 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOWLOOP: Interfaces for Mapping OWL Axioms into OOP Hierarchies
Apr 19, 2024The paper tackles the issue of mapping logic axioms formalised in the Ontology Web Language (OWL) within the Object-Oriented Programming (OOP) paradigm. The issues of mapping OWL axioms hierarchies and OOP objects hierarchies are due to OWL-based reasoning algorithms, which might change an OWL hierarchy at runtime; instead, OOP hierarchies are usually defined as static structures. Although programming paradigms based on reflection allow changing the OOP hierarchies at runtime and mapping OWL axioms dynamically, there are no currently available mechanisms that do not limit the reasoning algorithms. Thus, the factory-based paradigm is typically used since it decouples the OWL and OOP hierarchies. However, the factory inhibits OOP polymorphism and introduces a paradigm shift with respect to widely accepted OOP paradigms. We present the OWLOOP API, which exploits the factory to not limit reasoning algorithms, and it provides novel OOP interfaces concerning the axioms in an ontology. OWLOOP is designed to limit the paradigm shift required for using ontologies while improving, through OOP-like polymorphism, the modularity of software architectures that exploit logic reasoning. The paper details our OWL to OOP mapping mechanism, and it shows the benefits and limitations of OWLOOP through examples concerning a robot in a smart environment.
Learning Symbolic Task Representation from a Human-Led Demonstration: A Memory to Store, Retrieve, Consolidate, and Forget Experiences
Apr 19, 2024We present a symbolic learning framework inspired by cognitive-like memory functionalities (i.e., storing, retrieving, consolidating and forgetting) to generate task representations to support high-level task planning and knowledge bootstrapping. We address a scenario involving a non-expert human, who performs a single task demonstration, and a robot, which online learns structured knowledge to re-execute the task based on experiences, i.e., observations. We consider a one-shot learning process based on non-annotated data to store an intelligible representation of the task, which can be refined through interaction, e.g., via verbal or visual communication. Our general-purpose framework relies on fuzzy Description Logic, which has been used to extend the previously developed Scene Identification and Tagging algorithm. In this paper, we exploit such an algorithm to implement cognitive-like memory functionalities employing scores that rank memorised observations over time based on simple heuristics. Our main contribution is the formalisation of a framework that can be used to systematically investigate different heuristics for bootstrapping hierarchical knowledge representations based on robot observations. Through an illustrative assembly task scenario, the paper presents the performance of our framework to discuss its benefits and limitations.
Incremental Bootstrapping and Classification of Structured Scenes in a Fuzzy Ontology
Apr 17, 2024



We foresee robots that bootstrap knowledge representations and use them for classifying relevant situations and making decisions based on future observations. Particularly for assistive robots, the bootstrapping mechanism might be supervised by humans who should not repeat a training phase several times and should be able to refine the taught representation. We consider robots that bootstrap structured representations to classify some intelligible categories. Such a structure should be incrementally bootstrapped, i.e., without invalidating the identified category models when a new additional category is considered. To tackle this scenario, we presented the Scene Identification and Tagging (SIT) algorithm, which bootstraps structured knowledge representation in a crisp OWL-DL ontology. Over time, SIT bootstraps a graph representing scenes, sub-scenes and similar scenes. Then, SIT can classify new scenes within the bootstrapped graph through logic-based reasoning. However, SIT has issues with sensory data because its crisp implementation is not robust to perception noises. This paper presents a reformulation of SIT within the fuzzy domain, which exploits a fuzzy DL ontology to overcome the robustness issues. By comparing the performances of fuzzy and crisp implementations of SIT, we show that fuzzy SIT is robust, preserves the properties of its crisp formulation, and enhances the bootstrapped representations. On the contrary, the fuzzy implementation of SIT leads to less intelligible knowledge representations than the one bootstrapped in the crisp domain.
OWLOOP: A Modular API to Describe OWL Axioms in OOP Objects Hierarchies
Dec 31, 2021
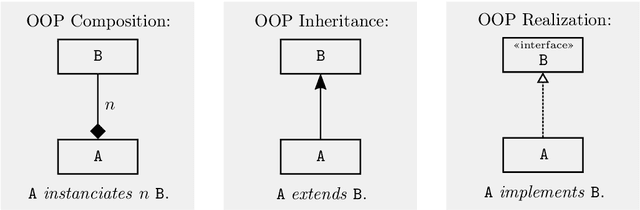

OWLOOP is an Application Programming Interface (API) for using the Ontology Web Language (OWL) by the means of Object-Oriented Programming (OOP). It is common to design software architectures using the OOP paradigm for increasing their modularity. If the components of an architecture also exploit OWL ontologies for knowledge representation and reasoning, they would require to be interfaced with OWL axioms. Since OWL does not adhere to the OOP paradigm, such an interface often leads to boilerplate code affecting modularity, and OWLOOP is designed to address this issue as well as the associated computational aspects. We present an extension of the OWL-API to provide a general-purpose interface between OWL axioms subject to reasoning and modular OOP objects hierarchies.
