 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamically Mitigating Data Discrepancy with Balanced Focal Loss for Replay Attack Detection
Paper and Code
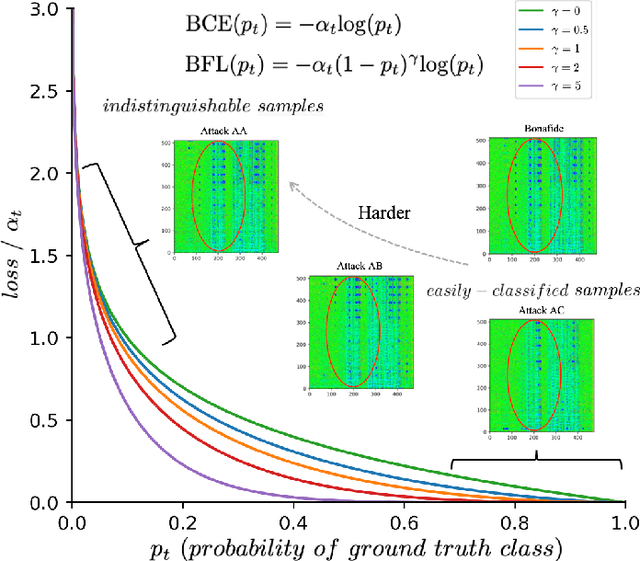
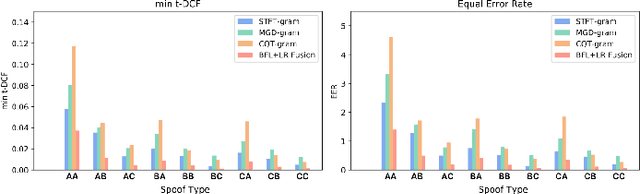
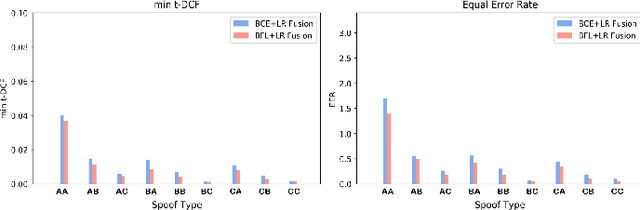
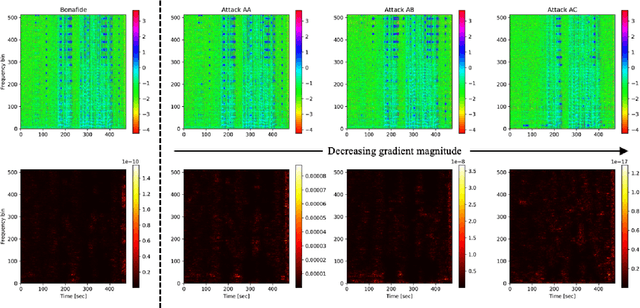
It becomes urgent to design effective anti-spoofing algorithms for vulnerable automatic speaker verification systems due to the advancement of high-quality playback devices. Current studies mainly treat anti-spoofing as a binary classification problem between bonafide and spoofed utterances, while lack of indistinguishable samples makes it difficult to train a robust spoofing detector. In this paper, we argue that for anti-spoofing, it needs more attention for indistinguishable samples over easily-classified ones in the modeling process, to make correct discrimination a top priority. Therefore, to mitigate the data discrepancy between training and inference, we propose to leverage a balanced focal loss function as the training objective to dynamically scale the loss based on the traits of the sample itself. Besides, in the experiments, we select three kinds of features that contain both magnitude-based and phase-based information to form complementary and informative features. Experimental results on the ASVspoof2019 dataset demonstrate the superiority of the proposed methods by comparison between our systems and top-performing ones. Systems trained with the balanced focal loss perform significantly better than conventional cross-entropy loss. With complementary features, our fusion system with only three kinds of features outperforms other systems containing five or more complex single models by 22.5% for min-tDCF and 7% for EER, achieving a min-tDCF and an EER of 0.0124 and 0.55% respectively. Furthermore, we present and discuss the evaluation results on real replay data apart from the simulated ASVspoof2019 data, indicating that research for anti-spoofing still has a long way to go.