 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Driven Dubbing for User Generated Contents via Style-Aware Semi-Parametric Synthesis
Aug 31, 2023Existing automated dubbing methods are usually designed for Professionally Generated Content (PGC) production, which requires massive training data and training time to learn a person-specific audio-video mapping. In this paper, we investigate an audio-driven dubbing method that is more feasible for User Generated Content (UGC) production. There are two unique challenges to design a method for UGC: 1) the appearances of speakers are diverse and arbitrary as the method needs to generalize across users; 2) the available video data of one speaker are very limited. In order to tackle the above challenges, we first introduce a new Style Translation Network to integrate the speaking style of the target and the speaking content of the source via a cross-modal AdaIN module. It enables our model to quickly adapt to a new speaker. Then, we further develop a semi-parametric video renderer, which takes full advantage of the limited training data of the unseen speaker via a video-level retrieve-warp-refine pipeline. Finally, we propose a temporal regularization for the semi-parametric renderer, generating more continuous videos. Extensive experiments show that our method generates videos that accurately preserve various speaking styles, yet with considerably lower amount of training data and training time in comparison to existing methods. Besides, our method achieves a faster testing speed than most recent methods.
* TCSVT 2022
Everything's Talkin': Pareidolia Face Reenactment
Apr 07, 2021



We present a new application direction named Pareidolia Face Reenactment, which is defined as animating a static illusory face to move in tandem with a human face in the video. For the large differences between pareidolia face reenactment and traditional human face reenactment, two main challenges are introduced, i.e., shape variance and texture variance. In this work, we propose a novel Parametric Unsupervised Reenactment Algorithm to tackle these two challenges. Specifically, we propose to decompose the reenactment into three catenate processes: shape modeling, motion transfer and texture synthesis. With the decomposition, we introduce three crucial components, i.e., Parametric Shape Modeling, Expansionary Motion Transfer and Unsupervised Texture Synthesizer, to overcome the problems brought by the remarkably variances on pareidolia faces. Extensive experiments show the superior performance of our method both qualitatively and quantitatively. Code, model and data are available on our project page.
Everybody's Talkin': Let Me Talk as You Want
Jan 15, 2020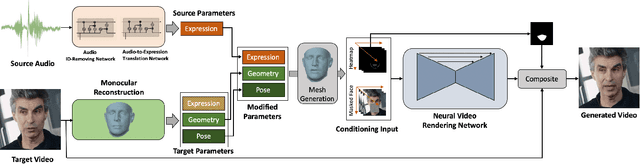
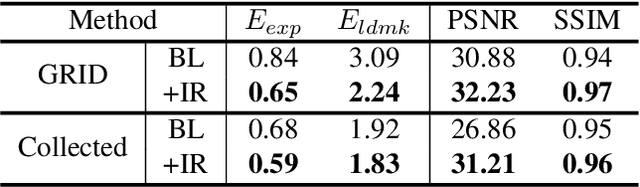
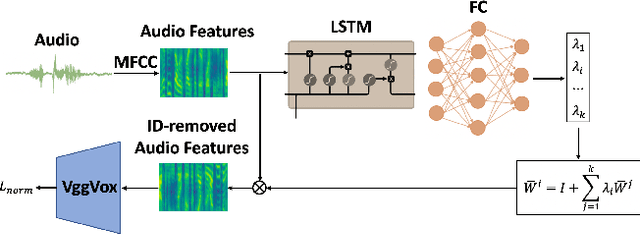

We present a method to edit a target portrait footage by taking a sequence of audio as input to synthesize a photo-realistic video. This method is unique because it is highly dynamic. It does not assume a person-specific rendering network yet capable of translating arbitrary source audio into arbitrary video output. Instead of learning a highly heterogeneous and nonlinear mapping from audio to the video directly, we first factorize each target video frame into orthogonal parameter spaces, i.e., expression, geometry, and pose, via monocular 3D face reconstruction. Next, a recurrent network is introduced to translate source audio into expression parameters that are primarily related to the audio content. The audio-translated expression parameters are then used to synthesize a photo-realistic human subject in each video frame, with the movement of the mouth regions precisely mapped to the source audio. The geometry and pose parameters of the target human portrait are retained, therefore preserving the context of the original video footage. Finally, we introduce a novel video rendering network and a dynamic programming method to construct a temporally coherent and photo-realistic video. Extensive experiments demonstrate the superiority of our method over existing approaches. Our method is end-to-end learnable and robust to voice variations in the source audio.