* This version of the manuscript has been published on the SoftwareX Elsevier journal in January 2022. The manuscript is made of 21 pages, which include 3 tables, 6 figures, and 4 listings
Human Activity Recognition Models in Ontology Networks
May 05, 2021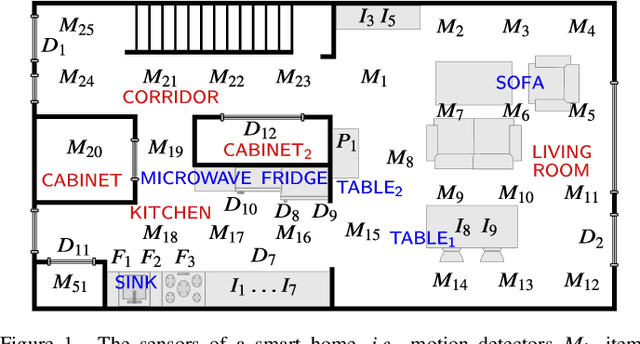
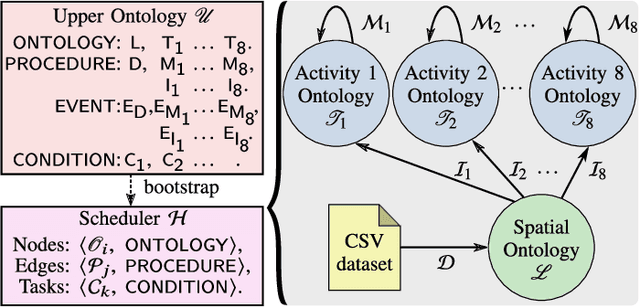
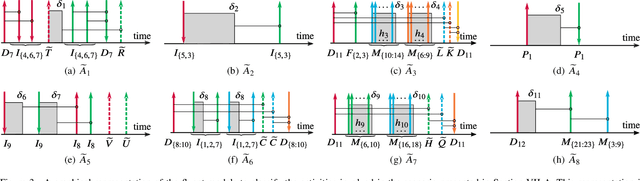
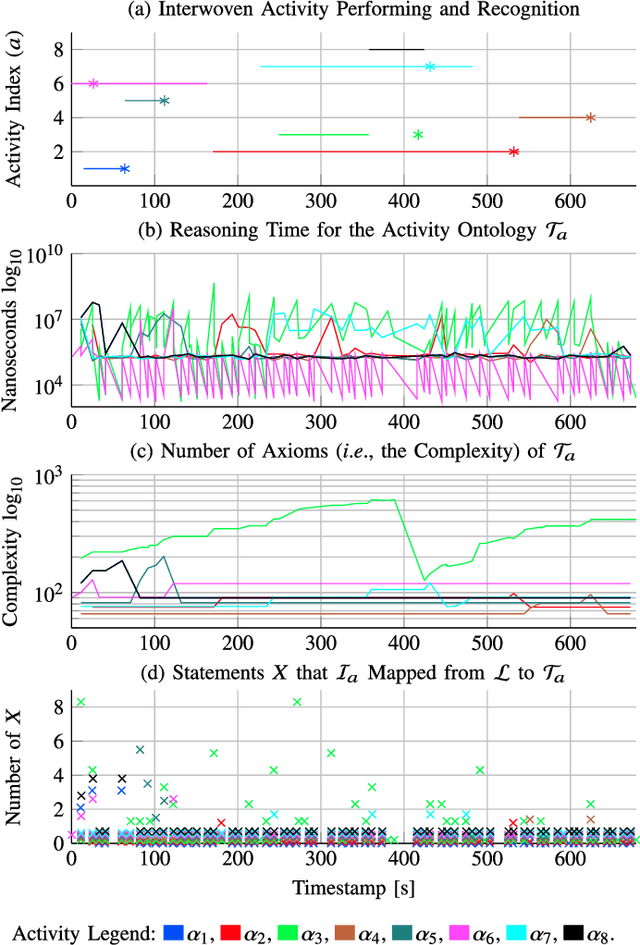
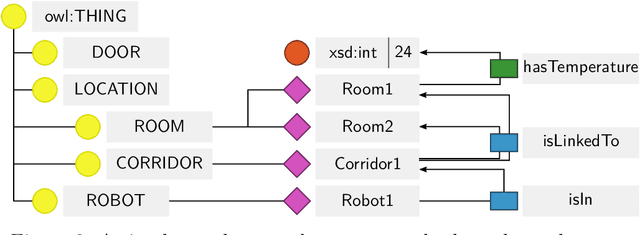
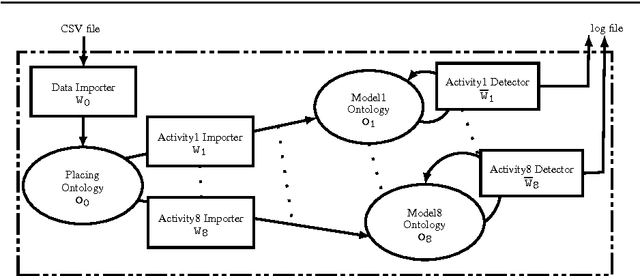
We present Arianna+, a framework to design networks of ontologies for representing knowledge enabling smart homes to perform human activity recognition online. In the network, nodes are ontologies allowing for various data contextualisation, while edges are general-purpose computational procedures elaborating data. Arianna+ provides a flexible interface between the inputs and outputs of procedures and statements, which are atomic representations of ontological knowledge. Arianna+ schedules procedures on the basis of events by employing logic-based reasoning, i.e., by checking the classification of certain statements in the ontologies. Each procedure involves input and output statements that are differently contextualised in the ontologies based on specific prior knowledge. Arianna+ allows to design networks that encode data within multiple contexts and, as a reference scenario, we present a modular network based on a spatial context shared among all activities and a temporal context specialised for each activity to be recognised. In the paper, we argue that a network of small ontologies is more intelligible and has a reduced computational load than a single ontology encoding the same knowledge. Arianna+ integrates in the same architecture heterogeneous data processing techniques, which may be better suited to different contexts. Thus, we do not propose a new algorithmic approach to activity recognition, instead, we focus on the architectural aspects for accommodating logic-based and data-driven activity models in a context-oriented way. Also, we discuss how to leverage data contextualisation and reasoning for activity recognition, and to support an iterative development process driven by domain experts.
