 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Memory-Augmented LLM-Driven Method for Autonomous Merging of 3D Printing Work Orders
Apr 03, 2025



With the rapid development of 3D printing, the demand for personalized and customized production on the manufacturing line is steadily increasing. Efficient merging of printing workpieces can significantly enhance the processing efficiency of the production line. Addressing the challenge, a Large Language Model (LLM)-driven method is established in this paper for the autonomous merging of 3D printing work orders, integrated with a memory-augmented learning strategy. In industrial scenarios, both device and order features are modeled into LLM-readable natural language prompt templates, and develop an order-device matching tool along with a merging interference checking module. By incorporating a self-memory learning strategy, an intelligent agent for autonomous order merging is constructed, resulting in improved accuracy and precision in order allocation. The proposed method effectively leverages the strengths of LLMs in industrial applications while reducing hallucination.
Text2shape Deep Retrieval Model: Generating Initial Cases for Mechanical Part Redesign under the Context of Case-Based Reasoning
Feb 13, 2023



Retrieving the similar solutions from the historical case base for new design requirements is the first step in mechanical part redesign under the context of case-based reasoning. However, the manual retrieving method has the problem of low efficiency when the case base is large. Additionally, it is difficult for simple reasoning algorithms (e.g., rule-based reasoning, decision tree) to cover all the features in complicated design solutions. In this regard, a text2shape deep retrieval model is established in order to support text description-based mechanical part shapes retrieval, where the texts are for describing the structural features of the target mechanical parts. More specifically, feature engineering is applied to identify the key structural features of the target mechanical parts. Based on the identified key structural features, a training set of 1000 samples was constructed, where each sample consisted of a paragraph of text description of a group of structural features and the corresponding 3D shape of the structural features. RNN and 3D CNN algorithms were customized to build the text2shape deep retrieval model. Orthogonal experiments were used for modeling turning. Eventually, the highest accuracy of the model was 0.98; therefore, the model can be effective for retrieving initial cases for mechanical part redesign.
Data-driven intelligent computational design: Method, techniques, and applications
Jan 29, 2023Data-driven intelligent computational design (DICD) is a research hotspot emerged under the context of fast-developing artificial intelligence. It emphasizes on utilizing deep learning algorithms to extract and represent the design features hidden in historical or fabricated design process data, and then learn the combination and mapping patterns of these design features for the purposes of design solution retrieval, generation, optimization, evaluation, etc. Due to its capability of automatically and efficiently generating design solutions and thus supporting human-in-the-loop intelligent and innovative design activities, DICD has drawn the attentions from both academic and industrial fields. However, as an emerging research subject, there are still many unexplored issues that limit the theorical development and industrial application of DICD, such as specific dataset building, engineering design related feature engineering, systematic methods and techniques for DICD implementation, more entry points for DICD application in the entire product design life cycle, etc. In this regard, a systematic theorical reference for DICD implementation is established, including a general workflow for DICD project planning, an overall framework for DICD project implementation, the computing mechanisms for DICD implementation, key enabling technologies for detailed DICD implementation, and three application scenarios of DICD. The works provide a brief research status, key research topics, and more importantly a general road map for DICD implementation.
Social Computational Design Method for Generating Product Shapes with GAN and Transformer Models
Feb 22, 2022
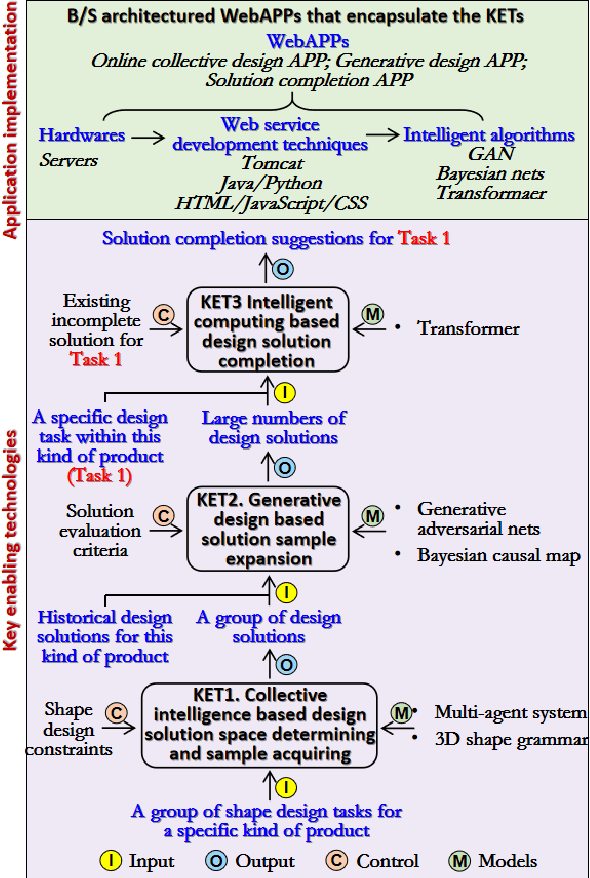

