 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Koopman Spectral Profiling for Predicting and Preventing Transformer Training Instability
Feb 26, 2026Training divergence in transformers wastes compute, yet practitioners discover instability only after expensive runs begin. They therefore need an expected probability of failure for a transformer before training starts. Our study of Residual Koopman Spectral Profiling (RKSP) provides such an estimate. From a single forward pass at initialization, RKSP extracts Koopman spectral features by applying whitened dynamic mode decomposition to layer-wise residual snapshots. Our central diagnostic, the near-unit spectral mass, quantifies the fraction of modes concentrated near the unit circle, which captures instability risk. For predicting divergence across extensive configurations, this estimator achieves an AUROC of 0.995, outperforming the best gradient baseline. We further make this diagnostic actionable through Koopman Spectral Shaping (KSS), which reshapes spectra during training. We empirically validate that our method works in practice: RKSP predicts divergence at initialization, and when RKSP flags high risk, turning on KSS successfully prevents divergence. In the challenging high learning rate regime without normalization layers, KSS reduces the divergence rate from 66.7% to 12.5% and enables learning rates that are 50% to 150% higher. These findings generalize to WikiText-103 language modeling, vision transformers on CIFAR-10, and pretrained language models, including GPT-2 and LLaMA-2 up to 7B, as well as emerging architectures such as MoE, Mamba-style SSMs, and KAN.
Equivariant and Invariant Reynolds Networks
Oct 15, 2021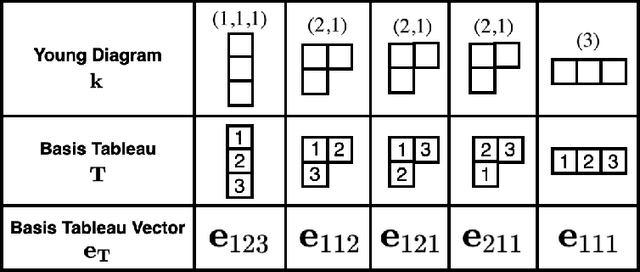
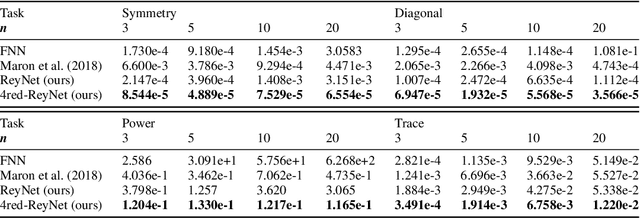

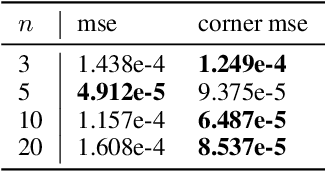
Invariant and equivariant networks are useful in learning data with symmetry, including images, sets, point clouds, and graphs. In this paper, we consider invariant and equivariant networks for symmetries of finite groups. Invariant and equivariant networks have been constructed by various researchers using Reynolds operators. However, Reynolds operators are computationally expensive when the order of the group is large because they use the sum over the whole group, which poses an implementation difficulty. To overcome this difficulty, we consider representing the Reynolds operator as a sum over a subset instead of a sum over the whole group. We call such a subset a Reynolds design, and an operator defined by a sum over a Reynolds design a reductive Reynolds operator. For example, in the case of a graph with $n$ nodes, the computational complexity of the reductive Reynolds operator is reduced to $O(n^2)$, while the computational complexity of the Reynolds operator is $O(n!)$. We construct learning models based on the reductive Reynolds operator called equivariant and invariant Reynolds networks (ReyNets) and prove that they have universal approximation property. Reynolds designs for equivariant ReyNets are derived from combinatorial observations with Young diagrams, while Reynolds designs for invariant ReyNets are derived from invariants called Reynolds dimensions defined on the set of invariant polynomials. Numerical experiments show that the performance of our models is comparable to state-of-the-art methods.
Group Equivariant Conditional Neural Processes
Feb 17, 2021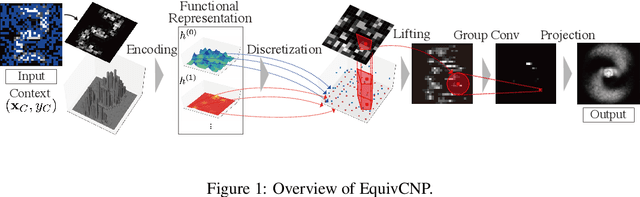
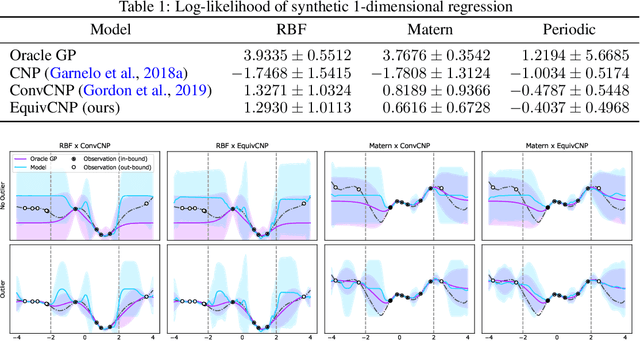

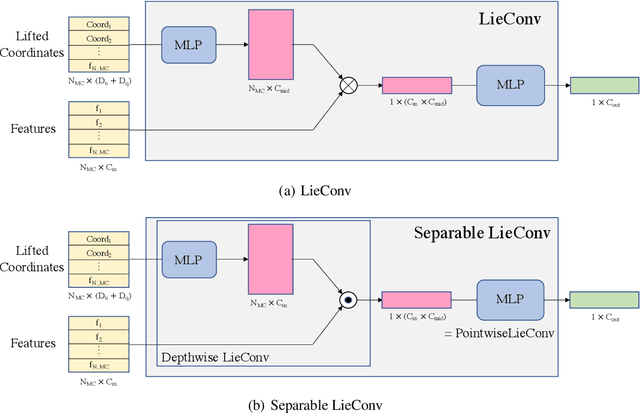
We present the group equivariant conditional neural process (EquivCNP), a meta-learning method with permutation invariance in a data set as in conventional conditional neural processes (CNPs), and it also has transformation equivariance in data space. Incorporating group equivariance, such as rotation and scaling equivariance, provides a way to consider the symmetry of real-world data. We give a decomposition theorem for permutation-invariant and group-equivariant maps, which leads us to construct EquivCNPs with an infinite-dimensional latent space to handle group symmetries. In this paper, we build architecture using Lie group convolutional layers for practical implementation. We show that EquivCNP with translation equivariance achieves comparable performance to conventional CNPs in a 1D regression task. Moreover, we demonstrate that incorporating an appropriate Lie group equivariance, EquivCNP is capable of zero-shot generalization for an image-completion task by selecting an appropriate Lie group equivariance.