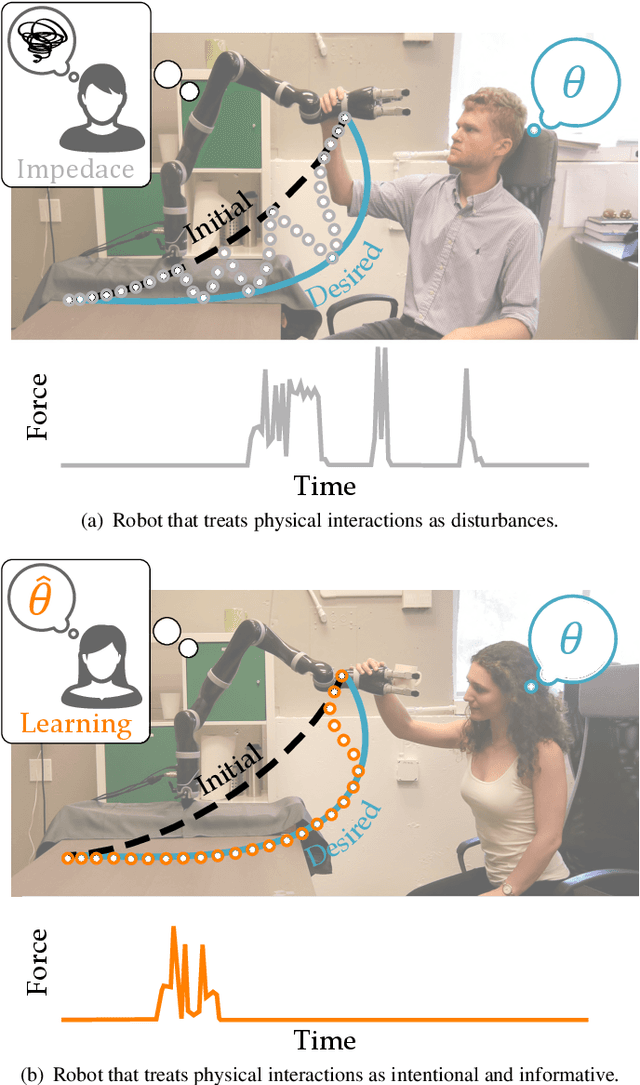
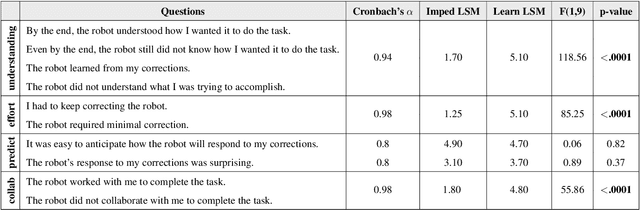

When a robot performs a task next to a human, physical interaction is inevitable: the human might push, pull, twist, or guide the robot. The state-of-the-art treats these interactions as disturbances that the robot should reject or avoid. At best, these robots respond safely while the human interacts; but after the human lets go, these robots simply return to their original behavior. We recognize that physical human-robot interaction (pHRI) is often intentional -- the human intervenes on purpose because the robot is not doing the task correctly. In this paper, we argue that when pHRI is intentional it is also informative: the robot can leverage interactions to learn how it should complete the rest of its current task even after the person lets go. We formalize pHRI as a dynamical system, where the human has in mind an objective function they want the robot to optimize, but the robot does not get direct access to the parameters of this objective -- they are internal to the human. Within our proposed framework human interactions become observations about the true objective. We introduce approximations to learn from and respond to pHRI in real-time. We recognize that not all human corrections are perfect: often users interact with the robot noisily, and so we improve the efficiency of robot learning from pHRI by reducing unintended learning. Finally, we conduct simulations and user studies on a robotic manipulator to compare our proposed approach to the state-of-the-art. Our results indicate that learning from pHRI leads to better task performance and improved human satisfaction.
Enabling Robots to Infer how End-Users Teach and Learn through Human-Robot Interaction
Feb 02, 2019
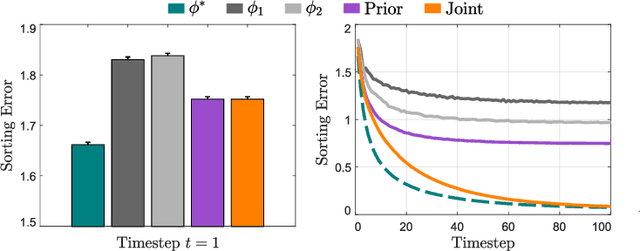
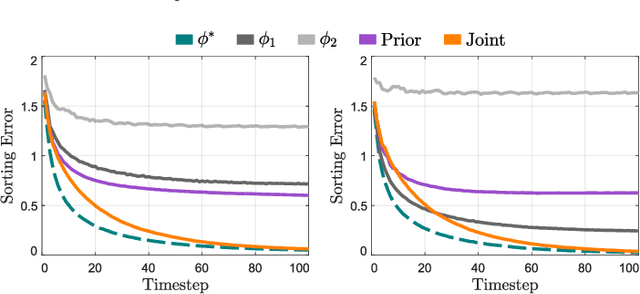

