 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes calibration mean what they say it means; or, the reference class problem rises again
Dec 21, 2024
Discussions of statistical criteria for fairness commonly convey the normative significance of calibration within groups by invoking what risk scores "mean." On the Same Meaning picture, group-calibrated scores "mean the same thing" (on average) across individuals from different groups and accordingly, guard against disparate treatment of individuals based on group membership. My contention is that calibration guarantees no such thing. Since concrete actual people belong to many groups, calibration cannot ensure the kind of consistent score interpretation that the Same Meaning picture implies matters for fairness, unless calibration is met within every group to which an individual belongs. Alas only perfect predictors may meet this bar. The Same Meaning picture thus commits a reference class fallacy by inferring from calibration within some group to the "meaning" or evidential value of an individual's score, because they are a member of that group. Furthermore, the reference class answer it presumes is almost surely wrong. I then show that the reference class problem besets not just calibration but all group statistical facts that claim a close connection to fairness. Reflecting on the origins of this error opens a wider lens onto the predominant methodology in algorithmic fairness based on stylized cases.
Convolutional LSTM Neural Networks for Modeling Wildland Fire Dynamics
Dec 11, 2020
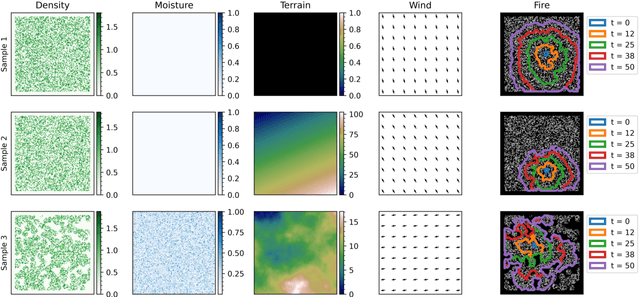
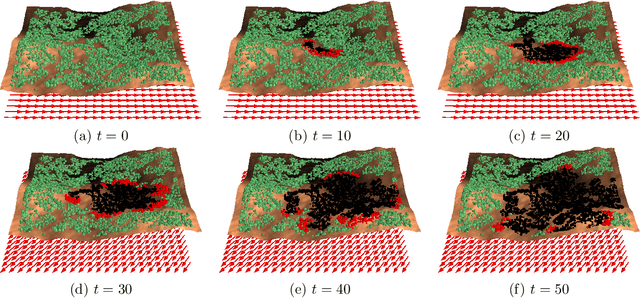

As the climate changes, the severity of wildland fires is expected to worsen. Understanding, controlling and mitigating these fires requires building models to accurately capture the fire-propagation dynamics. Supervised machine learning techniques provide a potential approach for developing such models. The objective of this study is to evaluate the feasibility of using the Convolutional Long Short-Term Memory (ConvLSTM) recurrent neural network (RNN) to model the dynamics of wildland fire propagation. The model is trained on simulated wildfire data generated by a cellular automaton percolation model. Four simulated datasets are analyzed, each with increasing degrees of complexity. The simplest dataset includes a constant wind direction as a single confounding factor, whereas the most complex dataset includes dynamic wind, complex terrain, spatially varying moisture content and realistic vegetation density distributions. We examine how effectively the ConvLSTM can capture the fire-spread dynamics over consecutive time steps using classification and regression metrics. It is shown that these ConvLSTMs are capable of capturing local fire transmission events, as well as the overall fire dynamics, such as the rate at which the fire spreads. Finally, we demonstrate that ConvLSTMs outperform non-temporal Convolutional Neural Networks(CNNs), particularly on the most difficult dataset.
What's Sex Got To Do With Fair Machine Learning?
Jun 04, 2020Debate about fairness in machine learning has largely centered around competing definitions of what fairness or nondiscrimination between groups requires. However, little attention has been paid to what precisely a group is. Many recent approaches to "fairness" require one to specify a causal model of the data generating process. These exercises make an implicit ontological assumption that a racial or sex group is simply a collection of individuals who share a given trait. We show this by exploring the formal assumption of modularity in causal models, which holds that the dependencies captured by one causal pathway are invariant to interventions on any other pathways. Causal models of sex propose two substantive claims: 1) There exists a feature, sex-on-its-own, that is an inherent trait of an individual that causally brings about social phenomena external to it in the world; and 2) the relations between sex and its effects can be modified in whichever ways and the former feature would still retain the meaning that sex has in our world. We argue that this ontological picture is false. Many of the "effects" that sex purportedly "causes" are in fact constitutive features of sex as a social status. They give the social meaning of sex features, meanings that are precisely what make sex discrimination a distinctively morally problematic type of action. Correcting this conceptual error has a number of implications for how models can be used to detect discrimination. Formal diagrams of constitutive relations present an entirely different path toward reasoning about discrimination. Whereas causal diagrams guide the construction of sophisticated modular counterfactuals, constitutive diagrams identify a different kind of counterfactual as central to an inquiry on discrimination: one that asks how the social meaning of a group would be changed if its non-modular features were altered.
