 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping Personalized Models of Blood Pressure Estimation from Wearable Sensors Data Using Minimally-trained Domain Adversarial Neural Networks
Jul 24, 2020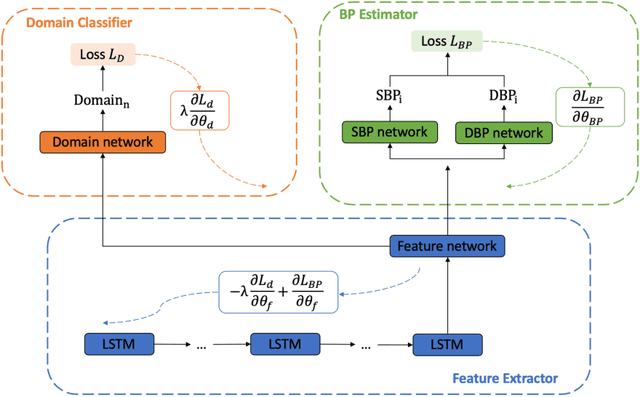
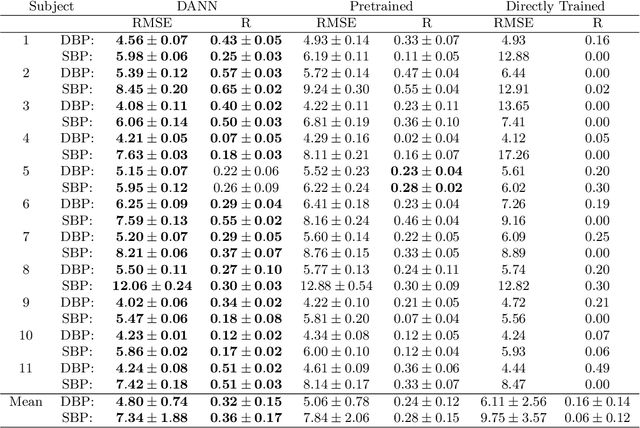
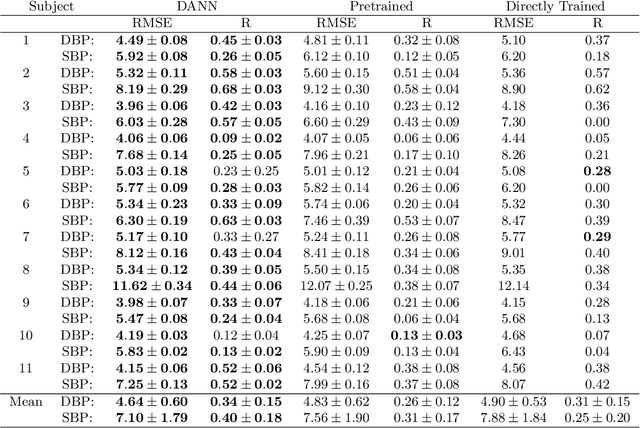
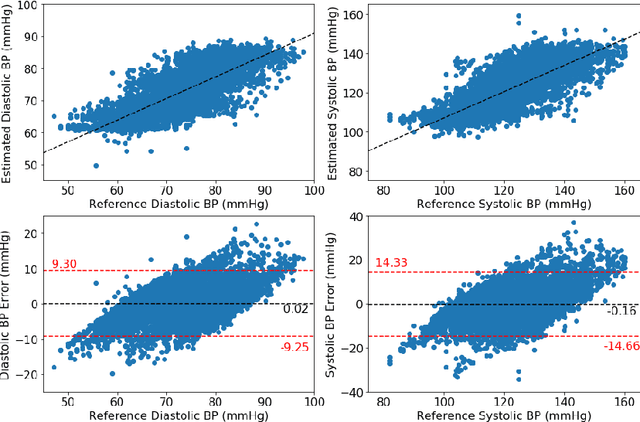
Blood pressure monitoring is an essential component of hypertension management and in the prediction of associated comorbidities. Blood pressure is a dynamic vital sign with frequent changes throughout a given day. Capturing blood pressure remotely and frequently (also known as ambulatory blood pressure monitoring) has traditionally been achieved by measuring blood pressure at discrete intervals using an inflatable cuff. However, there is growing interest in developing a cuffless ambulatory blood pressure monitoring system to measure blood pressure continuously. One such approach is by utilizing bioimpedance sensors to build regression models. A practical problem with this approach is that the amount of data required to confidently train such a regression model can be prohibitive. In this paper, we propose the application of the domain-adversarial training neural network (DANN) method on our multitask learning (MTL) blood pressure estimation model, allowing for knowledge transfer between subjects. Our proposed model obtains average root mean square error (RMSE) of $4.80 \pm 0.74$ mmHg for diastolic blood pressure and $7.34 \pm 1.88$ mmHg for systolic blood pressure when using three minutes of training data, $4.64 \pm 0.60$ mmHg and $7.10 \pm 1.79$ respectively when using four minutes of training data, and $4.48 \pm 0.57$ mmHg and $6.79 \pm 1.70$ respectively when using five minutes of training data. DANN improves training with minimal data in comparison to both directly training and to training with a pretrained model from another subject, decreasing RMSE by $0.19$ to $0.26$ mmHg (diastolic) and by $0.46$ to $0.67$ mmHg (systolic) in comparison to the best baseline models. We observe that four minutes of training data is the minimum requirement for our framework to exceed ISO standards within this cohort of patients.
