 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Diverse Realistic Laughter for Interactive Art
Nov 04, 2021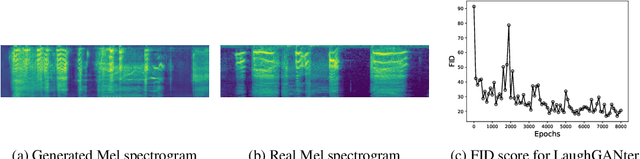
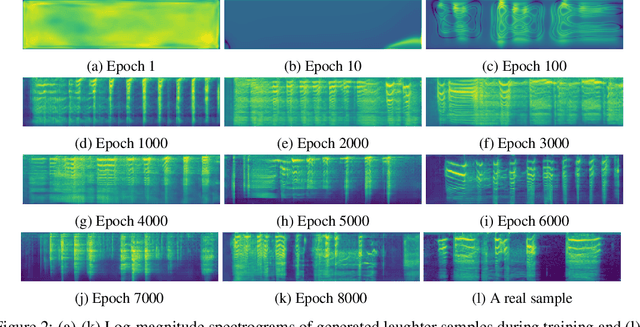
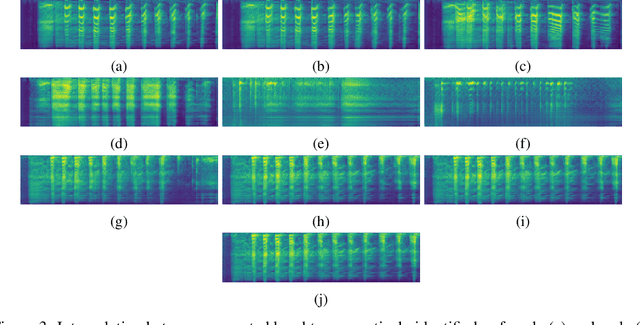
We propose an interactive art project to make those rendered invisible by the COVID-19 crisis and its concomitant solitude reappear through the welcome melody of laughter, and connections created and explored through advanced laughter synthesis approaches. However, the unconditional generation of the diversity of human emotional responses in high-quality auditory synthesis remains an open problem, with important implications for the application of these approaches in artistic settings. We developed LaughGANter, an approach to reproduce the diversity of human laughter using generative adversarial networks (GANs). When trained on a dataset of diverse laughter samples, LaughGANter generates diverse, high quality laughter samples, and learns a latent space suitable for emotional analysis and novel artistic applications such as latent mixing/interpolation and emotional transfer.
Reinforcement learning based recommender systems: A survey
Jan 15, 2021
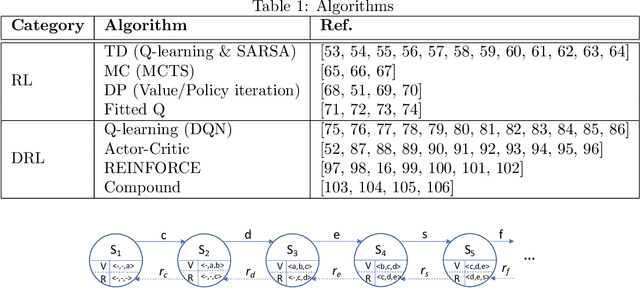
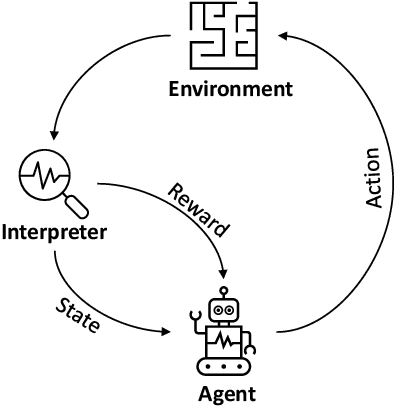
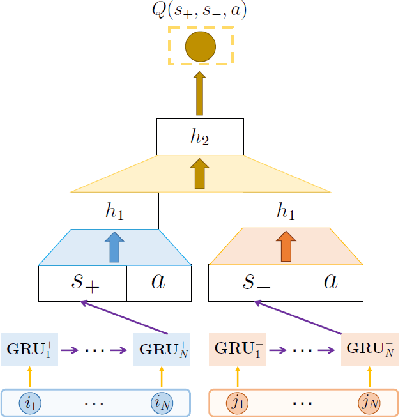
Recommender systems (RSs) are becoming an inseparable part of our everyday lives. They help us find our favorite items to purchase, our friends on social networks, and our favorite movies to watch. Traditionally, the recommendation problem was considered as a simple classification or prediction problem; however, the sequential nature of the recommendation problem has been shown. Accordingly, it can be formulated as a Markov decision process (MDP) and reinforcement learning (RL) methods can be employed to solve it. In fact, recent advances in combining deep learning with traditional RL methods, i.e. deep reinforcement learning (DRL), has made it possible to apply RL to the recommendation problem with massive state and action spaces. In this paper, a survey on reinforcement learning based recommender systems (RLRSs) is presented. We first recognize the fact that algorithms developed for RLRSs can be generally classified into RL- and DRL-based methods. Then, we present these RL- and DRL-based methods in a classified manner based on the specific RL algorithm, e.g., Q-learning, SARSA, and REINFORCE, that is used to optimize the recommendation policy. Furthermore, some tables are presented that contain detailed information about the MDP formulation of these methods, as well as about their evaluation schemes. Finally, we discuss important aspects and challenges that can be addressed in the future.