* The paper has been accepted for publication in the IEEE Transactions on Cybernetics journal on April 2021 and with DOI 10.1109/TCYB.2021.3073539. It is an extension of arXiv:1707.03988v1 and it is related to the arXiv:1809.08208v1 article. It contains 20 pages, 6 figures, 4 tables and 2 Appendices
Arianna+: Scalable Human Activity Recognition by Reasoning with a Network of Ontologies
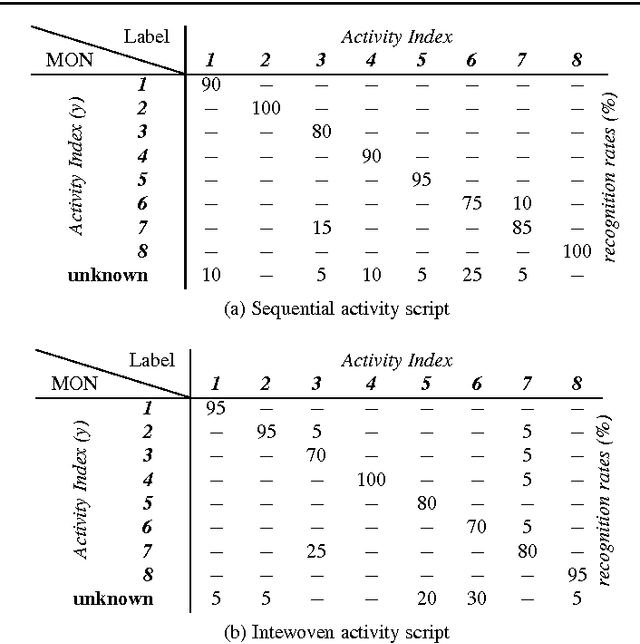
Sep 21, 2018Aging population ratios are rising significantly. Meanwhile, smart home based health monitoring services are evolving rapidly to become a viable alternative to traditional healthcare solutions. Such services can augment qualitative analyses done by gerontologists with quantitative data. Hence, the recognition of Activities of Daily Living (ADL) has become an active domain of research in recent times. For a system to perform human activity recognition in a real-world environment, multiple requirements exist, such as scalability, robustness, ability to deal with uncertainty (e.g., missing sensor data), to operate with multi-occupants and to take into account their privacy and security. This paper attempts to address the requirements of scalability and robustness, by describing a reasoning mechanism based on modular spatial and/or temporal context models as a network of ontologies. The reasoning mechanism has been implemented in a smart home system referred to as Arianna+. The paper presents and discusses a use case, and experiments are performed on a simulated dataset, to showcase Arianna+'s modularity feature, internal working, and computational performance. Results indicate scalability and robustness for human activity recognition processes.
