 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust another copy and paste? Comparing the security vulnerabilities of ChatGPT generated code and StackOverflow answers
Mar 22, 2024

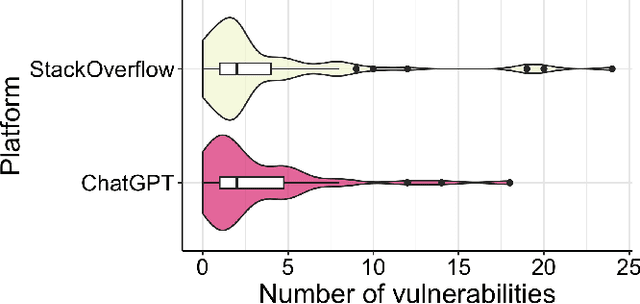
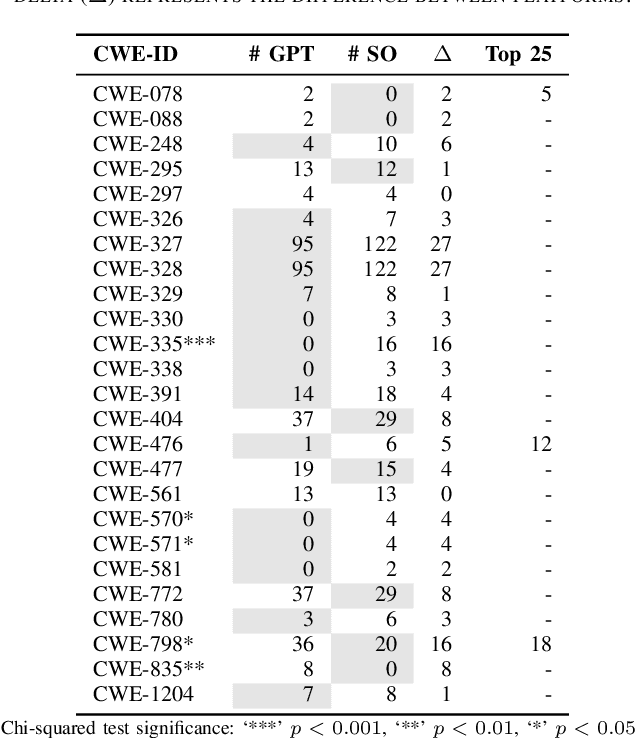
Sonatype's 2023 report found that 97% of developers and security leads integrate generative Artificial Intelligence (AI), particularly Large Language Models (LLMs), into their development process. Concerns about the security implications of this trend have been raised. Developers are now weighing the benefits and risks of LLMs against other relied-upon information sources, such as StackOverflow (SO), requiring empirical data to inform their choice. In this work, our goal is to raise software developers awareness of the security implications when selecting code snippets by empirically comparing the vulnerabilities of ChatGPT and StackOverflow. To achieve this, we used an existing Java dataset from SO with security-related questions and answers. Then, we asked ChatGPT the same SO questions, gathering the generated code for comparison. After curating the dataset, we analyzed the number and types of Common Weakness Enumeration (CWE) vulnerabilities of 108 snippets from each platform using CodeQL. ChatGPT-generated code contained 248 vulnerabilities compared to the 302 vulnerabilities found in SO snippets, producing 20% fewer vulnerabilities with a statistically significant difference. Additionally, ChatGPT generated 19 types of CWE, fewer than the 22 found in SO. Our findings suggest developers are under-educated on insecure code propagation from both platforms, as we found 274 unique vulnerabilities and 25 types of CWE. Any code copied and pasted, created by AI or humans, cannot be trusted blindly, requiring good software engineering practices to reduce risk. Future work can help minimize insecure code propagation from any platform.
