 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving generalization in large language models by learning prefix subspaces
Oct 24, 2023


This article focuses on large language models (LLMs) fine-tuning in the scarce data regime (also known as the "few-shot" learning setting). We propose a method to increase the generalization capabilities of LLMs based on neural network subspaces. This optimization method, recently introduced in computer vision, aims to improve model generalization by identifying wider local optima through the joint optimization of an entire simplex of models in parameter space. Its adaptation to massive, pretrained transformers, however, poses some challenges. First, their considerable number of parameters makes it difficult to train several models jointly, and second, their deterministic parameter initialization schemes make them unfit for the subspace method as originally proposed. We show in this paper that "Parameter Efficient Fine-Tuning" (PEFT) methods, however, are perfectly compatible with this original approach, and propose to learn entire simplex of continuous prefixes. We test our method on a variant of the GLUE benchmark adapted to the few-shot learning setting, and show that both our contributions jointly lead to a gain in average performances compared to sota methods. The implementation can be found at the following link: https://github.com/Liloulou/prefix_subspace
Learning a binary search with a recurrent neural network. A novel approach to ordinal regression analysis
Jan 07, 2021
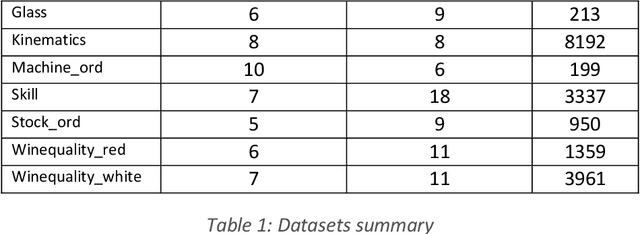
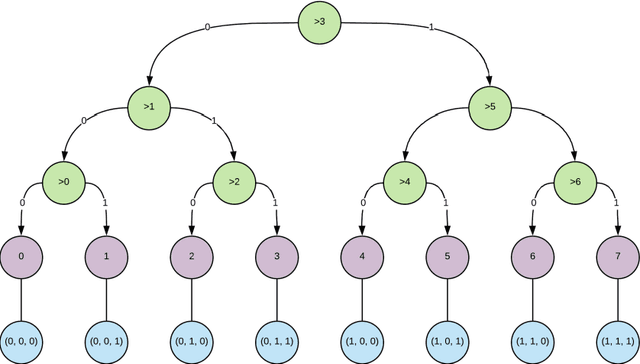
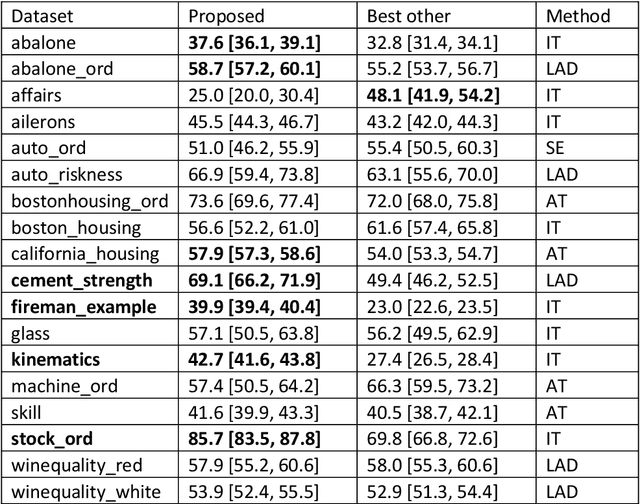
Deep neural networks are a family of computational models that are naturally suited to the analysis of hierarchical data such as, for instance, sequential data with the use of recurrent neural networks. In the other hand, ordinal regression is a well-known predictive modelling problem used in fields as diverse as psychometry to deep neural network based voice modelling. Their specificity lies in the properties of their outcome variable, typically considered as a categorical variable with natural ordering properties, typically allowing comparisons between different states ("a little" is less than "somewhat" which is itself less than "a lot", with transitivity allowed). This article investigates the application of sequence-to-sequence learning methods provided by the deep learning framework in ordinal regression, by formulating the ordinal regression problem as a sequential binary search. A method for visualizing the model's explanatory variables according to the ordinal target variable is proposed, that bears some similarities to linear discriminant analysis. The method is compared to traditional ordinal regression methods on a number of benchmark dataset, and is shown to have comparable or significantly better predictive power.
Neural translation and automated recognition of ICD10 medical entities from natural language
Mar 27, 2020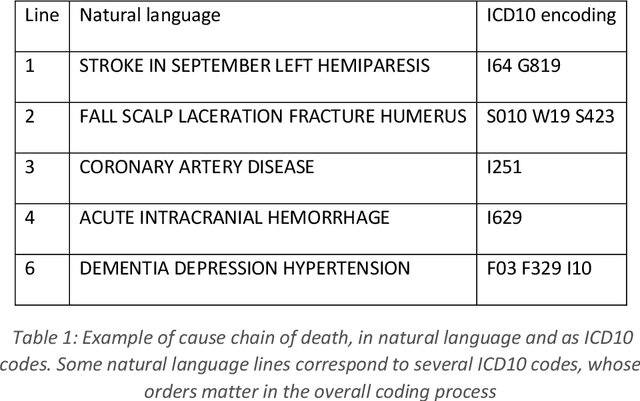
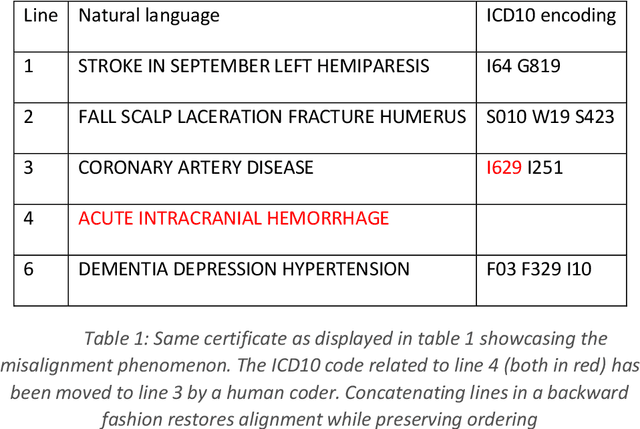
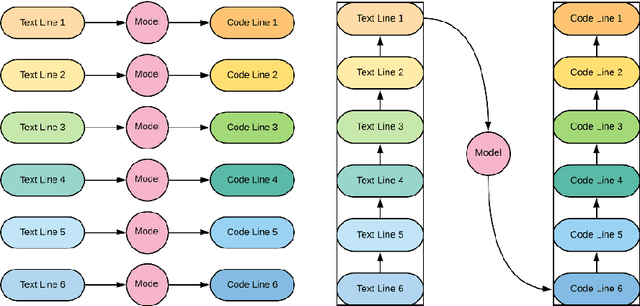

