 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Precision Training (ADEPT): A dynamic fixed point quantized sparsifying training approach for DNNs
Aug 13, 2021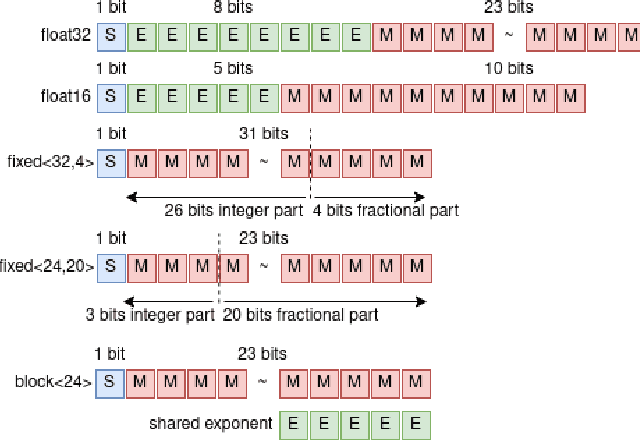
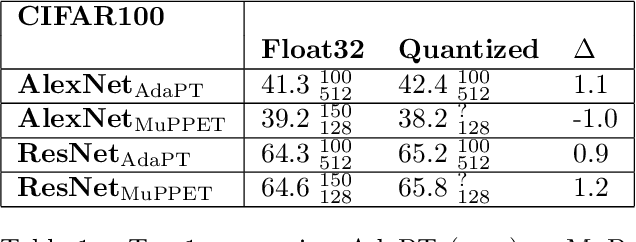
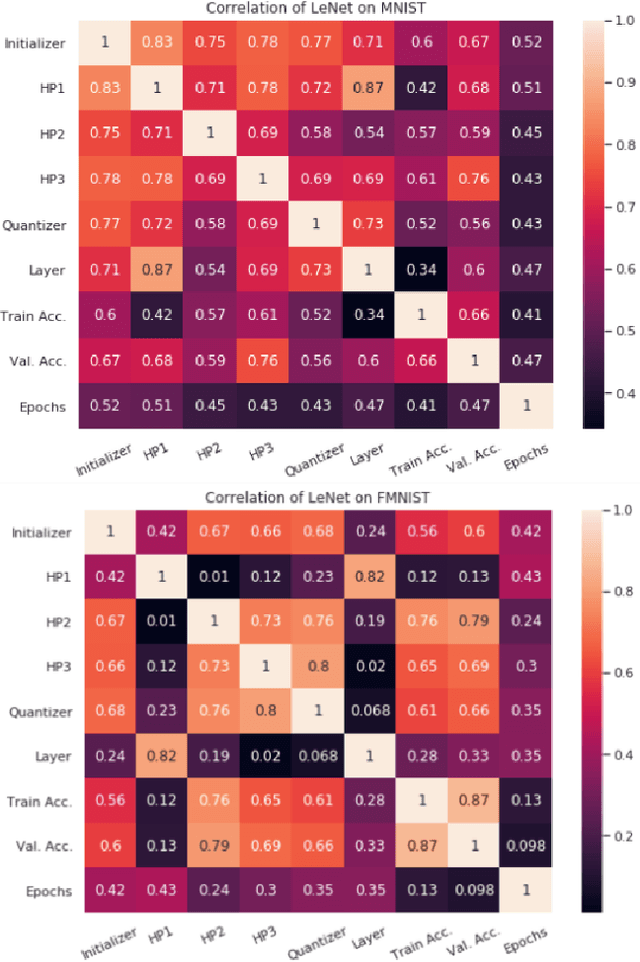
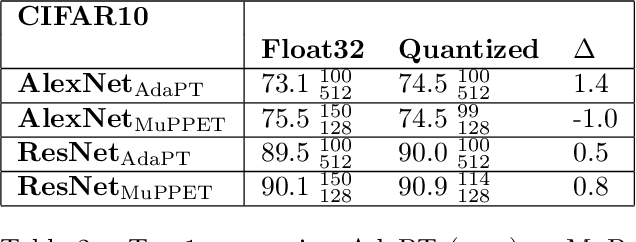
Quantization is a technique for reducing deep neural networks (DNNs) training and inference times, which is crucial for training in resource constrained environments or time critical inference applications. State-of-the-art (SOTA) approaches focus on post-training quantization, i.e. quantization of pre-trained DNNs for speeding up inference. Little work on quantized training exists and usually, existing approaches re-quire full precision refinement afterwards or enforce a global word length across the whole DNN. This leads to suboptimal bitwidth-to-layers assignments and re-source usage. Recognizing these limits, we introduce ADEPT, a new quantized sparsifying training strategy using information theory-based intra-epoch precision switching to find on a per-layer basis the lowest precision that causes no quantization-induced information loss while keeping precision high enough for future learning steps to not suffer from vanishing gradients, producing a fully quantized DNN. Based on a bitwidth-weighted MAdds performance model, our approach achieves an average speedup of 1.26 and model size reduction of 0.53 compared to standard training in float32 with an average accuracy increase of 0.98% on AlexNet/ResNet on CIFAR10/100.