 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP Based Region-Aware Feature Fusion for Automated BBPS Scoring in Colonoscopy Images
Dec 23, 2025Accurate assessment of bowel cleanliness is essential for effective colonoscopy procedures. The Boston Bowel Preparation Scale (BBPS) offers a standardized scoring system but suffers from subjectivity and inter-observer variability when performed manually. In this paper, to support robust training and evaluation, we construct a high-quality colonoscopy dataset comprising 2,240 images from 517 subjects, annotated with expert-agreed BBPS scores. We propose a novel automated BBPS scoring framework that leverages the CLIP model with adapter-based transfer learning and a dedicated fecal-feature extraction branch. Our method fuses global visual features with stool-related textual priors to improve the accuracy of bowel cleanliness evaluation without requiring explicit segmentation. Extensive experiments on both our dataset and the public NERTHU dataset demonstrate the superiority of our approach over existing baselines, highlighting its potential for clinical deployment in computer-aided colonoscopy analysis.
NTIRE 2025 Challenge on Cross-Domain Few-Shot Object Detection: Methods and Results
Apr 14, 2025Cross-Domain Few-Shot Object Detection (CD-FSOD) poses significant challenges to existing object detection and few-shot detection models when applied across domains. In conjunction with NTIRE 2025, we organized the 1st CD-FSOD Challenge, aiming to advance the performance of current object detectors on entirely novel target domains with only limited labeled data. The challenge attracted 152 registered participants, received submissions from 42 teams, and concluded with 13 teams making valid final submissions. Participants approached the task from diverse perspectives, proposing novel models that achieved new state-of-the-art (SOTA) results under both open-source and closed-source settings. In this report, we present an overview of the 1st NTIRE 2025 CD-FSOD Challenge, highlighting the proposed solutions and summarizing the results submitted by the participants.
Prompt as Free Lunch: Enhancing Diversity in Source-Free Cross-domain Few-shot Learning through Semantic-Guided Prompting
Dec 01, 2024



The source-free cross-domain few-shot learning (CD-FSL) task aims to transfer pretrained models to target domains utilizing minimal samples, eliminating the need for source domain data. Addressing this issue requires models to have robust generalization abilities and strong feature representation, aligning with the characteristics of large-scale pretrained models. However, large-scale models tend to lose representational ability in cross-domain scenarios due to limited sample diversity. \zlh{Given the abundant diversity provided by semantic modality, this paper leverages textual modality to enhance training sample diversity with CLP model}, meanwhile improving model transfer efficiency. Specifically, we propose the SeGD-VPT framework, which is divided into two phases. The first step aims to increase feature diversity by adding diversity prompts to each support sample, thereby generating varying input and enhancing sample diversity. Furthermore, we use diversity descriptions of classes to guide semantically meaningful learning of diversity prompts, proposing random combinations and selections of texts to increase textual diversity. Additionally, deep prompt tuning is introduced to enhance the model's transfer capability. After training of the first step, support samples with different diversity prompts are input into the CLIP backbone to generate enhanced features. After generation, the second phase trains classifiers using the generated features. Extensive experimental results across several benchmarks verify our method is comparable to SOTA source-utilized models and attain the best performance under the source-free CD-FSL setting.
NuScenes-QA: A Multi-modal Visual Question Answering Benchmark for Autonomous Driving Scenario
May 24, 2023We introduce a novel visual question answering (VQA) task in the context of autonomous driving, aiming to answer natural language questions based on street-view clues. Compared to traditional VQA tasks, VQA in autonomous driving scenario presents more challenges. Firstly, the raw visual data are multi-modal, including images and point clouds captured by camera and LiDAR, respectively. Secondly, the data are multi-frame due to the continuous, real-time acquisition. Thirdly, the outdoor scenes exhibit both moving foreground and static background. Existing VQA benchmarks fail to adequately address these complexities. To bridge this gap, we propose NuScenes-QA, the first benchmark for VQA in the autonomous driving scenario, encompassing 34K visual scenes and 460K question-answer pairs. Specifically, we leverage existing 3D detection annotations to generate scene graphs and design question templates manually. Subsequently, the question-answer pairs are generated programmatically based on these templates. Comprehensive statistics prove that our NuScenes-QA is a balanced large-scale benchmark with diverse question formats. Built upon it, we develop a series of baselines that employ advanced 3D detection and VQA techniques. Our extensive experiments highlight the challenges posed by this new task. Codes and dataset are available at https://github.com/qiantianwen/NuScenes-QA.
TGDM: Target Guided Dynamic Mixup for Cross-Domain Few-Shot Learning
Oct 11, 2022
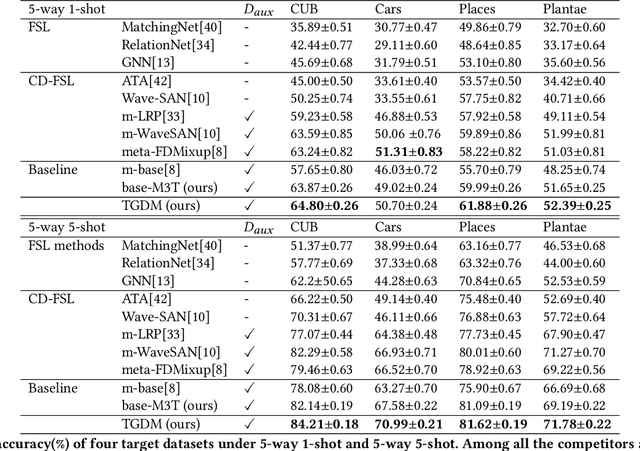


Given sufficient training data on the source domain, cross-domain few-shot learning (CD-FSL) aims at recognizing new classes with a small number of labeled examples on the target domain. The key to addressing CD-FSL is to narrow the domain gap and transferring knowledge of a network trained on the source domain to the target domain. To help knowledge transfer, this paper introduces an intermediate domain generated by mixing images in the source and the target domain. Specifically, to generate the optimal intermediate domain for different target data, we propose a novel target guided dynamic mixup (TGDM) framework that leverages the target data to guide the generation of mixed images via dynamic mixup. The proposed TGDM framework contains a Mixup-3T network for learning classifiers and a dynamic ratio generation network (DRGN) for learning the optimal mix ratio. To better transfer the knowledge, the proposed Mixup-3T network contains three branches with shared parameters for classifying classes in the source domain, target domain, and intermediate domain. To generate the optimal intermediate domain, the DRGN learns to generate an optimal mix ratio according to the performance on auxiliary target data. Then, the whole TGDM framework is trained via bi-level meta-learning so that TGDM can rectify itself to achieve optimal performance on target data. Extensive experimental results on several benchmark datasets verify the effectiveness of our method.