 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuadratic Forms in Gaussian Random Variables Theoretical Results and Applications
May 10, 2026This manuscript reviews theoretical results and applications related to quadratic forms in Gaussian random variables. It summarizes definitions, canonical representations, exact and approximate distributional results, numerical inversion methods, applications, and selected open problems for real and complex quadratic forms, multiforms, and ratios of quadratic forms.
Regularized Linear Discriminant Analysis Using a Nonlinear Covariance Matrix Estimator
Feb 07, 2024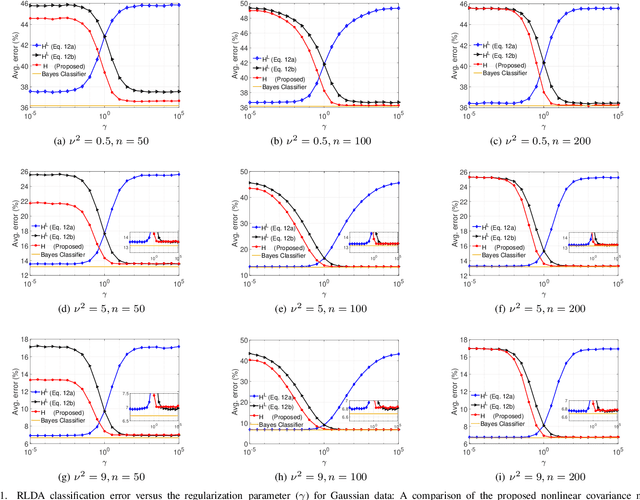
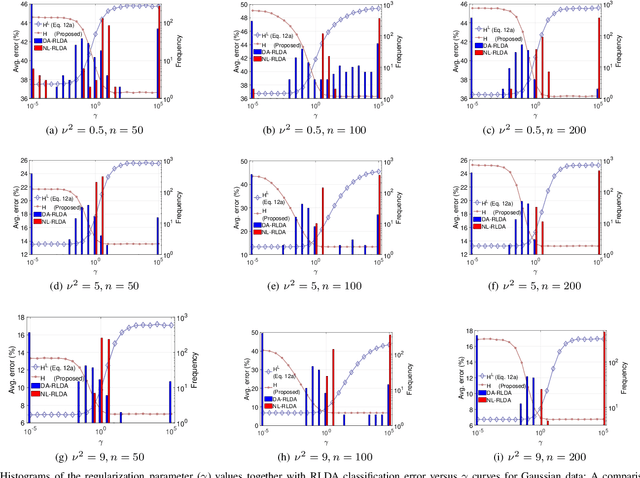
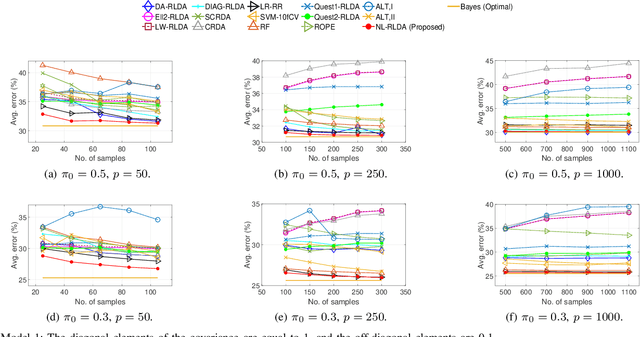
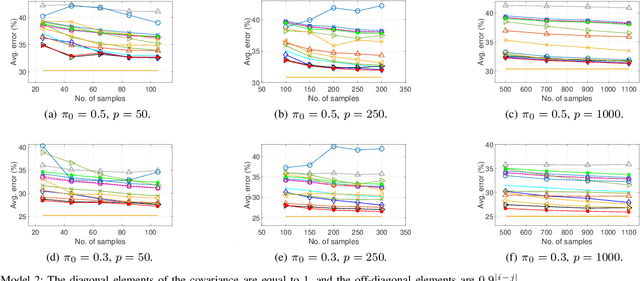
Linear discriminant analysis (LDA) is a widely used technique for data classification. The method offers adequate performance in many classification problems, but it becomes inefficient when the data covariance matrix is ill-conditioned. This often occurs when the feature space's dimensionality is higher than or comparable to the training data size. Regularized LDA (RLDA) methods based on regularized linear estimators of the data covariance matrix have been proposed to cope with such a situation. The performance of RLDA methods is well studied, with optimal regularization schemes already proposed. In this paper, we investigate the capability of a positive semidefinite ridge-type estimator of the inverse covariance matrix that coincides with a nonlinear (NL) covariance matrix estimator. The estimator is derived by reformulating the score function of the optimal classifier utilizing linear estimation methods, which eventually results in the proposed NL-RLDA classifier. We derive asymptotic and consistent estimators of the proposed technique's misclassification rate under the assumptions of a double-asymptotic regime and multivariate Gaussian model for the classes. The consistent estimator, coupled with a one-dimensional grid search, is used to set the value of the regularization parameter required for the proposed NL-RLDA classifier. Performance evaluations based on both synthetic and real data demonstrate the effectiveness of the proposed classifier. The proposed technique outperforms state-of-art methods over multiple datasets. When compared to state-of-the-art methods across various datasets, the proposed technique exhibits superior performance.
