Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDropAttention: A Regularization Method for Fully-Connected Self-Attention Networks
Paper and Code
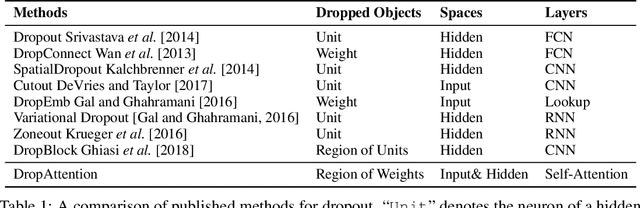
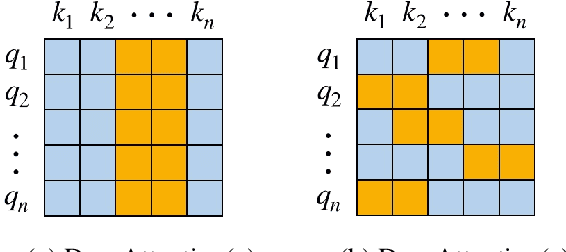
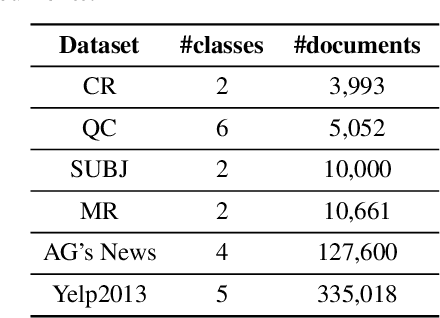
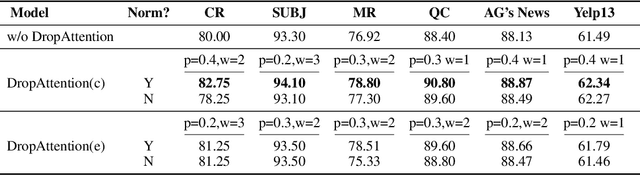
Variants dropout methods have been designed for the fully-connected layer, convolutional layer and recurrent layer in neural networks, and shown to be effective to avoid overfitting. As an appealing alternative to recurrent and convolutional layers, the fully-connected self-attention layer surprisingly lacks a specific dropout method. This paper explores the possibility of regularizing the attention weights in Transformers to prevent different contextualized feature vectors from co-adaption. Experiments on a wide range of tasks show that DropAttention can improve performance and reduce overfitting.
View paper on