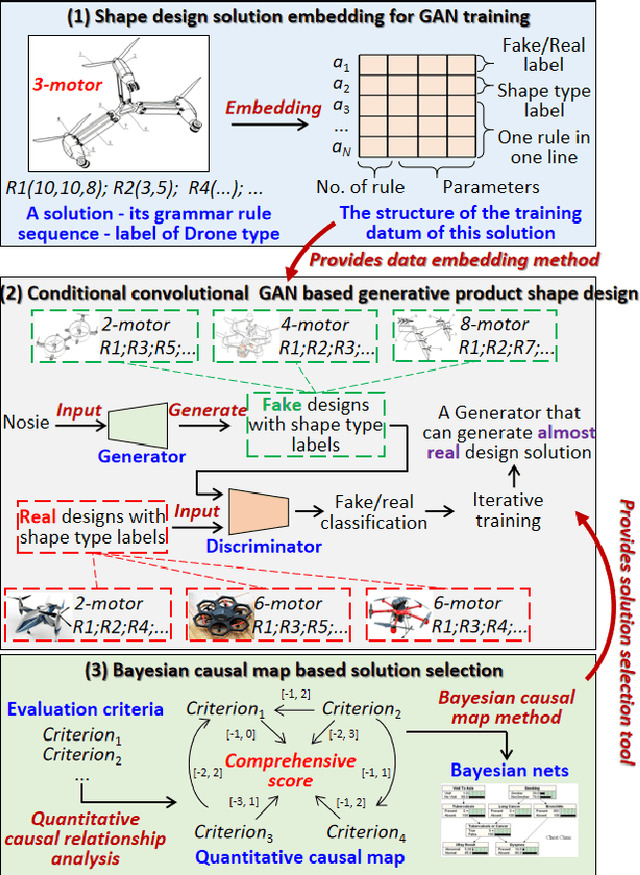
A social computational design method is established, aiming at taking advantages of the fast-developing artificial intelligence technologies for intelligent product design. Supported with multi-agent system, shape grammar, Generative adversarial network, Bayesian network, Transformer, etc., the method is able to define the design solution space, prepare training samples, and eventually acquire an intelligent model that can recommend design solutions according to incomplete solutions for given design tasks. Product shape design is used as entry point to demonstrate the method, however, the method can be applied to tasks rather than shape design when the solutions can be properly coded.
Dynamically Mitigating Data Discrepancy with Balanced Focal Loss for Replay Attack Detection
Jun 25, 2020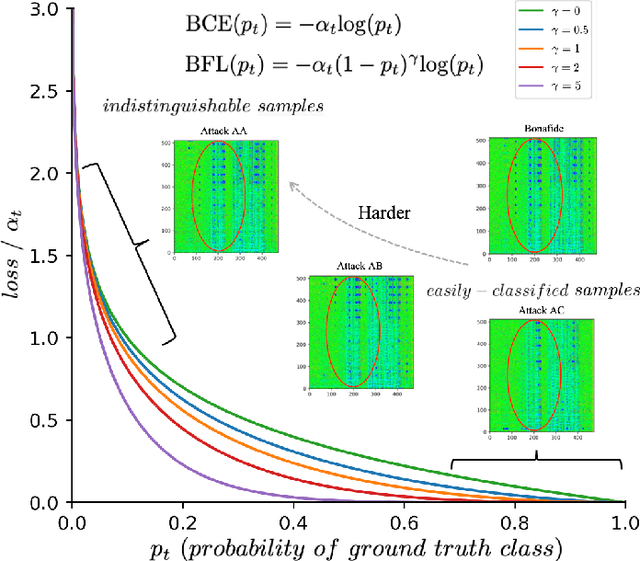
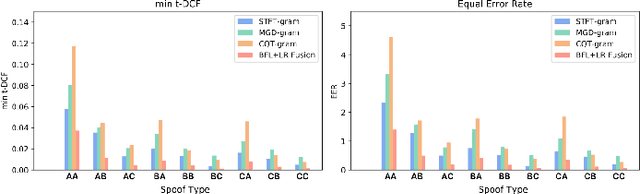
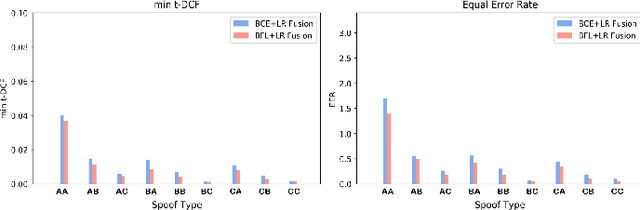
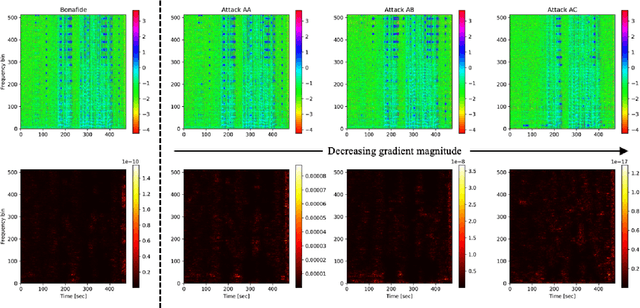
It becomes urgent to design effective anti-spoofing algorithms for vulnerable automatic speaker verification systems due to the advancement of high-quality playback devices. Current studies mainly treat anti-spoofing as a binary classification problem between bonafide and spoofed utterances, while lack of indistinguishable samples makes it difficult to train a robust spoofing detector. In this paper, we argue that for anti-spoofing, it needs more attention for indistinguishable samples over easily-classified ones in the modeling process, to make correct discrimination a top priority. Therefore, to mitigate the data discrepancy between training and inference, we propose to leverage a balanced focal loss function as the training objective to dynamically scale the loss based on the traits of the sample itself. Besides, in the experiments, we select three kinds of features that contain both magnitude-based and phase-based information to form complementary and informative features. Experimental results on the ASVspoof2019 dataset demonstrate the superiority of the proposed methods by comparison between our systems and top-performing ones. Systems trained with the balanced focal loss perform significantly better than conventional cross-entropy loss. With complementary features, our fusion system with only three kinds of features outperforms other systems containing five or more complex single models by 22.5% for min-tDCF and 7% for EER, achieving a min-tDCF and an EER of 0.0124 and 0.55% respectively. Furthermore, we present and discuss the evaluation results on real replay data apart from the simulated ASVspoof2019 data, indicating that research for anti-spoofing still has a long way to go.