 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXIMP: Cross Graph Inter-Message Passing for Molecular Property Prediction
Jan 26, 2026Accurate molecular property prediction is central to drug discovery, yet graph neural networks often underperform in data-scarce regimes and fail to surpass traditional fingerprints. We introduce cross-graph inter-message passing (XIMP), which performs message passing both within and across multiple related graph representations. For small molecules, we combine the molecular graph with scaffold-aware junction trees and pharmacophore-encoding extended reduced graphs, integrating complementary abstractions. While prior work is either limited to a single abstraction or non-iterative communication across graphs, XIMP supports an arbitrary number of abstractions and both direct and indirect communication between them in each layer. Across ten diverse molecular property prediction tasks, XIMP outperforms state-of-the-art baselines in most cases, leveraging interpretable abstractions as an inductive bias that guides learning toward established chemical concepts, enhancing generalization in low-data settings.
Weisfeiler and Leman Go Gambling: Why Expressive Lottery Tickets Win
Jun 04, 2025The lottery ticket hypothesis (LTH) is well-studied for convolutional neural networks but has been validated only empirically for graph neural networks (GNNs), for which theoretical findings are largely lacking. In this paper, we identify the expressivity of sparse subnetworks, i.e. their ability to distinguish non-isomorphic graphs, as crucial for finding winning tickets that preserve the predictive performance. We establish conditions under which the expressivity of a sparsely initialized GNN matches that of the full network, particularly when compared to the Weisfeiler-Leman test, and in that context put forward and prove a Strong Expressive Lottery Ticket Hypothesis. We subsequently show that an increased expressivity in the initialization potentially accelerates model convergence and improves generalization. Our findings establish novel theoretical foundations for both LTH and GNN research, highlighting the importance of maintaining expressivity in sparsely initialized GNNs. We illustrate our results using examples from drug discovery.
On the Relationship Between Robustness and Expressivity of Graph Neural Networks
Apr 18, 2025We investigate the vulnerability of Graph Neural Networks (GNNs) to bit-flip attacks (BFAs) by introducing an analytical framework to study the influence of architectural features, graph properties, and their interaction. The expressivity of GNNs refers to their ability to distinguish non-isomorphic graphs and depends on the encoding of node neighborhoods. We examine the vulnerability of neural multiset functions commonly used for this purpose and establish formal criteria to characterize a GNN's susceptibility to losing expressivity due to BFAs. This enables an analysis of the impact of homophily, graph structural variety, feature encoding, and activation functions on GNN robustness. We derive theoretical bounds for the number of bit flips required to degrade GNN expressivity on a dataset, identifying ReLU-activated GNNs operating on highly homophilous graphs with low-dimensional or one-hot encoded features as particularly susceptible. Empirical results using ten real-world datasets confirm the statistical significance of our key theoretical insights and offer actionable results to mitigate BFA risks in expressivity-critical applications.
Crossfire: An Elastic Defense Framework for Graph Neural Networks Under Bit Flip Attacks
Jan 23, 2025Bit Flip Attacks (BFAs) are a well-established class of adversarial attacks, originally developed for Convolutional Neural Networks within the computer vision domain. Most recently, these attacks have been extended to target Graph Neural Networks (GNNs), revealing significant vulnerabilities. This new development naturally raises questions about the best strategies to defend GNNs against BFAs, a challenge for which no solutions currently exist. Given the applications of GNNs in critical fields, any defense mechanism must not only maintain network performance, but also verifiably restore the network to its pre-attack state. Verifiably restoring the network to its pre-attack state also eliminates the need for costly evaluations on test data to ensure network quality. We offer first insights into the effectiveness of existing honeypot- and hashing-based defenses against BFAs adapted from the computer vision domain to GNNs, and characterize the shortcomings of these approaches. To overcome their limitations, we propose Crossfire, a hybrid approach that exploits weight sparsity and combines hashing and honeypots with bit-level correction of out-of-distribution weight elements to restore network integrity. Crossfire is retraining-free and does not require labeled data. Averaged over 2,160 experiments on six benchmark datasets, Crossfire offers a 21.8% higher probability than its competitors of reconstructing a GNN attacked by a BFA to its pre-attack state. These experiments cover up to 55 bit flips from various attacks. Moreover, it improves post-repair prediction quality by 10.85%. Computational and storage overheads are negligible compared to the inherent complexity of even the simplest GNNs.
