 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossfire: An Elastic Defense Framework for Graph Neural Networks Under Bit Flip Attacks
Jan 23, 2025Bit Flip Attacks (BFAs) are a well-established class of adversarial attacks, originally developed for Convolutional Neural Networks within the computer vision domain. Most recently, these attacks have been extended to target Graph Neural Networks (GNNs), revealing significant vulnerabilities. This new development naturally raises questions about the best strategies to defend GNNs against BFAs, a challenge for which no solutions currently exist. Given the applications of GNNs in critical fields, any defense mechanism must not only maintain network performance, but also verifiably restore the network to its pre-attack state. Verifiably restoring the network to its pre-attack state also eliminates the need for costly evaluations on test data to ensure network quality. We offer first insights into the effectiveness of existing honeypot- and hashing-based defenses against BFAs adapted from the computer vision domain to GNNs, and characterize the shortcomings of these approaches. To overcome their limitations, we propose Crossfire, a hybrid approach that exploits weight sparsity and combines hashing and honeypots with bit-level correction of out-of-distribution weight elements to restore network integrity. Crossfire is retraining-free and does not require labeled data. Averaged over 2,160 experiments on six benchmark datasets, Crossfire offers a 21.8% higher probability than its competitors of reconstructing a GNN attacked by a BFA to its pre-attack state. These experiments cover up to 55 bit flips from various attacks. Moreover, it improves post-repair prediction quality by 10.85%. Computational and storage overheads are negligible compared to the inherent complexity of even the simplest GNNs.
Adaptive Precision Training (ADEPT): A dynamic fixed point quantized sparsifying training approach for DNNs
Aug 13, 2021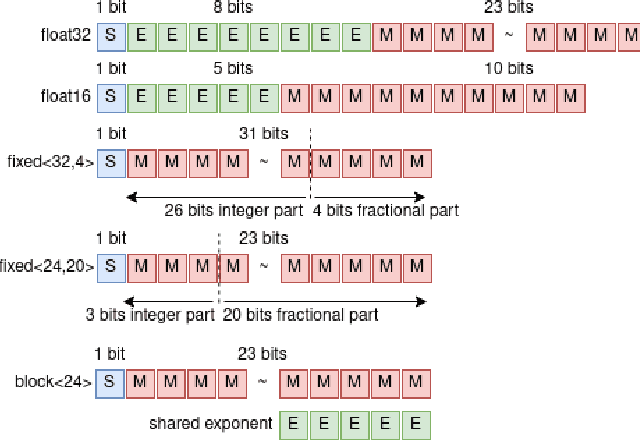
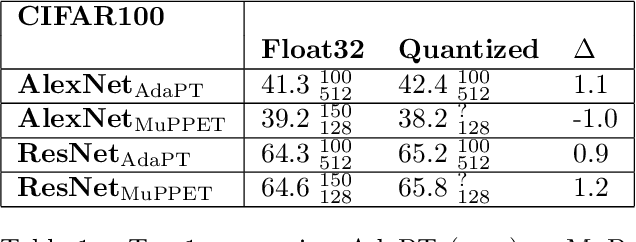
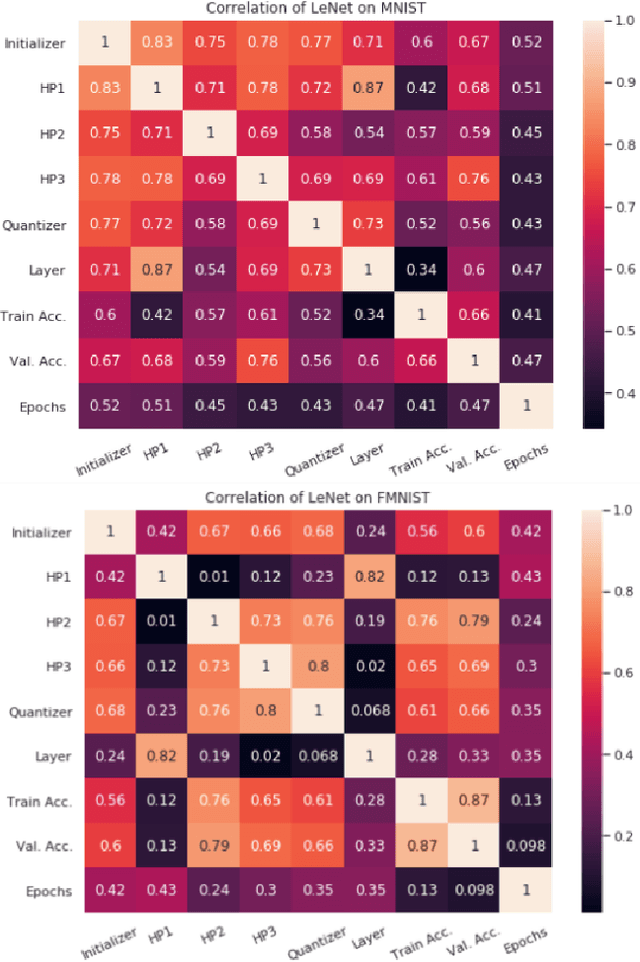
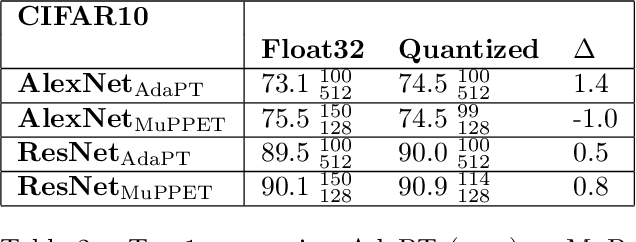
Quantization is a technique for reducing deep neural networks (DNNs) training and inference times, which is crucial for training in resource constrained environments or time critical inference applications. State-of-the-art (SOTA) approaches focus on post-training quantization, i.e. quantization of pre-trained DNNs for speeding up inference. Little work on quantized training exists and usually, existing approaches re-quire full precision refinement afterwards or enforce a global word length across the whole DNN. This leads to suboptimal bitwidth-to-layers assignments and re-source usage. Recognizing these limits, we introduce ADEPT, a new quantized sparsifying training strategy using information theory-based intra-epoch precision switching to find on a per-layer basis the lowest precision that causes no quantization-induced information loss while keeping precision high enough for future learning steps to not suffer from vanishing gradients, producing a fully quantized DNN. Based on a bitwidth-weighted MAdds performance model, our approach achieves an average speedup of 1.26 and model size reduction of 0.53 compared to standard training in float32 with an average accuracy increase of 0.98% on AlexNet/ResNet on CIFAR10/100.