Geometry-Aware Face Completion and Editing
Sep 09, 2018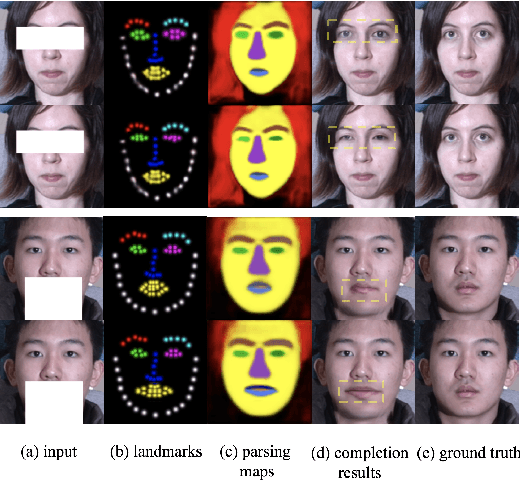
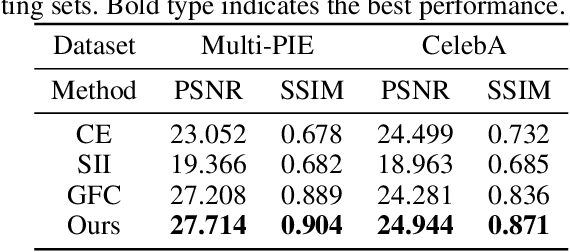
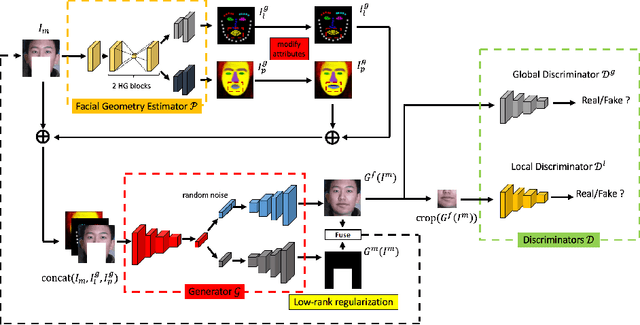
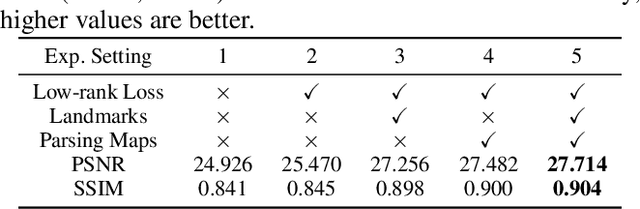
Face completion is a challenging generation task because it requires generating visually pleasing new pixels that are semantically consistent with the unmasked face region. This paper proposes a geometry-aware Face Completion and Editing NETwork (FCENet) by systematically studying facial geometry from the unmasked region. Firstly, a facial geometry estimator is learned to estimate facial landmark heatmaps and parsing maps from the unmasked face image. Then, an encoder-decoder structure generator serves to complete a face image and disentangle its mask areas conditioned on both the masked face image and the estimated facial geometry images. Besides, since low-rank property exists in manually labeled masks, a low-rank regularization term is imposed on the disentangled masks, enforcing our completion network to manage occlusion area with various shape and size. Furthermore, our network can generate diverse results from the same masked input by modifying estimated facial geometry, which provides a flexible mean to edit the completed face appearance. Extensive experimental results qualitatively and quantitatively demonstrate that our network is able to generate visually pleasing face completion results and edit face attributes as well.