 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliciting Compatible Demonstrations for Multi-Human Imitation Learning
Oct 14, 2022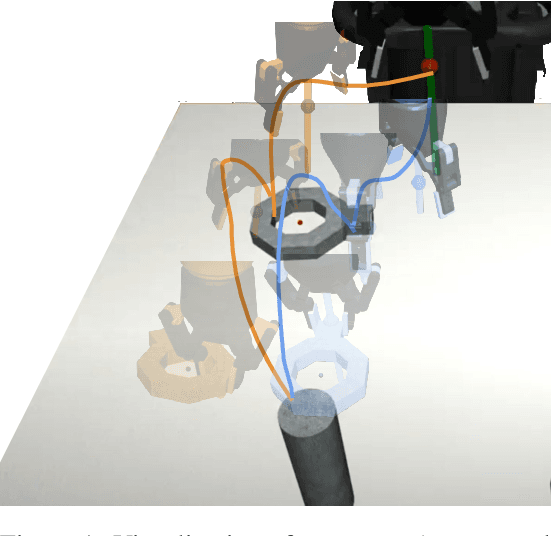
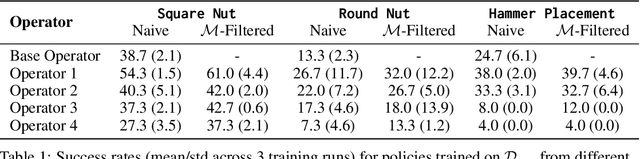
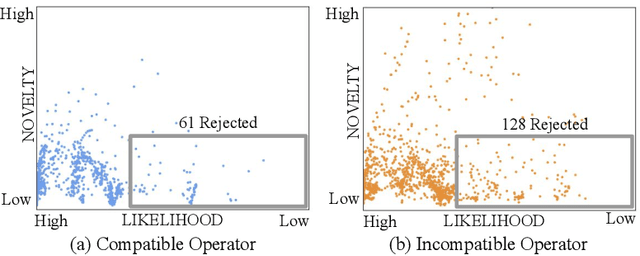

Imitation learning from human-provided demonstrations is a strong approach for learning policies for robot manipulation. While the ideal dataset for imitation learning is homogenous and low-variance -- reflecting a single, optimal method for performing a task -- natural human behavior has a great deal of heterogeneity, with several optimal ways to demonstrate a task. This multimodality is inconsequential to human users, with task variations manifesting as subconscious choices; for example, reaching down, then across to grasp an object, versus reaching across, then down. Yet, this mismatch presents a problem for interactive imitation learning, where sequences of users improve on a policy by iteratively collecting new, possibly conflicting demonstrations. To combat this problem of demonstrator incompatibility, this work designs an approach for 1) measuring the compatibility of a new demonstration given a base policy, and 2) actively eliciting more compatible demonstrations from new users. Across two simulation tasks requiring long-horizon, dexterous manipulation and a real-world "food plating" task with a Franka Emika Panda arm, we show that we can both identify incompatible demonstrations via post-hoc filtering, and apply our compatibility measure to actively elicit compatible demonstrations from new users, leading to improved task success rates across simulated and real environments.
Featurized Density Ratio Estimation
Jul 05, 2021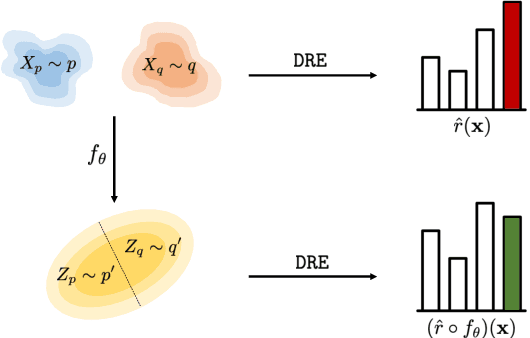

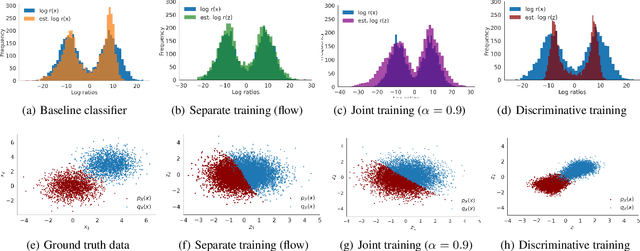
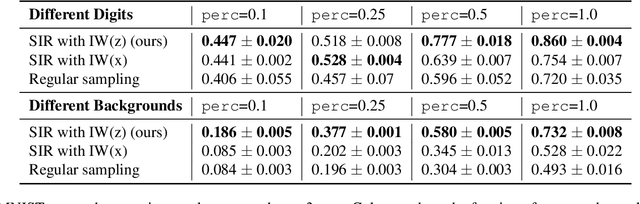
Density ratio estimation serves as an important technique in the unsupervised machine learning toolbox. However, such ratios are difficult to estimate for complex, high-dimensional data, particularly when the densities of interest are sufficiently different. In our work, we propose to leverage an invertible generative model to map the two distributions into a common feature space prior to estimation. This featurization brings the densities closer together in latent space, sidestepping pathological scenarios where the learned density ratios in input space can be arbitrarily inaccurate. At the same time, the invertibility of our feature map guarantees that the ratios computed in feature space are equivalent to those in input space. Empirically, we demonstrate the efficacy of our approach in a variety of downstream tasks that require access to accurate density ratios such as mutual information estimation, targeted sampling in deep generative models, and classification with data augmentation.