 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic Sentiment Analysis with Noisy Deep Explainable Model
Sep 24, 2023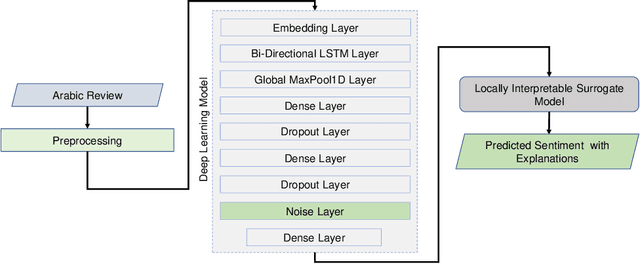
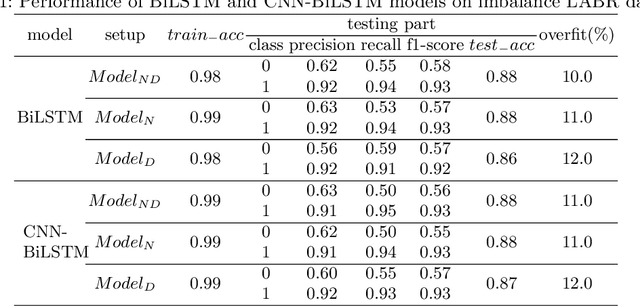
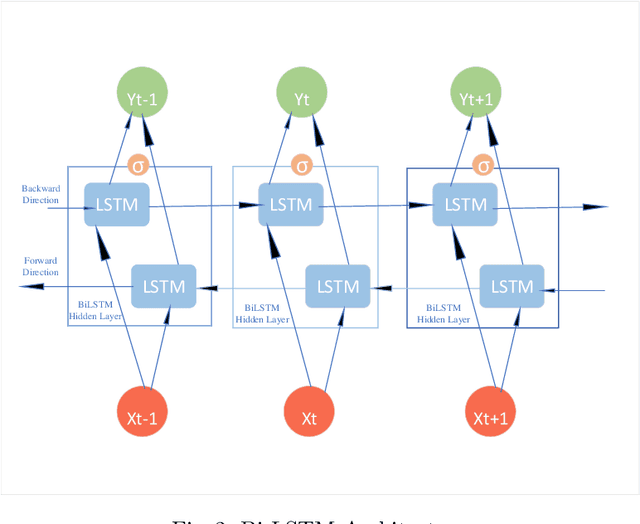
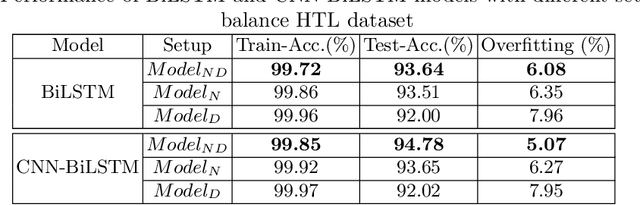
Sentiment Analysis (SA) is an indispensable task for many real-world applications. Compared to limited resourced languages (i.e., Arabic, Bengali), most of the research on SA are conducted for high resourced languages (i.e., English, Chinese). Moreover, the reasons behind any prediction of the Arabic sentiment analysis methods exploiting advanced artificial intelligence (AI)-based approaches are like black-box - quite difficult to understand. This paper proposes an explainable sentiment classification framework for the Arabic language by introducing a noise layer on Bi-Directional Long Short-Term Memory (BiLSTM) and Convolutional Neural Networks (CNN)-BiLSTM models that overcome over-fitting problem. The proposed framework can explain specific predictions by training a local surrogate explainable model to understand why a particular sentiment (positive or negative) is being predicted. We carried out experiments on public benchmark Arabic SA datasets. The results concluded that adding noise layers improves the performance in sentiment analysis for the Arabic language by reducing overfitting and our method outperformed some known state-of-the-art methods. In addition, the introduced explainability with noise layer could make the model more transparent and accountable and hence help adopting AI-enabled system in practice.
