 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Classification and Social Welfare
Paper and Code
May 01, 2019
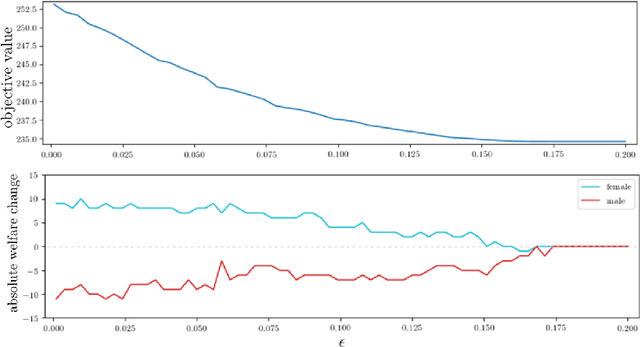
Now that machine learning algorithms lie at the center of many resource allocation pipelines, computer scientists have been unwittingly cast as partial social planners. Given this state of affairs, important questions follow. What is the relationship between fairness as defined by computer scientists and notions of social welfare? In this paper, we present a welfare-based analysis of classification and fairness regimes. We translate a loss minimization program into a social welfare maximization problem with a set of implied welfare weights on individuals and groups--weights that can be analyzed from a distribution justice lens. In the converse direction, we ask what the space of possible labelings is for a given dataset and hypothesis class. We provide an algorithm that answers this question with respect to linear hyperplanes in $\mathbb{R}^d$ that runs in $O(n^dd)$. Our main findings on the relationship between fairness criteria and welfare center on sensitivity analyses of fairness-constrained empirical risk minimization programs. We characterize the ranges of $\Delta \epsilon$ perturbations to a fairness parameter $\epsilon$ that yield better, worse, and neutral outcomes in utility for individuals and by extension, groups. We show that applying more strict fairness criteria that are codified as parity constraints, can worsen welfare outcomes for both groups. More generally, always preferring "more fair" classifiers does not abide by the Pareto Principle---a fundamental axiom of social choice theory and welfare economics. Recent work in machine learning has rallied around these notions of fairness as critical to ensuring that algorithmic systems do not have disparate negative impact on disadvantaged social groups. By showing that these constraints often fail to translate into improved outcomes for these groups, we cast doubt on their effectiveness as a means to ensure justice.