Attacking Graph Neural Networks with Bit Flips: Weisfeiler and Lehman Go Indifferent
Nov 02, 2023



Prior attacks on graph neural networks have mostly focused on graph poisoning and evasion, neglecting the network's weights and biases. Traditional weight-based fault injection attacks, such as bit flip attacks used for convolutional neural networks, do not consider the unique properties of graph neural networks. We propose the Injectivity Bit Flip Attack, the first bit flip attack designed specifically for graph neural networks. Our attack targets the learnable neighborhood aggregation functions in quantized message passing neural networks, degrading their ability to distinguish graph structures and losing the expressivity of the Weisfeiler-Lehman test. Our findings suggest that exploiting mathematical properties specific to certain graph neural network architectures can significantly increase their vulnerability to bit flip attacks. Injectivity Bit Flip Attacks can degrade the maximal expressive Graph Isomorphism Networks trained on various graph property prediction datasets to random output by flipping only a small fraction of the network's bits, demonstrating its higher destructive power compared to a bit flip attack transferred from convolutional neural networks. Our attack is transparent and motivated by theoretical insights which are confirmed by extensive empirical results.
Neural Network Augmented Compartmental Pandemic Models
Dec 15, 2022Compartmental models are a tool commonly used in epidemiology for the mathematical modelling of the spread of infectious diseases, with their most popular representative being the Susceptible-Infected-Removed (SIR) model and its derivatives. However, current SIR models are bounded in their capabilities to model government policies in the form of non-pharmaceutical interventions (NPIs) and weather effects and offer limited predictive power. More capable alternatives such as agent based models (ABMs) are computationally expensive and require specialized hardware. We introduce a neural network augmented SIR model that can be run on commodity hardware, takes NPIs and weather effects into account and offers improved predictive power as well as counterfactual analysis capabilities. We demonstrate our models improvement of the state-of-the-art modeling COVID-19 in Austria during the 03.2020 to 03.2021 period and provide an outlook for the future up to 01.2024.
Adaptive Precision Training (ADEPT): A dynamic fixed point quantized sparsifying training approach for DNNs
Aug 13, 2021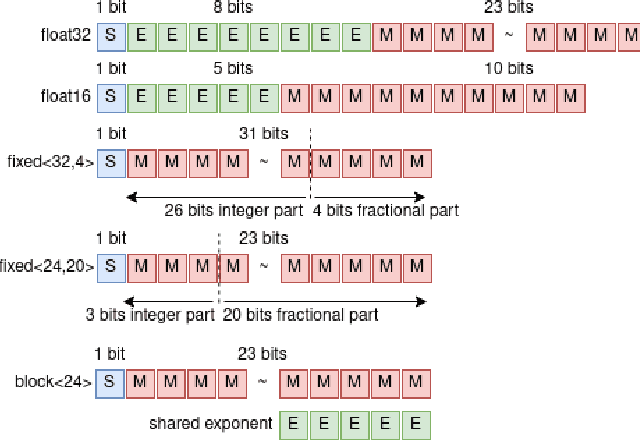
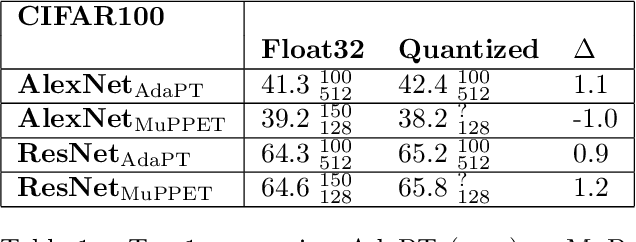
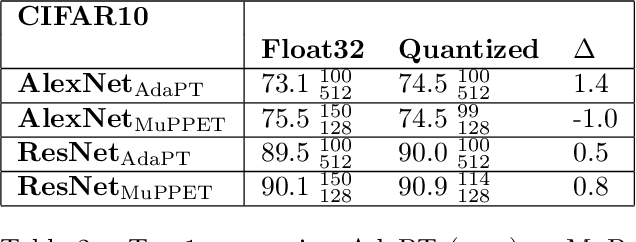
Quantization is a technique for reducing deep neural networks (DNNs) training and inference times, which is crucial for training in resource constrained environments or time critical inference applications. State-of-the-art (SOTA) approaches focus on post-training quantization, i.e. quantization of pre-trained DNNs for speeding up inference. Little work on quantized training exists and usually, existing approaches re-quire full precision refinement afterwards or enforce a global word length across the whole DNN. This leads to suboptimal bitwidth-to-layers assignments and re-source usage. Recognizing these limits, we introduce ADEPT, a new quantized sparsifying training strategy using information theory-based intra-epoch precision switching to find on a per-layer basis the lowest precision that causes no quantization-induced information loss while keeping precision high enough for future learning steps to not suffer from vanishing gradients, producing a fully quantized DNN. Based on a bitwidth-weighted MAdds performance model, our approach achieves an average speedup of 1.26 and model size reduction of 0.53 compared to standard training in float32 with an average accuracy increase of 0.98% on AlexNet/ResNet on CIFAR10/100.
