 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTypologie des comportements utilisateurs : {é}tude exploratoire des sessions de recherche complexe sur le Web
Dec 04, 2024In this study, we propose an exploratory approach aiming at a typology of user behaviour during a Web search session. We describe a typology based on generic IR variables (e.g. number of queries), but also on the study of topic (propositions with distinct semantic content defined from the search statement). To this end, we gathered experimental data enabling us to study variations across users (N=70) for the same task. We performed a multidimensional analysis and propose a 5 classes typology based on the individual behaviours during the processing of a complex search task.
Talking to oneself in CMC: a study of self replies in Wikipedia talk pages
Nov 28, 2024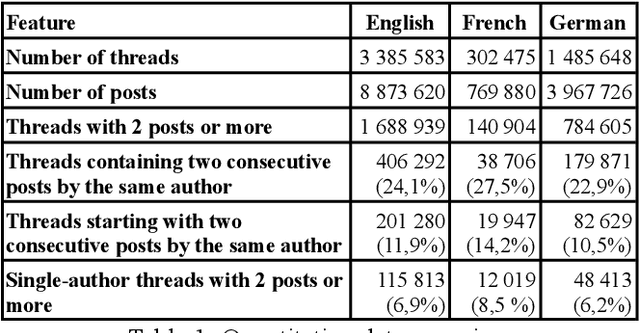



This study proposes a qualitative analysis of self replies in Wikipedia talk pages, more precisely when the first two messages of a discussion are written by the same user. This specific pattern occurs in more than 10% of threads with two messages or more and can be explained by a number of reasons. After a first examination of the lexical specificities of second messages, we propose a seven categories typology and use it to annotate two reference samples (English and French) of 100 threads each. Finally, we analyse and compare the performance of human annotators (who reach a reasonable global efficiency) and instruction-tuned LLMs (which encounter important difficulties with several categories).
Message du troisi{è}me type : irruption d'un tiers dans un dialogue en ligne
Jun 28, 2024


Our study focuses on Wikipedia talk pages, from a global perspective analyzing contributors' behaviors in online interactions. Using a corpus comprising all Wikipedia talk pages in French, totaling more than 300,000 discussion threads, we examine how discussions with more than two participants (multiparty conversation) unfold and we specifically investigate the role of a third participant's intervention when two Wikipedians have already initiated an exchange. In this regard, we concentrate on the sequential structure of these interactions in terms of articulation among different participants and aim to specify this third message by exploring its lexical particularities, while also proposing an initial typology of the third participant's message role and how it aligns with preceding messages.
Le sens de la famille : analyse du vocabulaire de la parent{é} par les plongements de mots
Jun 28, 2024

In this study, we propose a corpus analysis of an area of the French lexicon that is both dense and highly structured: the vocabulary of family relationships. Starting with a lexicon of 25 nouns designating the main relationships (son, cousin, mother, grandfather, sister-in-law etc.), we examine how these terms are positioned in relation to each other through distributional analyses based on the use of these terms in corpora. We show that distributional information can capture certain features that organize this vocabulary (descent, alliance, siblings, genre), in ways that vary according to the different corpora compared.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.