Keyword-based Topic Modeling and Keyword Selection
Jan 22, 2020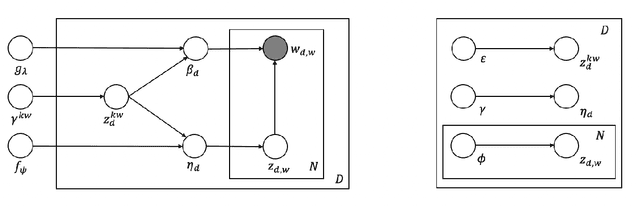
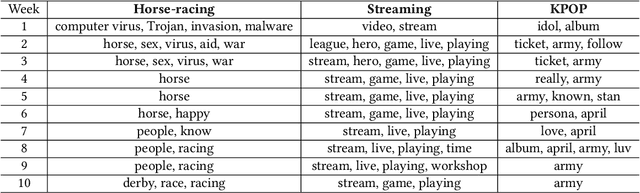

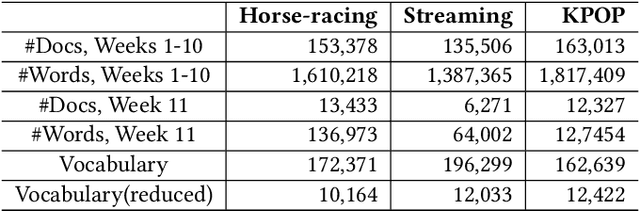
Certain type of documents such as tweets are collected by specifying a set of keywords. As topics of interest change with time it is beneficial to adjust keywords dynamically. The challenge is that these need to be specified ahead of knowing the forthcoming documents and the underlying topics. The future topics should mimic past topics of interest yet there should be some novelty in them. We develop a keyword-based topic model that dynamically selects a subset of keywords to be used to collect future documents. The generative process first selects keywords and then the underlying documents based on the specified keywords. The model is trained by using a variational lower bound and stochastic gradient optimization. The inference consists of finding a subset of keywords where given a subset the model predicts the underlying topic-word matrix for the unknown forthcoming documents. We compare the keyword topic model against a benchmark model using viral predictions of tweets combined with a topic model. The keyword-based topic model outperforms this sophisticated baseline model by 67%.
Layer Flexible Adaptive Computational Time for Recurrent Neural Networks
Dec 14, 2018



Deep recurrent neural networks perform well on sequence data and are the model of choice. It is a daunting task to decide the number of layers, especially considering different computational needs for tasks within a sequence of different difficulties. We propose a layer flexible recurrent neural network with adaptive computational time, and expand it to a sequence to sequence model. Contrary to the adaptive computational time model, our model has a dynamic number of transmission states which vary by step and sequence. We evaluate the model on a financial dataset. Experimental results show the performance improvement and indicate the model's ability to dynamically change the number of layers.