 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical semantics for lung cancer prediction
Aug 20, 2025Background: Existing clinical prediction models often represent patient data using features that ignore the semantic relationships between clinical concepts. This study integrates domain-specific semantic information by mapping the SNOMED medical term hierarchy into a low-dimensional hyperbolic space using Poincar\'e embeddings, with the aim of improving lung cancer onset prediction. Methods: Using a retrospective cohort from the Optum EHR dataset, we derived a clinical knowledge graph from the SNOMED taxonomy and generated Poincar\'e embeddings via Riemannian stochastic gradient descent. These embeddings were then incorporated into two deep learning architectures, a ResNet and a Transformer model. Models were evaluated for discrimination (area under the receiver operating characteristic curve) and calibration (average absolute difference between observed and predicted probabilities) performance. Results: Incorporating pre-trained Poincar\'e embeddings resulted in modest and consistent improvements in discrimination performance compared to baseline models using randomly initialized Euclidean embeddings. ResNet models, particularly those using a 10-dimensional Poincar\'e embedding, showed enhanced calibration, whereas Transformer models maintained stable calibration across configurations. Discussion: Embedding clinical knowledge graphs into hyperbolic space and integrating these representations into deep learning models can improve lung cancer onset prediction by preserving the hierarchical structure of clinical terminologies used for prediction. This approach demonstrates a feasible method for combining data-driven feature extraction with established clinical knowledge.
Comparison of deep learning and conventional methods for disease onset prediction
Oct 14, 2024Background: Conventional prediction methods such as logistic regression and gradient boosting have been widely utilized for disease onset prediction for their reliability and interpretability. Deep learning methods promise enhanced prediction performance by extracting complex patterns from clinical data, but face challenges like data sparsity and high dimensionality. Methods: This study compares conventional and deep learning approaches to predict lung cancer, dementia, and bipolar disorder using observational data from eleven databases from North America, Europe, and Asia. Models were developed using logistic regression, gradient boosting, ResNet, and Transformer, and validated both internally and externally across the data sources. Discrimination performance was assessed using AUROC, and calibration was evaluated using Eavg. Findings: Across 11 datasets, conventional methods generally outperformed deep learning methods in terms of discrimination performance, particularly during external validation, highlighting their better transportability. Learning curves suggest that deep learning models require substantially larger datasets to reach the same performance levels as conventional methods. Calibration performance was also better for conventional methods, with ResNet showing the poorest calibration. Interpretation: Despite the potential of deep learning models to capture complex patterns in structured observational healthcare data, conventional models remain highly competitive for disease onset prediction, especially in scenarios involving smaller datasets and if lengthy training times need to be avoided. The study underscores the need for future research focused on optimizing deep learning models to handle the sparsity, high dimensionality, and heterogeneity inherent in healthcare datasets, and find new strategies to exploit the full capabilities of deep learning methods.
How little data do we need for patient-level prediction?
Aug 14, 2020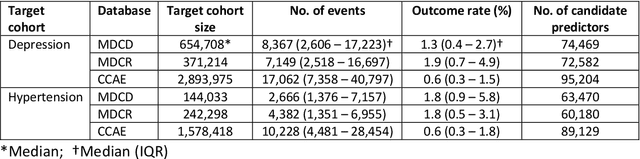


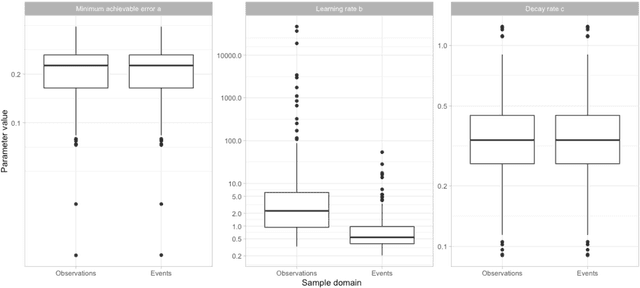
Objective: Provide guidance on sample size considerations for developing predictive models by empirically establishing the adequate sample size, which balances the competing objectives of improving model performance and reducing model complexity as well as computational requirements. Materials and Methods: We empirically assess the effect of sample size on prediction performance and model complexity by generating learning curves for 81 prediction problems in three large observational health databases, requiring training of 17,248 prediction models. The adequate sample size was defined as the sample size for which the performance of a model equalled the maximum model performance minus a small threshold value. Results: The adequate sample size achieves a median reduction of the number of observations between 9.5% and 78.5% for threshold values between 0.001 and 0.02. The median reduction of the number of predictors in the models at the adequate sample size varied between 8.6% and 68.3%, respectively. Discussion: Based on our results a conservative, yet significant, reduction in sample size and model complexity can be estimated for future prediction work. Though, if a researcher is willing to generate a learning curve a much larger reduction of the model complexity may be possible as suggested by a large outcome-dependent variability. Conclusion: Our results suggest that in most cases only a fraction of the available data was sufficient to produce a model close to the performance of one developed on the full data set, but with a substantially reduced model complexity.