 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlossBERT: BERT for Word Sense Disambiguation with Gloss Knowledge
Aug 20, 2019
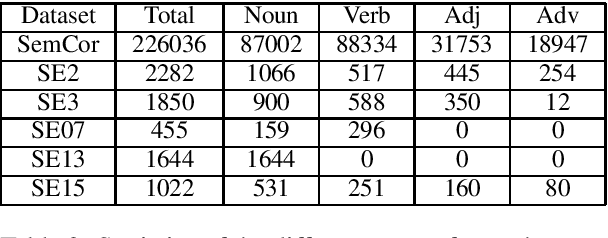
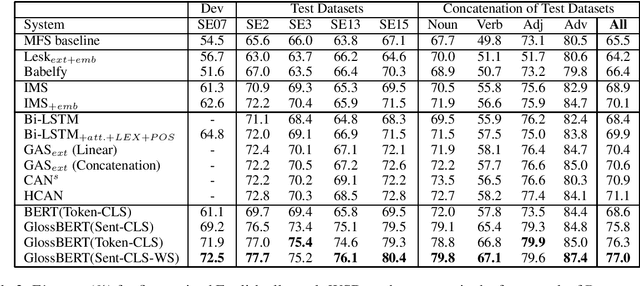
Word Sense Disambiguation (WSD) aims to find the exact sense of an ambiguous word in a particular context. Traditional supervised methods rarely take into consideration the lexical resources like WordNet, which are widely utilized in knowledge-based methods. Recent studies have shown the effectiveness of incorporating gloss (sense definition) into neural networks for WSD. However, compared with traditional word expert supervised methods, they have not achieved much improvement. In this paper, we focus on how to better leverage gloss knowledge in a supervised neural WSD system. We construct context-gloss pairs and propose three BERT-based models for WSD. We fine-tune the pre-trained BERT model and achieve new state-of-the-art results on WSD task.
DropAttention: A Regularization Method for Fully-Connected Self-Attention Networks
Jul 26, 2019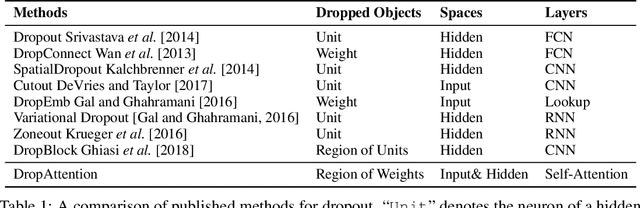
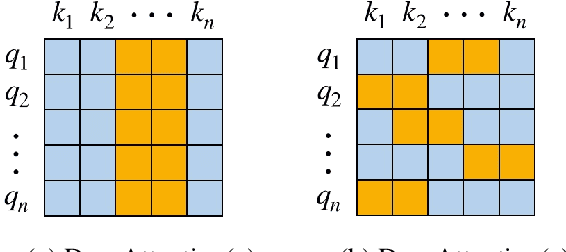
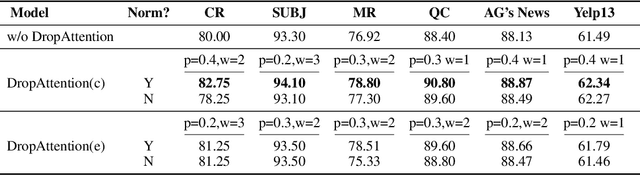
Variants dropout methods have been designed for the fully-connected layer, convolutional layer and recurrent layer in neural networks, and shown to be effective to avoid overfitting. As an appealing alternative to recurrent and convolutional layers, the fully-connected self-attention layer surprisingly lacks a specific dropout method. This paper explores the possibility of regularizing the attention weights in Transformers to prevent different contextualized feature vectors from co-adaption. Experiments on a wide range of tasks show that DropAttention can improve performance and reduce overfitting.
Utilizing BERT for Aspect-Based Sentiment Analysis via Constructing Auxiliary Sentence
Mar 22, 2019

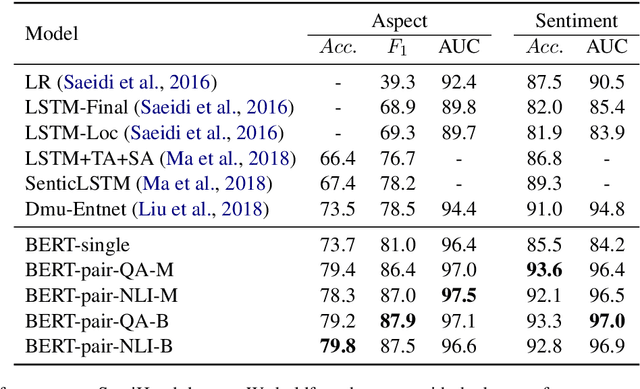
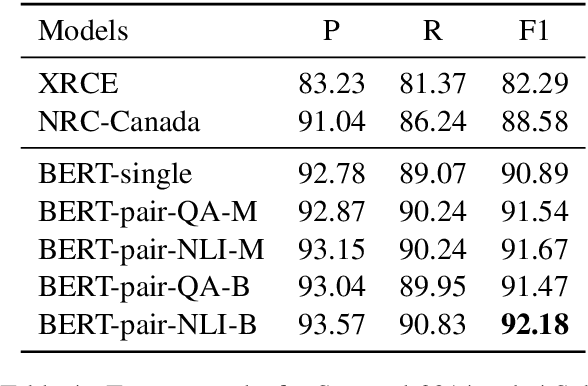
Aspect-based sentiment analysis (ABSA), which aims to identify fine-grained opinion polarity towards a specific aspect, is a challenging subtask of sentiment analysis (SA). In this paper, we construct an auxiliary sentence from the aspect and convert ABSA to a sentence-pair classification task, such as question answering (QA) and natural language inference (NLI). We fine-tune the pre-trained model from BERT and achieve new state-of-the-art results on SentiHood and SemEval-2014 Task 4 datasets.