The recognition of medical entities from natural language is an ubiquitous problem in the medical field, with applications ranging from medical act coding to the analysis of electronic health data for public health. It is however a complex task usually requiring human expert intervention, thus making it expansive and time consuming. The recent advances in artificial intelligence, specifically the raise of deep learning methods, has enabled computers to make efficient decisions on a number of complex problems, with the notable example of neural sequence models and their powerful applications in natural language processing. They however require a considerable amount of data to learn from, which is typically their main limiting factor. However, the C\'epiDc stores an exhaustive database of death certificates at the French national scale, amounting to several millions of natural language examples provided with their associated human coded medical entities available to the machine learning practitioner. This article investigates the applications of deep neural sequence models to the medical entity recognition from natural language problem.
A deep artificial neural network based model for underlying cause of death prediction from death certificates
Aug 26, 2019



Underlying cause of death coding from death certificates is a process that is nowadays undertaken mostly by humans with a potential assistance from expert systems such as the Iris software. It is as a consequence an expensive process that can in addition suffer from geospatial discrepancies, thus severely impairing the comparability of death statistics at the international level. The recent advances in artificial intelligence, specifically the raise of deep learning methods, has enabled computers to make efficient decisions on a number of complex problem that were typically considered as out of reach without human assistance. They however require a considerable amount of data to learn from, which is typically their main limiting factor. However, the C\'epiDc stores an exhaustive database of death certificate at the French national scale, amounting to several millions training example available for the machine learning practitioner. This article presents a deep learning based tool for automated coding of the underlying cause of death from the data contained in death certificates with 97.8% accuracy, a substantial achievement compared to the Iris software and its 75% accuracy assessed on the same test examples. Such an improvement opens a whole field of new applications, from nosologist-level batch automated coding to international and temporal harmonization of cause of death statistics.
Deep clustering of longitudinal data
Feb 09, 2018



Deep neural networks are a family of computational models that have led to a dramatical improvement of the state of the art in several domains such as image, voice or text analysis. These methods provide a framework to model complex, non-linear interactions in large datasets, and are naturally suited to the analysis of hierarchical data such as, for instance, longitudinal data with the use of recurrent neural networks. In the other hand, cohort studies have become a tool of importance in the research field of epidemiology. In such studies, variables are measured repeatedly over time, to allow the practitioner to study their temporal evolution as trajectories, and, as such, as longitudinal data. This paper investigates the application of the advanced modelling techniques provided by the deep learning framework in the analysis of the longitudinal data provided by cohort studies. Methods: A method for visualizing and clustering longitudinal dataset is proposed, and compared to other widely used approaches to the problem on both real and simulated datasets. Results: The proposed method is shown to be coherent with the preexisting procedures on simple tasks, and to outperform them on more complex tasks such as the partitioning of longitudinal datasets into non-spherical clusters. Conclusion: Deep artificial neural networks can be used to visualize longitudinal data in a low dimensional manifold that is much simpler to interpret than traditional longitudinal plots are. Consequently, practitioners should start considering the use of deep artificial neural networks for the analysis of their longitudinal data in studies to come.