Dynamic Neural Network Architectural and Topological Adaptation and Related Methods -- A Survey
Jul 28, 2021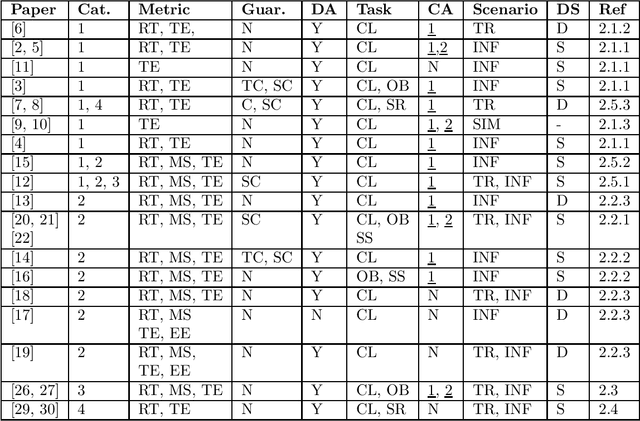
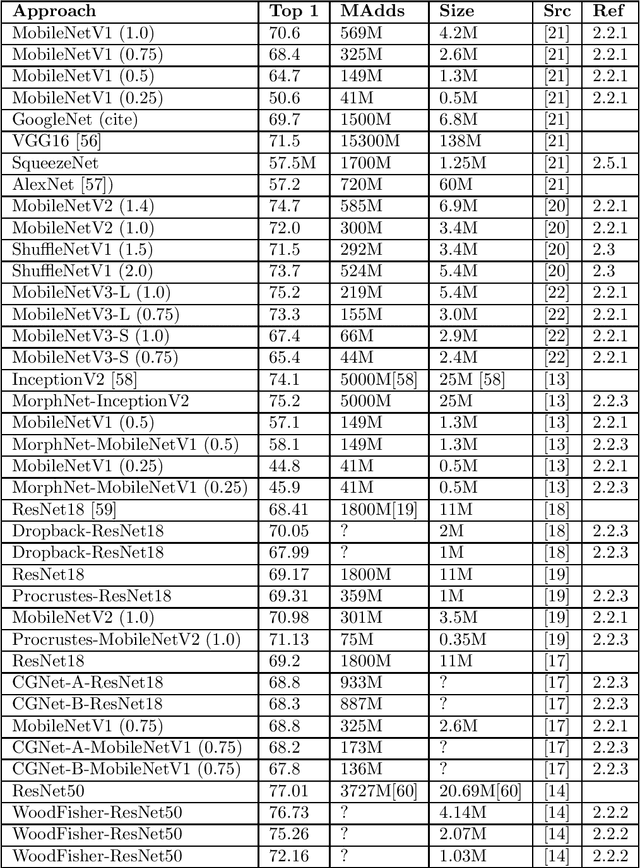
Training and inference in deep neural networks (DNNs) has, due to a steady increase in architectural complexity and data set size, lead to the development of strategies for reducing time and space requirements of DNN training and inference, which is of particular importance in scenarios where training takes place in resource constrained computation environments or inference is part of a time critical application. In this survey, we aim to provide a general overview and categorization of state-of-the-art (SOTA) of techniques to reduced DNN training and inference time and space complexities with a particular focus on architectural adaptions.