Towards a new paradigm for assistive technology at home: research challenges, design issues and performance assessment
Oct 27, 2017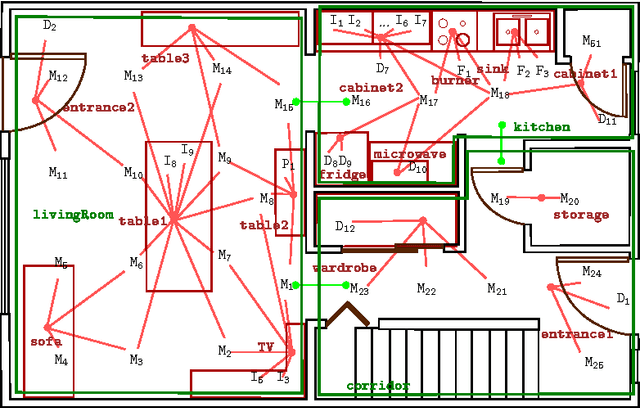
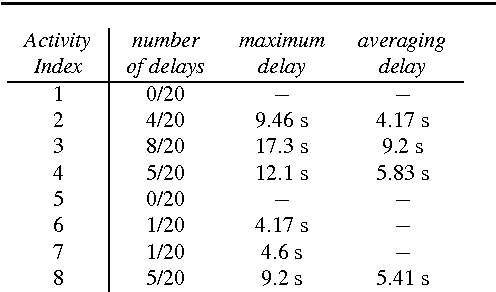
Providing elderly and people with special needs, including those suffering from physical disabilities and chronic diseases, with the possibility of retaining their independence at best is one of the most important challenges our society is expected to face. Assistance models based on the home care paradigm are being adopted rapidly in almost all industrialized and emerging countries. Such paradigms hypothesize that it is necessary to ensure that the so-called Activities of Daily Living are correctly and regularly performed by the assisted person to increase the perception of an improved quality of life. This chapter describes the computational inference engine at the core of Arianna, a system able to understand whether an assisted person performs a given set of ADL and to motivate him/her in performing them through a speech-mediated motivational dialogue, using a set of nearables to be installed in an apartment, plus a wearable to be worn or fit in garments.
Scene learning, recognition and similarity detection in a fuzzy ontology via human examples
Sep 27, 2017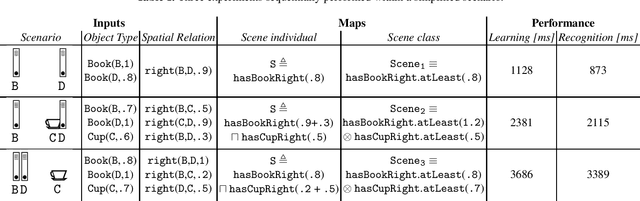
This paper introduces a Fuzzy Logic framework for scene learning, recognition and similarity detection, where scenes are taught via human examples. The framework allows a robot to: (i) deal with the intrinsic vagueness associated with determining spatial relations among objects; (ii) infer similarities and dissimilarities in a set of scenes, and represent them in a hierarchical structure represented in a Fuzzy ontology. In this paper, we briefly formalize our approach and we provide a few use cases by way of illustration. Nevertheless, we discuss how the framework can be used in real-world scenarios.
A ROS multi-ontology references services: OWL reasoners and application prototyping issues
Jun 30, 2017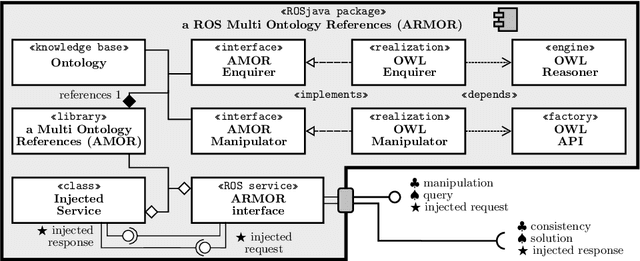
The challenge of sharing and communicating information is crucial in complex human-robot interaction (HRI) scenarios. Ontologies and symbolic reasoning are the state-of-the-art approaches for a natural representation of knowledge, especially within the Semantic Web domain. In such a context, scripted paradigms have been adopted to achieve high expressiveness. Nevertheless, since symbolic reasoning is a high complexity problem, optimizing its performance requires a careful design of the knowledge. Specifically, a robot architecture requires the integration of several components implementing different behaviors and generating a series of beliefs. Most of the components are expected to access, manipulate, and reason upon a run-time generated semantic representation of knowledge grounding robot behaviors and perceptions through formal axioms, with soft real-time requirements.