 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Adversarial Inputs Using A Black-box Differential Technique
Jul 10, 2020
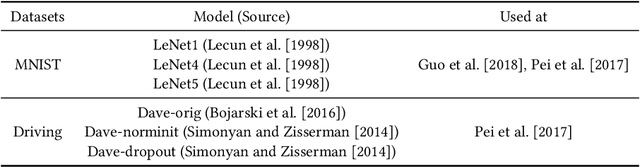
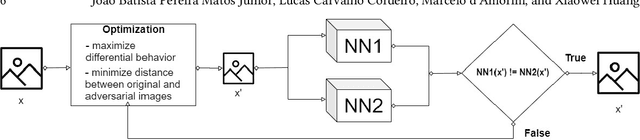
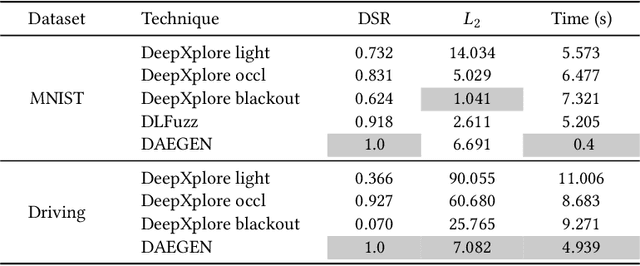
Neural Networks (NNs) are known to be vulnerable to adversarial attacks. A malicious agent initiates these attacks by perturbing an input into another one such that the two inputs are classified differently by the NN. In this paper, we consider a special class of adversarial examples, which can exhibit not only the weakness of NN models - as do for the typical adversarial examples - but also the different behavior between two NN models. We call them difference-inducing adversarial examples or DIAEs. Specifically, we propose DAEGEN, the first black-box differential technique for adversarial input generation. DAEGEN takes as input two NN models of the same classification problem and reports on output an adversarial example. The obtained adversarial example is a DIAE, so that it represents a point-wise difference in the input space between the two NN models. Algorithmically, DAEGEN uses a local search-based optimization algorithm to find DIAEs by iteratively perturbing an input to maximize the difference of two models on predicting the input. We conduct experiments on a spectrum of benchmark datasets (e.g., MNIST, ImageNet, and Driving) and NN models (e.g., LeNet, ResNet, Dave, and VGG). Experimental results are promising. First, we compare DAEGEN with two existing white-box differential techniques (DeepXplore and DLFuzz) and find that under the same setting, DAEGEN is 1) effective, i.e., it is the only technique that succeeds in generating attacks in all cases, 2) precise, i.e., the adversarial attacks are very likely to fool machines and humans, and 3) efficient, i.e, it requires a reasonable number of classification queries. Second, we compare DAEGEN with state-of-the-art black-box adversarial attack methods (simba and tremba), by adapting them to work on a differential setting. The experimental results show that DAEGEN performs better than both of them.