 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObtaining Accurate Probabilistic Causal Inference by Post-Processing Calibration
Dec 22, 2017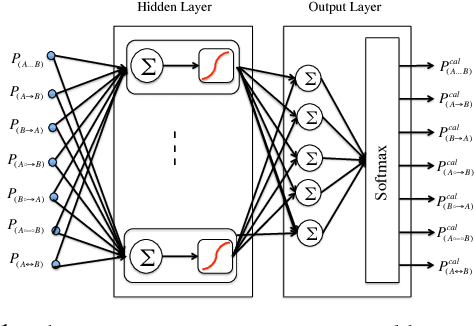
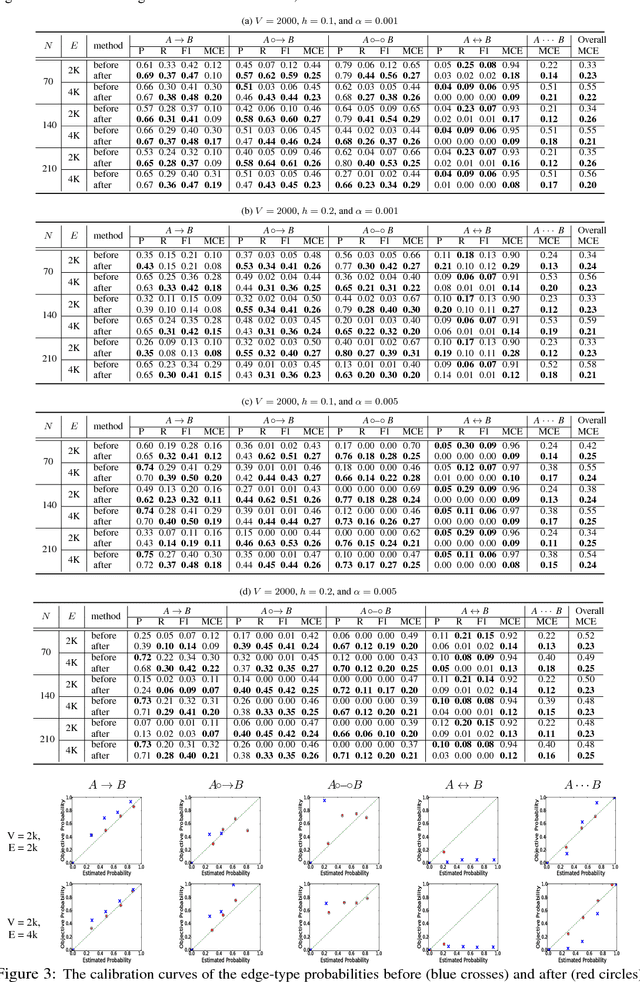
Discovery of an accurate causal Bayesian network structure from observational data can be useful in many areas of science. Often the discoveries are made under uncertainty, which can be expressed as probabilities. To guide the use of such discoveries, including directing further investigation, it is important that those probabilities be well-calibrated. In this paper, we introduce a novel framework to derive calibrated probabilities of causal relationships from observational data. The framework consists of three components: (1) an approximate method for generating initial probability estimates of the edge types for each pair of variables, (2) the availability of a relatively small number of the causal relationships in the network for which the truth status is known, which we call a calibration training set, and (3) a calibration method for using the approximate probability estimates and the calibration training set to generate calibrated probabilities for the many remaining pairs of variables. We also introduce a new calibration method based on a shallow neural network. Our experiments on simulated data support that the proposed approach improves the calibration of causal edge predictions. The results also support that the approach often improves the precision and recall of predictions.