Code Generation Tools for Free? A Study of Few-Shot, Pre-Trained Language Models on Code
Jun 02, 2022
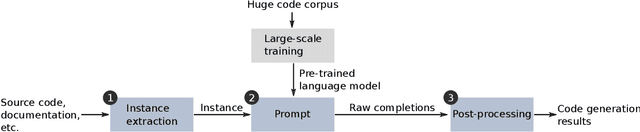

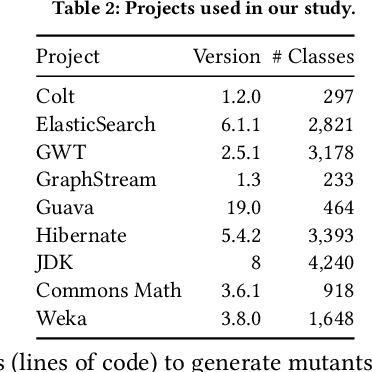
Few-shot learning with large-scale, pre-trained language models is a powerful way to answer questions about code, e.g., how to complete a given code example, or even generate code snippets from scratch. The success of these models raises the question whether they could serve as a basis for building a wide range code generation tools. Traditionally, such tools are built manually and separately for each task. Instead, few-shot learning may allow to obtain different tools from a single pre-trained language model by simply providing a few examples or a natural language description of the expected tool behavior. This paper studies to what extent a state-of-the-art, pre-trained language model of code, Codex, may serve this purpose. We consider three code manipulation and code generation tasks targeted by a range of traditional tools: (i) code mutation; (ii) test oracle generation from natural language documentation; and (iii) test case generation. For each task, we compare few-shot learning to a manually built tool. Our results show that the model-based tools complement (code mutation), are on par (test oracle generation), or even outperform their respective traditionally built tool (test case generation), while imposing far less effort to develop them. By comparing the effectiveness of different variants of the model-based tools, we provide insights on how to design an appropriate input ("prompt") to the model and what influence the size of the model has. For example, we find that providing a small natural language description of the code generation task is an easy way to improve predictions. Overall, we conclude that few-shot language models are surprisingly effective, yet there is still more work to be done, such as exploring more diverse ways of prompting and tackling even more involved tasks.
Generating Adversarial Inputs Using A Black-box Differential Technique
Jul 10, 2020
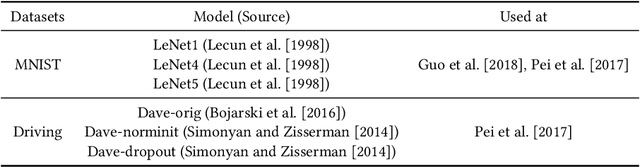
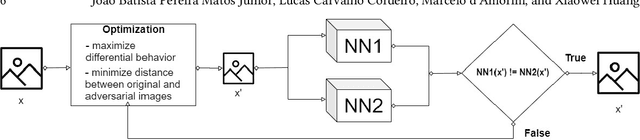
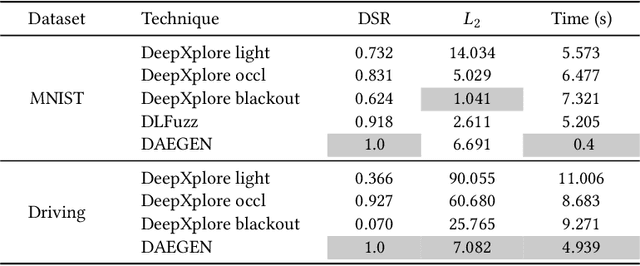
Neural Networks (NNs) are known to be vulnerable to adversarial attacks. A malicious agent initiates these attacks by perturbing an input into another one such that the two inputs are classified differently by the NN. In this paper, we consider a special class of adversarial examples, which can exhibit not only the weakness of NN models - as do for the typical adversarial examples - but also the different behavior between two NN models. We call them difference-inducing adversarial examples or DIAEs. Specifically, we propose DAEGEN, the first black-box differential technique for adversarial input generation. DAEGEN takes as input two NN models of the same classification problem and reports on output an adversarial example. The obtained adversarial example is a DIAE, so that it represents a point-wise difference in the input space between the two NN models. Algorithmically, DAEGEN uses a local search-based optimization algorithm to find DIAEs by iteratively perturbing an input to maximize the difference of two models on predicting the input. We conduct experiments on a spectrum of benchmark datasets (e.g., MNIST, ImageNet, and Driving) and NN models (e.g., LeNet, ResNet, Dave, and VGG). Experimental results are promising. First, we compare DAEGEN with two existing white-box differential techniques (DeepXplore and DLFuzz) and find that under the same setting, DAEGEN is 1) effective, i.e., it is the only technique that succeeds in generating attacks in all cases, 2) precise, i.e., the adversarial attacks are very likely to fool machines and humans, and 3) efficient, i.e, it requires a reasonable number of classification queries. Second, we compare DAEGEN with state-of-the-art black-box adversarial attack methods (simba and tremba), by adapting them to work on a differential setting. The experimental results show that DAEGEN performs better than both of them.