 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Compression for Distributed Deep Learning
May 27, 2019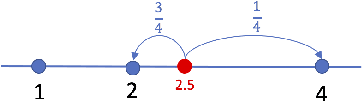



Due to their hunger for big data, modern deep learning models are trained in parallel, often in distributed environments, where communication of model updates is the bottleneck. Various update compression (e.g., quantization, sparsification, dithering) techniques have been proposed in recent years as a successful tool to alleviate this problem. In this work, we introduce a new, remarkably simple and theoretically and practically effective compression technique, which we call natural compression (NC). Our technique is applied individually to all entries of the to-be-compressed update vector and works by randomized rounding to the nearest (negative or positive) power of two. NC is "natural" since the nearest power of two of a real expressed as a float can be obtained without any computation, simply by ignoring the mantissa. We show that compared to no compression, NC increases the second moment of the compressed vector by the tiny factor 9/8 only, which means that the effect of NC on the convergence speed of popular training algorithms, such as distributed SGD, is negligible. However, the communications savings enabled by NC are substantial, leading to 3-4x improvement in overall theoretical running time. For applications requiring more aggressive compression, we generalize NC to natural dithering, which we prove is exponentially better than the immensely popular random dithering technique. Our compression operators can be used on their own or in combination with existing operators for a more aggressive combined effect. Finally, we show that N is particularly effective for the in-network aggregation (INA) framework for distributed training, where the update aggregation is done on a switch, which can only perform integer computations.