Binary Classifier Calibration using an Ensemble of Near Isotonic Regression Models
Nov 16, 2015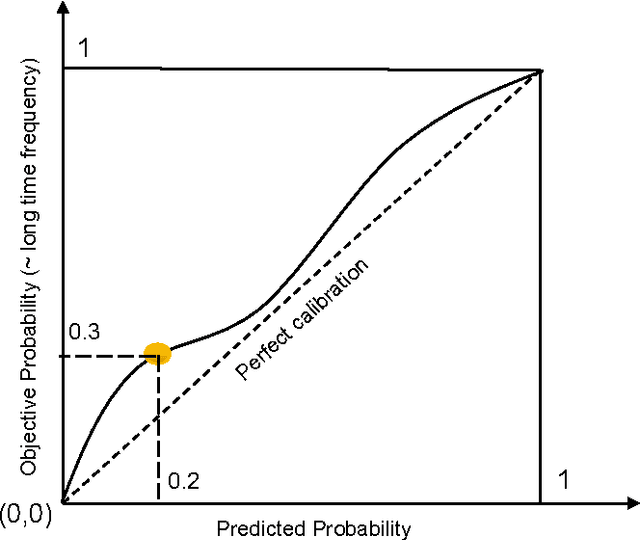
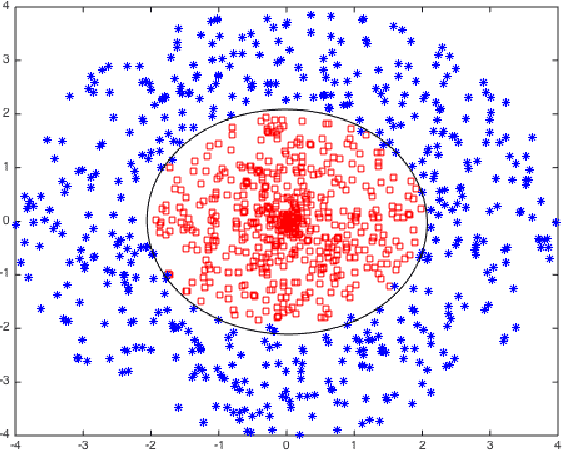
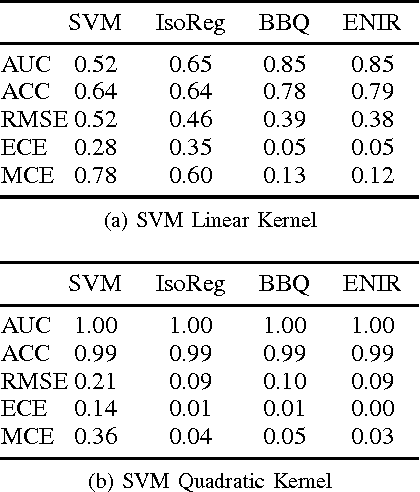

Learning accurate probabilistic models from data is crucial in many practical tasks in data mining. In this paper we present a new non-parametric calibration method called \textit{ensemble of near isotonic regression} (ENIR). The method can be considered as an extension of BBQ, a recently proposed calibration method, as well as the commonly used calibration method based on isotonic regression. ENIR is designed to address the key limitation of isotonic regression which is the monotonicity assumption of the predictions. Similar to BBQ, the method post-processes the output of a binary classifier to obtain calibrated probabilities. Thus it can be combined with many existing classification models. We demonstrate the performance of ENIR on synthetic and real datasets for the commonly used binary classification models. Experimental results show that the method outperforms several common binary classifier calibration methods. In particular on the real data, ENIR commonly performs statistically significantly better than the other methods, and never worse. It is able to improve the calibration power of classifiers, while retaining their discrimination power. The method is also computationally tractable for large scale datasets, as it is $O(N \log N)$ time, where $N$ is the number of samples.
