 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultispectral airborne laser scanning for tree species classification: a benchmark of machine learning and deep learning algorithms
Apr 19, 2025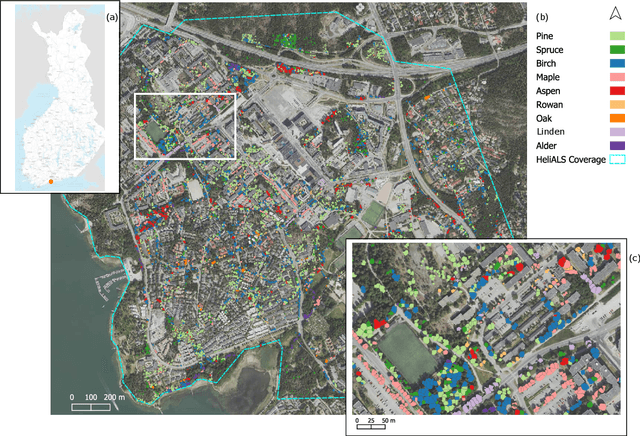


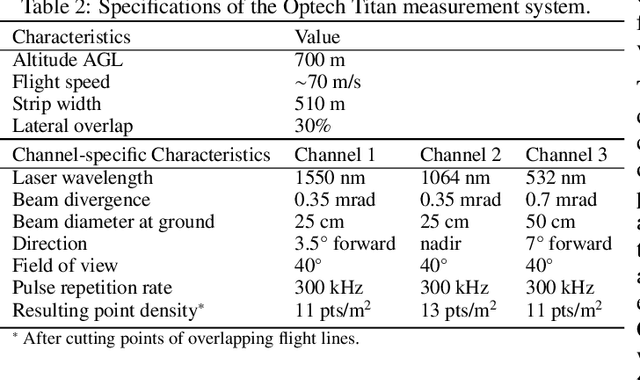
Climate-smart and biodiversity-preserving forestry demands precise information on forest resources, extending to the individual tree level. Multispectral airborne laser scanning (ALS) has shown promise in automated point cloud processing and tree segmentation, but challenges remain in identifying rare tree species and leveraging deep learning techniques. This study addresses these gaps by conducting a comprehensive benchmark of machine learning and deep learning methods for tree species classification. For the study, we collected high-density multispectral ALS data (>1000 pts/m$^2$) at three wavelengths using the FGI-developed HeliALS system, complemented by existing Optech Titan data (35 pts/m$^2$), to evaluate the species classification accuracy of various algorithms in a test site located in Southern Finland. Based on 5261 test segments, our findings demonstrate that point-based deep learning methods, particularly a point transformer model, outperformed traditional machine learning and image-based deep learning approaches on high-density multispectral point clouds. For the high-density ALS dataset, a point transformer model provided the best performance reaching an overall (macro-average) accuracy of 87.9% (74.5%) with a training set of 1065 segments and 92.0% (85.1%) with 5000 training segments. The best image-based deep learning method, DetailView, reached an overall (macro-average) accuracy of 84.3% (63.9%), whereas a random forest (RF) classifier achieved an overall (macro-average) accuracy of 83.2% (61.3%). Importantly, the overall classification accuracy of the point transformer model on the HeliALS data increased from 73.0% with no spectral information to 84.7% with single-channel reflectance, and to 87.9% with spectral information of all the three channels.
Self-Guided Open-Vocabulary Semantic Segmentation
Dec 07, 2023



Vision-Language Models (VLMs) have emerged as promising tools for open-ended image understanding tasks, including open vocabulary segmentation. Yet, direct application of such VLMs to segmentation is non-trivial, since VLMs are trained with image-text pairs and naturally lack pixel-level granularity. Recent works have made advancements in bridging this gap, often by leveraging the shared image-text space in which the image and a provided text prompt are represented. In this paper, we challenge the capabilities of VLMs further and tackle open-vocabulary segmentation without the need for any textual input. To this end, we propose a novel Self-Guided Semantic Segmentation (Self-Seg) framework. Self-Seg is capable of automatically detecting relevant class names from clustered BLIP embeddings and using these for accurate semantic segmentation. In addition, we propose an LLM-based Open-Vocabulary Evaluator (LOVE) to effectively assess predicted open-vocabulary class names. We achieve state-of-the-art results on Pascal VOC, ADE20K and CityScapes for open-vocabulary segmentation without given class names, as well as competitive performance with methods where class names are given. All code and data will be released.