 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic Sentiment Analysis with Noisy Deep Explainable Model
Paper and Code
Sep 24, 2023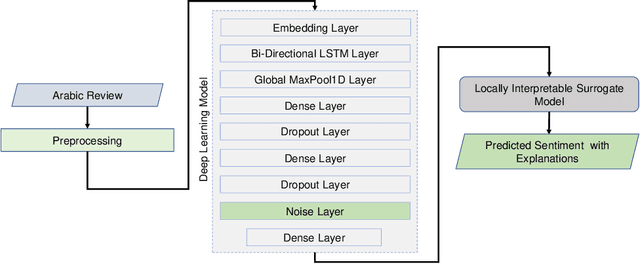
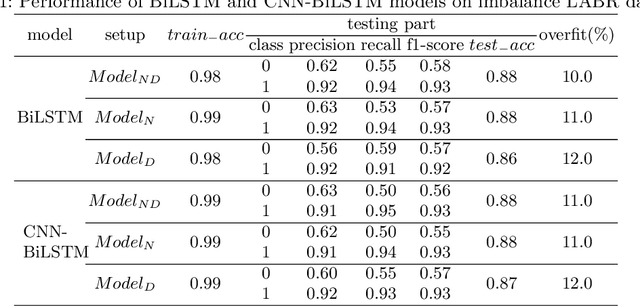
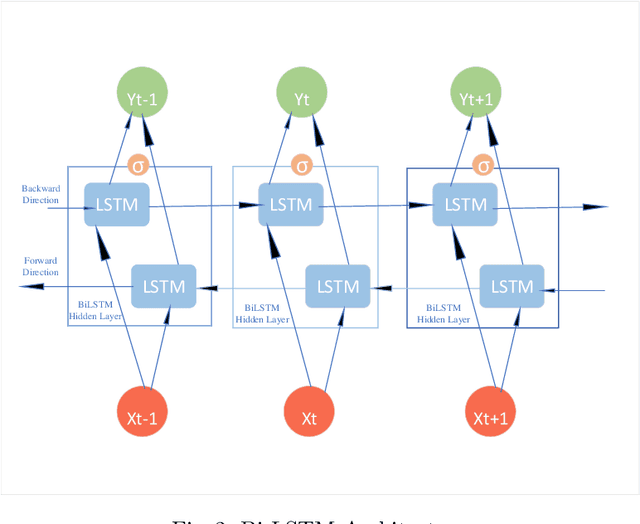
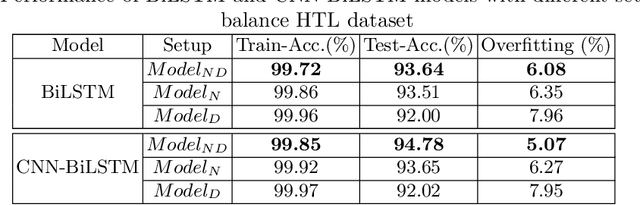
Sentiment Analysis (SA) is an indispensable task for many real-world applications. Compared to limited resourced languages (i.e., Arabic, Bengali), most of the research on SA are conducted for high resourced languages (i.e., English, Chinese). Moreover, the reasons behind any prediction of the Arabic sentiment analysis methods exploiting advanced artificial intelligence (AI)-based approaches are like black-box - quite difficult to understand. This paper proposes an explainable sentiment classification framework for the Arabic language by introducing a noise layer on Bi-Directional Long Short-Term Memory (BiLSTM) and Convolutional Neural Networks (CNN)-BiLSTM models that overcome over-fitting problem. The proposed framework can explain specific predictions by training a local surrogate explainable model to understand why a particular sentiment (positive or negative) is being predicted. We carried out experiments on public benchmark Arabic SA datasets. The results concluded that adding noise layers improves the performance in sentiment analysis for the Arabic language by reducing overfitting and our method outperformed some known state-of-the-art methods. In addition, the introduced explainability with noise layer could make the model more transparent and accountable and hence help adopting AI-enabled system in practice.