Binary Classifier Calibration: Non-parametric approach
Jan 14, 2014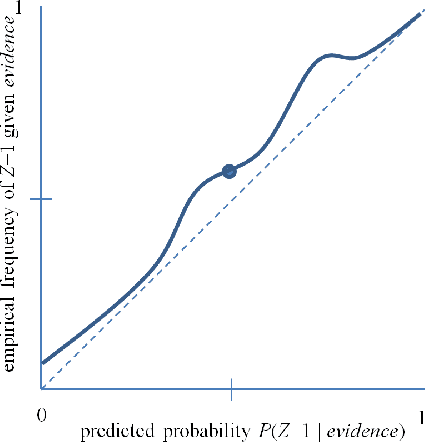
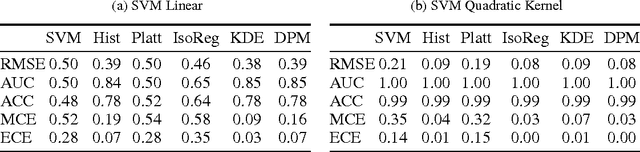

Accurate calibration of probabilistic predictive models learned is critical for many practical prediction and decision-making tasks. There are two main categories of methods for building calibrated classifiers. One approach is to develop methods for learning probabilistic models that are well-calibrated, ab initio. The other approach is to use some post-processing methods for transforming the output of a classifier to be well calibrated, as for example histogram binning, Platt scaling, and isotonic regression. One advantage of the post-processing approach is that it can be applied to any existing probabilistic classification model that was constructed using any machine-learning method. In this paper, we first introduce two measures for evaluating how well a classifier is calibrated. We prove three theorems showing that using a simple histogram binning post-processing method, it is possible to make a classifier be well calibrated while retaining its discrimination capability. Also, by casting the histogram binning method as a density-based non-parametric binary classifier, we can extend it using two simple non-parametric density estimation methods. We demonstrate the performance of the proposed calibration methods on synthetic and real datasets. Experimental results show that the proposed methods either outperform or are comparable to existing calibration methods.
Binary Classifier Calibration: Bayesian Non-Parametric Approach
Jan 13, 2014

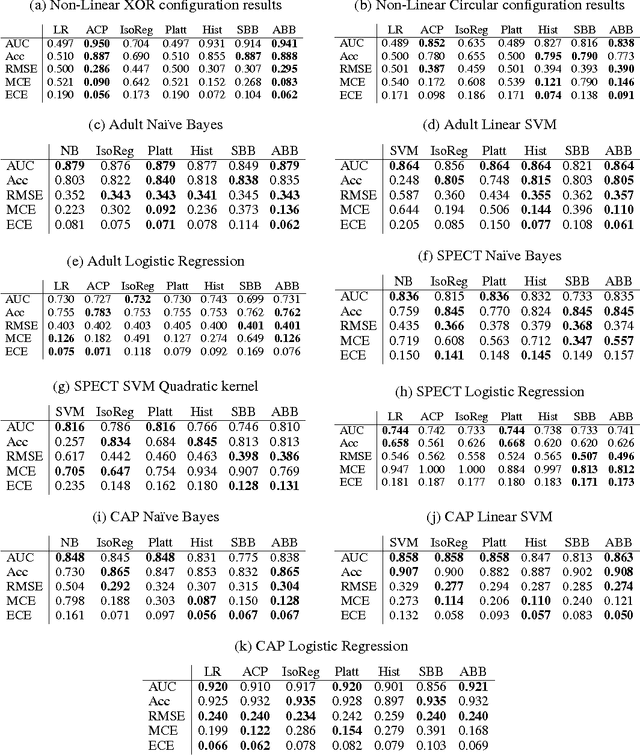
A set of probabilistic predictions is well calibrated if the events that are predicted to occur with probability p do in fact occur about p fraction of the time. Well calibrated predictions are particularly important when machine learning models are used in decision analysis. This paper presents two new non-parametric methods for calibrating outputs of binary classification models: a method based on the Bayes optimal selection and a method based on the Bayesian model averaging. The advantage of these methods is that they are independent of the algorithm used to learn a predictive model, and they can be applied in a post-processing step, after the model is learned. This makes them applicable to a wide variety of machine learning models and methods. These calibration methods, as well as other methods, are tested on a variety of datasets in terms of both discrimination and calibration performance. The results show the methods either outperform or are comparable in performance to the state-of-the-art calibration methods.