 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-free non-ergodic extragradient algorithms for solving monotone variational inequalities
Apr 09, 2026Monotone variational inequalities (VIs) provide a unifying framework for convex minimization, equilibrium computation, and convex-concave saddle-point problems. Extragradient-type methods are among the most effective first-order algorithms for such problems, but their performance hinges critically on stepsize selection. While most existing theory focuses on ergodic averages of the iterates, practical performance is often driven by the significantly stronger behavior of the last iterate. Moreover, available last-iterate guarantees typically rely on fixed stepsizes chosen using problem-specific global smoothness information, which is often difficult to estimate accurately and may not even be applicable. In this paper, we develop parameter-free extragradient methods with non-asymptotic last-iterate guarantees for constrained monotone VIs. For globally Lipschitz operators, our algorithm achieves an $o(1/\sqrt{T})$ last-iterate rate. We then extend the framework to locally Lipschitz operators via backtracking line search and obtain the same rate while preserving parameter-freeness, thereby making parameter-free last-iterate methods applicable to important problem classes for which global smoothness is unrealistic. Our numerical experiments on bilinear matrix games, LASSO, minimax group fairness, and state-of-the-art maximum entropy sampling relaxations demonstrate wide applicability of our results as well as strong last-iterate performance and significant improvements over existing methods.
Mistake, Manipulation and Margin Guarantees in Online Strategic Classification
Mar 27, 2024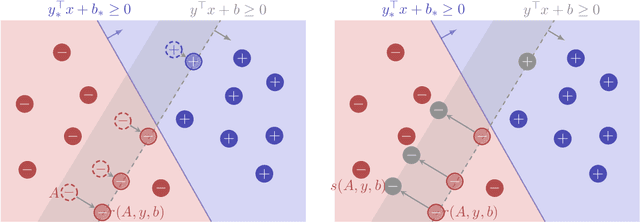
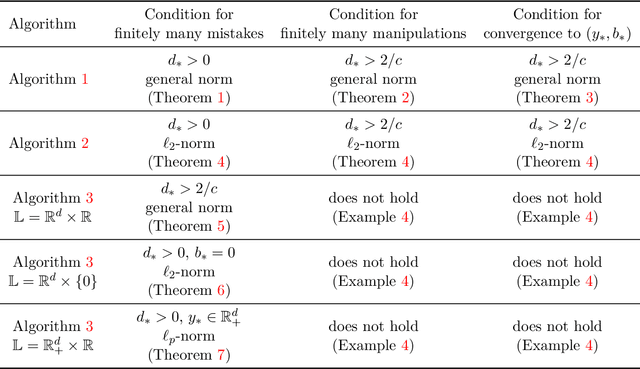
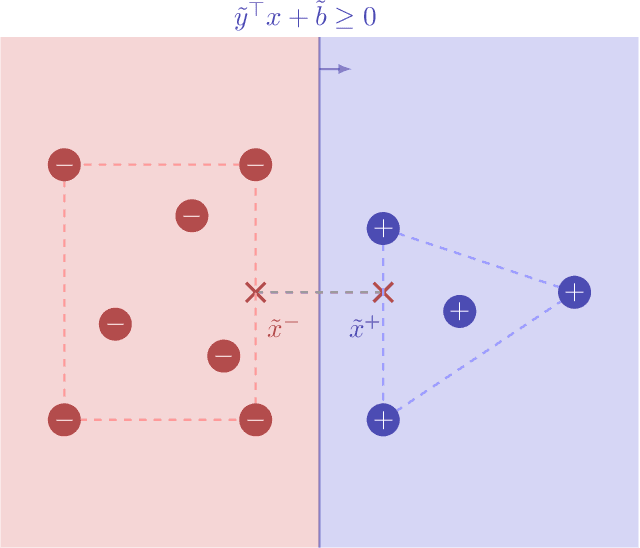
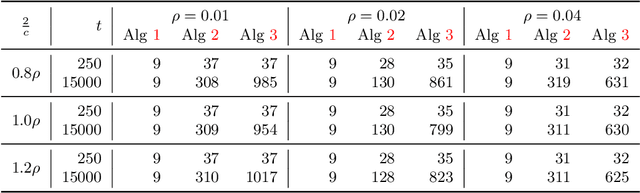
We consider an online strategic classification problem where each arriving agent can manipulate their true feature vector to obtain a positive predicted label, while incurring a cost that depends on the amount of manipulation. The learner seeks to predict the agent's true label given access to only the manipulated features. After the learner releases their prediction, the agent's true label is revealed. Previous algorithms such as the strategic perceptron guarantee finitely many mistakes under a margin assumption on agents' true feature vectors. However, these are not guaranteed to encourage agents to be truthful. Promoting truthfulness is intimately linked to obtaining adequate margin on the predictions, thus we provide two new algorithms aimed at recovering the maximum margin classifier in the presence of strategic agent behavior. We prove convergence, finite mistake and finite manipulation guarantees for a variety of agent cost structures. We also provide generalized versions of the strategic perceptron with mistake guarantees for different costs. Our numerical study on real and synthetic data demonstrates that the new algorithms outperform previous ones in terms of margin, number of manipulation and number of mistakes.
Non-asymptotic Results for Langevin Monte Carlo: Coordinate-wise and Black-box Sampling
Mar 14, 2019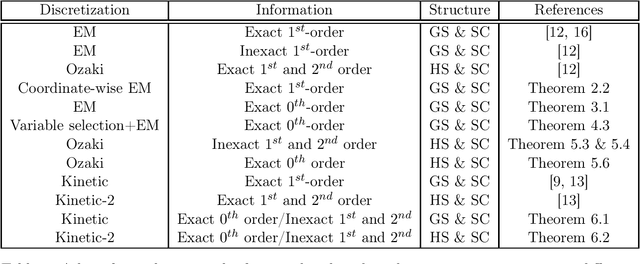
Discretization of continuous-time diffusion processes, using gradient and Hessian information, is a popular technique for sampling. For example, the Euler-Maruyama discretization of the Langevin diffusion process, called as Langevin Monte Carlo (LMC), is a canonical algorithm for sampling from strongly log-concave densities. In this work, we make several theoretical contributions to the literature on such sampling techniques. Specifically, we first provide a Randomized Coordinate-wise LMC algorithm suitable for large-scale sampling problems and provide a theoretical analysis. We next consider the case of zeroth-order or black-box sampling where one only obtains evaluates of the density. Based on Gaussian Stein's identities we then estimate the gradient and Hessian information and leverage it in the context of black-box sampling. We then provide a theoretical analysis of gradient and Hessian based discretizations of Langevin and kinetic Langevin diffusion processes for sampling, quantifying the non-asymptotic accuracy. We also consider high-dimensional black-box sampling under the assumption that the density depends only on a small subset of the entire coordinates. We propose a variable selection technique based on zeroth-order gradient estimates and establish its theoretical guarantees. Our theoretical contributions extend the practical applicability of sampling algorithms to the large-scale, black-box and high-dimensional settings.