 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLCTables: A Dataset for Marrying Natural Language Conditions with Table Discovery
Apr 22, 2025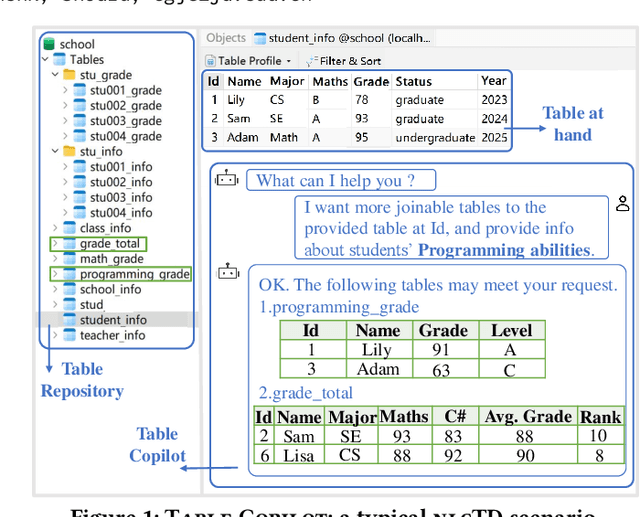
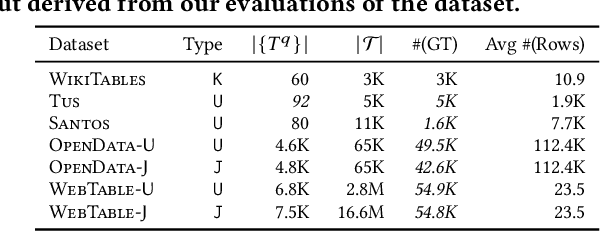
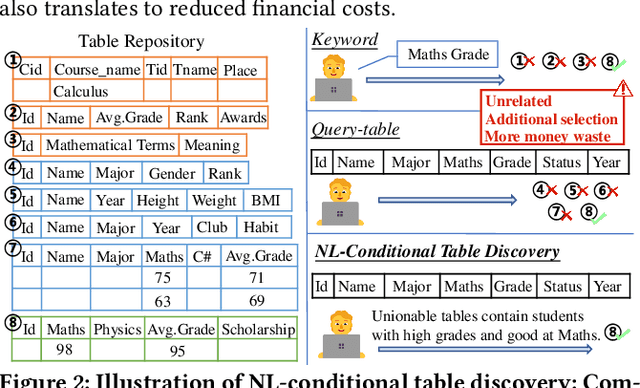

With the growing abundance of repositories containing tabular data, discovering relevant tables for in-depth analysis remains a challenging task. Existing table discovery methods primarily retrieve desired tables based on a query table or several vague keywords, leaving users to manually filter large result sets. To address this limitation, we propose a new task: NL-conditional table discovery (nlcTD), where users combine a query table with natural language (NL) requirements to refine search results. To advance research in this area, we present nlcTables, a comprehensive benchmark dataset comprising 627 diverse queries spanning NL-only, union, join, and fuzzy conditions, 22,080 candidate tables, and 21,200 relevance annotations. Our evaluation of six state-of-the-art table discovery methods on nlcTables reveals substantial performance gaps, highlighting the need for advanced techniques to tackle this challenging nlcTD scenario. The dataset, construction framework, and baseline implementations are publicly available at https://github.com/SuDIS-ZJU/nlcTables to foster future research.
Tabular Data Augmentation for Machine Learning: Progress and Prospects of Embracing Generative AI
Jul 31, 2024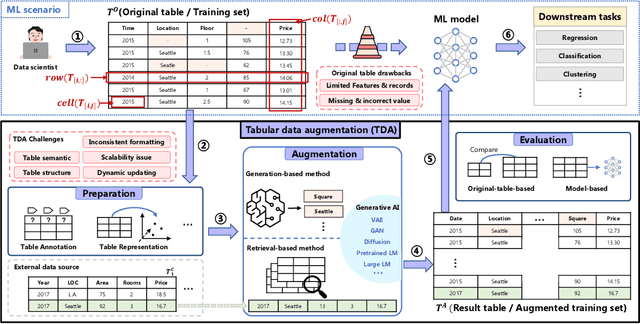
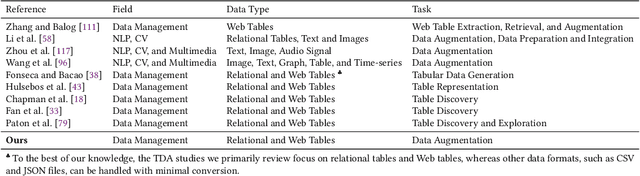
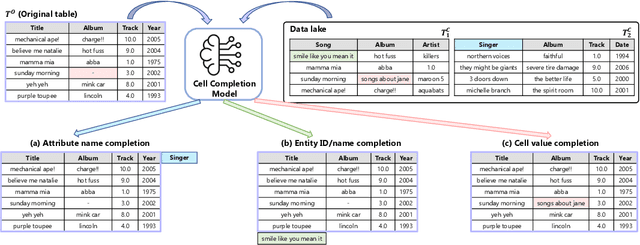
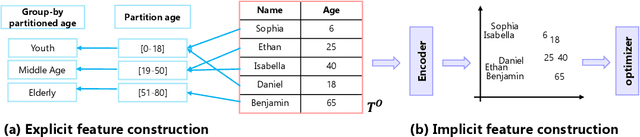
Machine learning (ML) on tabular data is ubiquitous, yet obtaining abundant high-quality tabular data for model training remains a significant obstacle. Numerous works have focused on tabular data augmentation (TDA) to enhance the original table with additional data, thereby improving downstream ML tasks. Recently, there has been a growing interest in leveraging the capabilities of generative AI for TDA. Therefore, we believe it is time to provide a comprehensive review of the progress and future prospects of TDA, with a particular emphasis on the trending generative AI. Specifically, we present an architectural view of the TDA pipeline, comprising three main procedures: pre-augmentation, augmentation, and post-augmentation. Pre-augmentation encompasses preparation tasks that facilitate subsequent TDA, including error handling, table annotation, table simplification, table representation, table indexing, table navigation, schema matching, and entity matching. Augmentation systematically analyzes current TDA methods, categorized into retrieval-based methods, which retrieve external data, and generation-based methods, which generate synthetic data. We further subdivide these methods based on the granularity of the augmentation process at the row, column, cell, and table levels. Post-augmentation focuses on the datasets, evaluation and optimization aspects of TDA. We also summarize current trends and future directions for TDA, highlighting promising opportunities in the era of generative AI. In addition, the accompanying papers and related resources are continuously updated and maintained in the GitHub repository at https://github.com/SuDIS-ZJU/awesome-tabular-data-augmentation to reflect ongoing advancements in the field.