Fair Classification and Social Welfare
May 01, 2019
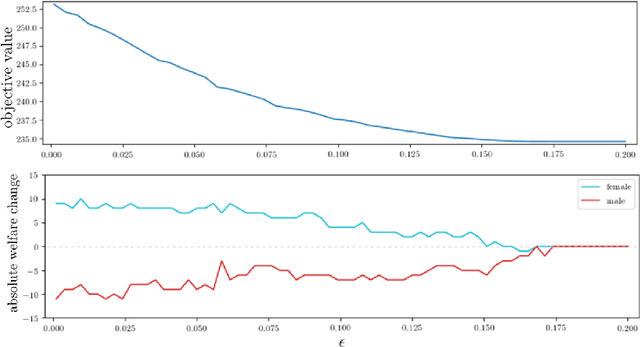
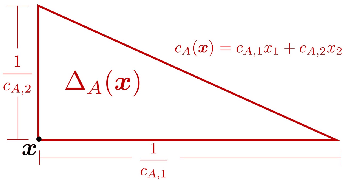
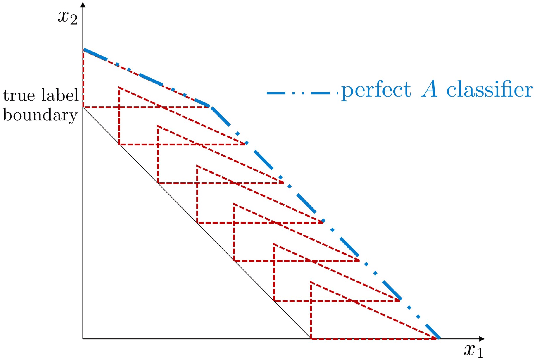
Now that machine learning algorithms lie at the center of many resource allocation pipelines, computer scientists have been unwittingly cast as partial social planners. Given this state of affairs, important questions follow. What is the relationship between fairness as defined by computer scientists and notions of social welfare? In this paper, we present a welfare-based analysis of classification and fairness regimes. We translate a loss minimization program into a social welfare maximization problem with a set of implied welfare weights on individuals and groups--weights that can be analyzed from a distribution justice lens. In the converse direction, we ask what the space of possible labelings is for a given dataset and hypothesis class. We provide an algorithm that answers this question with respect to linear hyperplanes in $\mathbb{R}^d$ that runs in $O(n^dd)$. Our main findings on the relationship between fairness criteria and welfare center on sensitivity analyses of fairness-constrained empirical risk minimization programs. We characterize the ranges of $\Delta \epsilon$ perturbations to a fairness parameter $\epsilon$ that yield better, worse, and neutral outcomes in utility for individuals and by extension, groups. We show that applying more strict fairness criteria that are codified as parity constraints, can worsen welfare outcomes for both groups. More generally, always preferring "more fair" classifiers does not abide by the Pareto Principle---a fundamental axiom of social choice theory and welfare economics. Recent work in machine learning has rallied around these notions of fairness as critical to ensuring that algorithmic systems do not have disparate negative impact on disadvantaged social groups. By showing that these constraints often fail to translate into improved outcomes for these groups, we cast doubt on their effectiveness as a means to ensure justice.
The Disparate Effects of Strategic Manipulation
Aug 28, 2018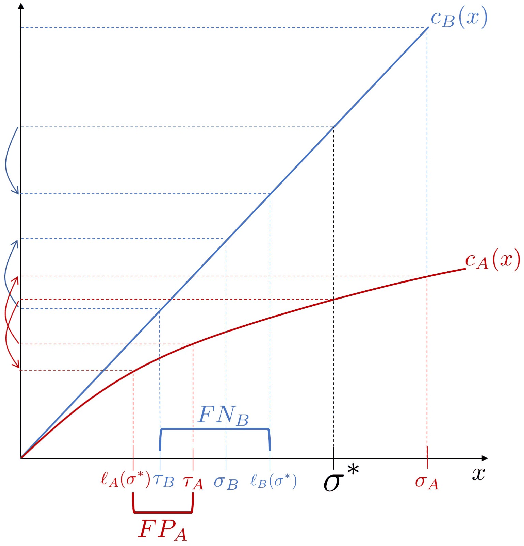
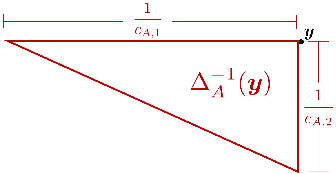
When consequential decisions are informed by algorithmic input, individuals may feel compelled to alter their behavior in order to gain a system's approval. Previous models of agent responsiveness, termed "strategic manipulation," have analyzed the interaction between a learner and agents in a world where all agents are equally able to manipulate their features in an attempt to "trick" a published classifier. In cases of real world classification, however, an agent's ability to adapt to an algorithm, is not simply a function of her personal interest in receiving a positive classification, but is bound up in a complex web of social factors that affect her ability to pursue certain action responses. In this paper, we adapt models of strategic manipulation to better capture dynamics that may arise in a setting of social inequality wherein candidate groups face different costs to manipulation. We find that whenever one group's costs are higher than the other's, the learner's equilibrium strategy exhibits an inequality-reinforcing phenomenon wherein the learner erroneously admits some members of the advantaged group, while erroneously excluding some members of the disadvantaged group. We also consider the effects of potential interventions in which a learner can subsidize members of the disadvantaged group, lowering their costs in order to improve her own classification performance. Here we encounter a paradoxical result: there exist cases in which providing a subsidy improves only the learner's utility while actually making both candidate groups worse-off--even the group receiving the subsidy. Our results reveal the potentially adverse social ramifications of deploying tools that attempt to evaluate an individual's "quality" when agents' capacities to adaptively respond differ.
Welfare and Distributional Impacts of Fair Classification
Jul 03, 2018Current methodologies in machine learning analyze the effects of various statistical parity notions of fairness primarily in light of their impacts on predictive accuracy and vendor utility loss. In this paper, we propose a new framework for interpreting the effects of fairness criteria by converting the constrained loss minimization problem into a social welfare maximization problem. This translation moves a classifier and its output into utility space where individuals, groups, and society at-large experience different welfare changes due to classification assignments. Under this characterization, predictions and fairness constraints are seen as shaping societal welfare and distribution and revealing individuals' implied welfare weights in society--weights that may then be interpreted through a fairness lens. The social welfare formulation of the fairness problem brings to the fore concerns of distributive justice that have always had a central albeit more implicit role in standard algorithmic fairness approaches.