During human-robot interaction (HRI), we want the robot to understand us, and we want to intuitively understand the robot. In order to communicate with and understand the robot, we can leverage interactions, where the human and robot observe each other's behavior. However, it is not always clear how the human and robot should interpret these actions: a given interaction might mean several different things. Within today's state-of-the-art, the robot assigns a single interaction strategy to the human, and learns from or teaches the human according to this fixed strategy. Instead, we here recognize that different users interact in different ways, and so one size does not fit all. Therefore, we argue that the robot should maintain a distribution over the possible human interaction strategies, and then infer how each individual end-user interacts during the task. We formally define learning and teaching when the robot is uncertain about the human's interaction strategy, and derive solutions to both problems using Bayesian inference. In examples and a benchmark simulation, we show that our personalized approach outperforms standard methods that maintain a fixed interaction strategy.
Including Uncertainty when Learning from Human Corrections
Sep 13, 2018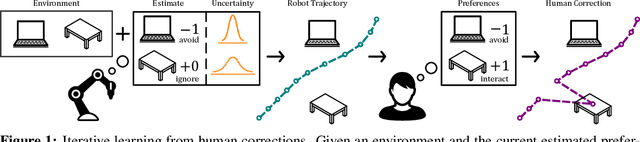


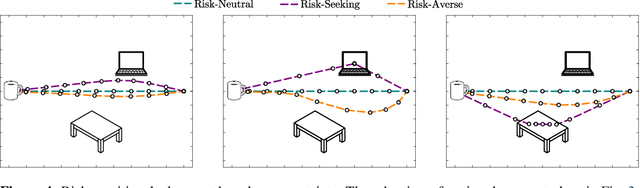
It is difficult for humans to efficiently teach robots how to correctly perform a task. One intuitive solution is for the robot to iteratively learn the human's preferences from corrections, where the human improves the robot's current behavior at each iteration. When learning from corrections, we argue that while the robot should estimate the most likely human preferences, it should also know what it does not know, and integrate this uncertainty as it makes decisions. We advance the state-of-the-art by introducing a Kalman filter for learning from corrections: this approach obtains the uncertainty of the estimated human preferences. Next, we demonstrate how the estimate uncertainty can be leveraged for active learning and risk-sensitive deployment. Our results indicate that obtaining and leveraging uncertainty leads to faster learning from human corrections.
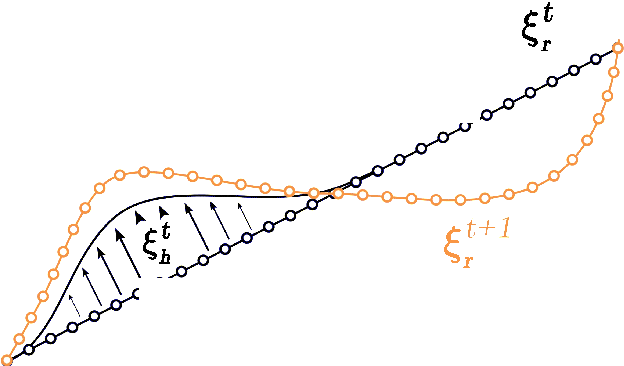
Trajectory Deformations from Physical Human-Robot Interaction
Oct 26, 2017



Robots are finding new applications where physical interaction with a human is necessary: manufacturing, healthcare, and social tasks. Accordingly, the field of physical human-robot interaction (pHRI) has leveraged impedance control approaches, which support compliant interactions between human and robot. However, a limitation of traditional impedance control is that---despite provisions for the human to modify the robot's current trajectory---the human cannot affect the robot's future desired trajectory through pHRI. In this paper, we present an algorithm for physically interactive trajectory deformations which, when combined with impedance control, allows the human to modulate both the actual and desired trajectories of the robot. Unlike related works, our method explicitly deforms the future desired trajectory based on forces applied during pHRI, but does not require constant human guidance. We present our approach and verify that this method is compatible with traditional impedance control. Next, we use constrained optimization to derive the deformation shape. Finally, we describe an algorithm for real time implementation, and perform simulations to test the arbitration parameters. Experimental results demonstrate reduction in the human's effort and improvement in the movement quality when compared to pHRI with impedance control alone.