Portfolio Optimization Using a Consistent Vector-Based MSE Estimation Approach
Apr 12, 2022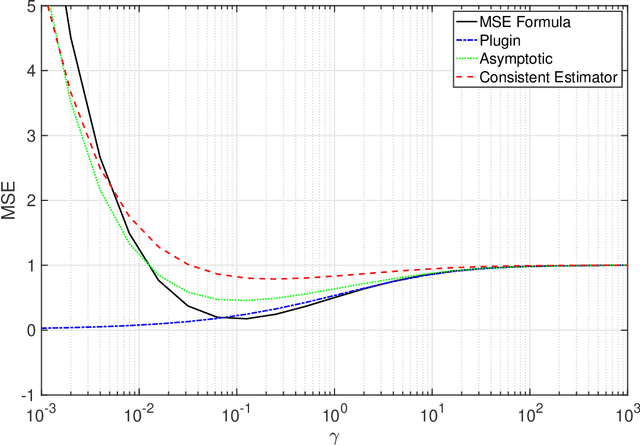
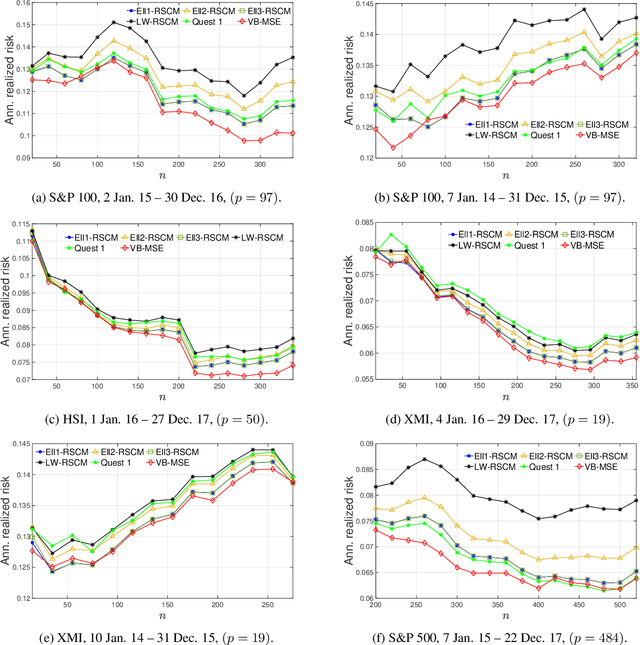
This paper is concerned with optimizing the global minimum-variance portfolio's (GMVP) weights in high-dimensional settings where both observation and population dimensions grow at a bounded ratio. Optimizing the GMVP weights is highly influenced by the data covariance matrix estimation. In a high-dimensional setting, it is well known that the sample covariance matrix is not a proper estimator of the true covariance matrix since it is not invertible when we have fewer observations than the data dimension. Even with more observations, the sample covariance matrix may not be well-conditioned. This paper determines the GMVP weights based on a regularized covariance matrix estimator to overcome the aforementioned difficulties. Unlike other methods, the proper selection of the regularization parameter is achieved by minimizing the mean-squared error of an estimate of the noise vector that accounts for the uncertainty in the data mean estimation. Using random-matrix-theory tools, we derive a consistent estimator of the achievable mean-squared error that allows us to find the optimal regularization parameter using a simple line search. Simulation results demonstrate the effectiveness of the proposed method when the data dimension is larger than the number of data samples or of the same order.