Textual Entailment Recognition with Semantic Features from Empirical Text Representation
Oct 18, 2022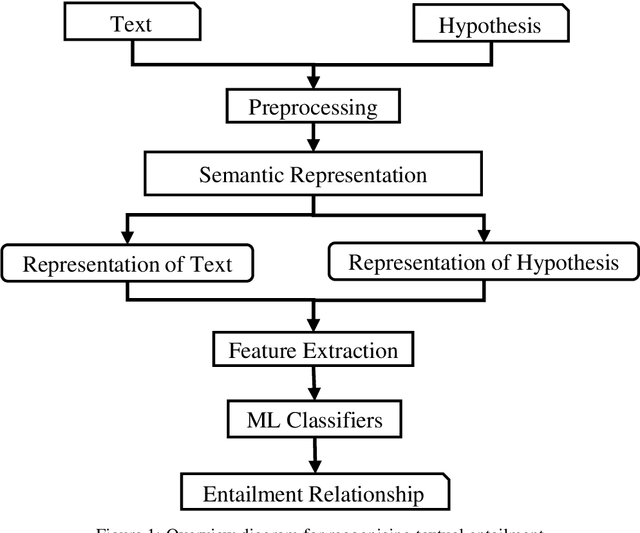
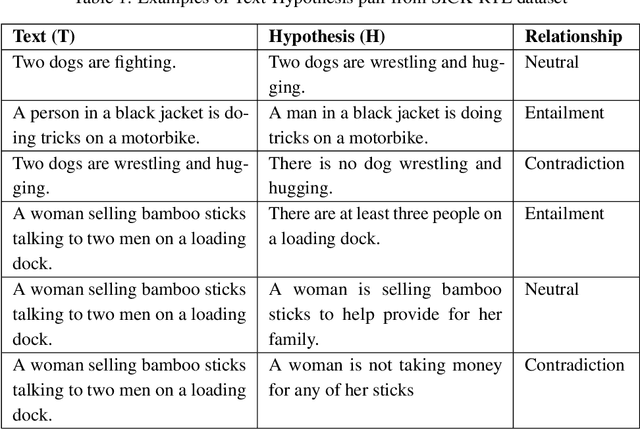

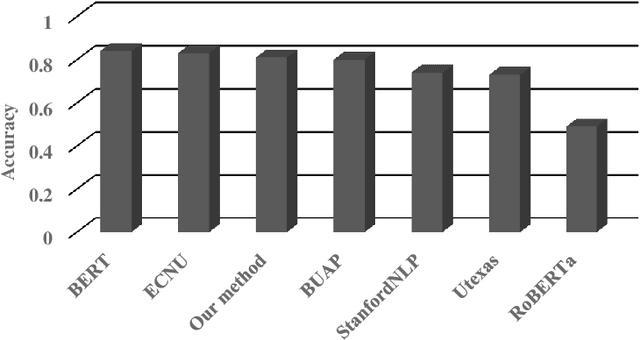
Textual entailment recognition is one of the basic natural language understanding(NLU) tasks. Understanding the meaning of sentences is a prerequisite before applying any natural language processing(NLP) techniques to automatically recognize the textual entailment. A text entails a hypothesis if and only if the true value of the hypothesis follows the text. Classical approaches generally utilize the feature value of each word from word embedding to represent the sentences. In this paper, we propose a novel approach to identifying the textual entailment relationship between text and hypothesis, thereby introducing a new semantic feature focusing on empirical threshold-based semantic text representation. We employ an element-wise Manhattan distance vector-based feature that can identify the semantic entailment relationship between the text-hypothesis pair. We carried out several experiments on a benchmark entailment classification(SICK-RTE) dataset. We train several machine learning(ML) algorithms applying both semantic and lexical features to classify the text-hypothesis pair as entailment, neutral, or contradiction. Our empirical sentence representation technique enriches the semantic information of the texts and hypotheses found to be more efficient than the classical ones. In the end, our approach significantly outperforms known methods in understanding the meaning of the sentences for the textual entailment classification task.